Считаем комбинации мозаик при помощи APL
6 мин
Перевод
Это короткая статья о том, как я воспользовался APL для проверки своих комбинаторных вычислений.
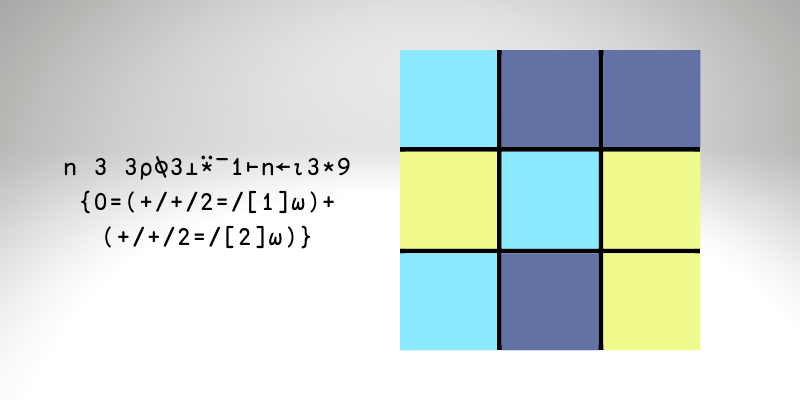
Наш местный университет проводит еженедельные соревнования по математическим задачам, которые может решать любой. На прошлой неделе задача относилась к комбинаторике и звучала следующим образом:
«Есть сетка 3 на 3 из квадратов, образующая мозаику. Сколькими способами мы можем раскрасить эту мозаику, если у нас есть 3 цвета и соседние квадраты не могут быть одного цвета?»
Под «соседними» понимаются соседние по вертикали или горизонтали. Авторы задачи дали подсказку (если не хотите спойлеров, то сразу переходите к следующему разделу!):
Комбинаторика никогда не была моей сильной стороной, но я хотел решить эту задачу. Я сел и начал прикидывать решение.
Завершив вычисления, я решил быстренько проверить своё решение при помощи APL — очень милого языка программирования, который я изучал в течение последних двух лет.
Это статья о том, как я за 30 секунд проверил на APL своё решение задачи.
Преамбула
Наш местный университет проводит еженедельные соревнования по математическим задачам, которые может решать любой. На прошлой неделе задача относилась к комбинаторике и звучала следующим образом:
«Есть сетка 3 на 3 из квадратов, образующая мозаику. Сколькими способами мы можем раскрасить эту мозаику, если у нас есть 3 цвета и соседние квадраты не могут быть одного цвета?»
Под «соседними» понимаются соседние по вертикали или горизонтали. Авторы задачи дали подсказку (если не хотите спойлеров, то сразу переходите к следующему разделу!):
Подсказка
«Пронумеруйте квадраты от 1 до 9, а затем поработайте с цветами чётных квадратов. Это позволит определить цвета нечётных квадратов».
Комбинаторика никогда не была моей сильной стороной, но я хотел решить эту задачу. Я сел и начал прикидывать решение.
Завершив вычисления, я решил быстренько проверить своё решение при помощи APL — очень милого языка программирования, который я изучал в течение последних двух лет.
Это статья о том, как я за 30 секунд проверил на APL своё решение задачи.
- Я начну с демонстрации моего ошибочного доказательства (в том виде, в котором я его записал);
- Затем я расскажу, что сделал на APL, чтобы проверить своё решение;
- Далее я покажу свою исходную ошибку, и наконец
- Я ещё немного поработаю с кодом на APL, чтобы сделать его чище.