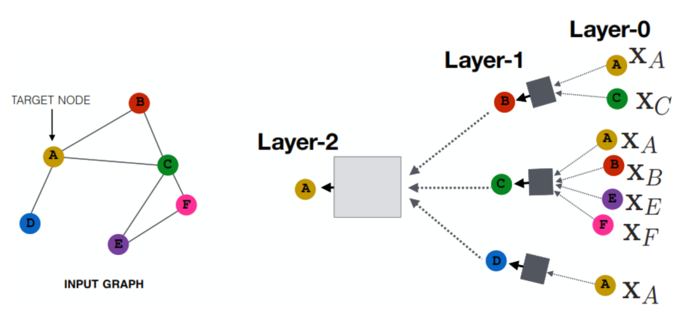
«Швейцарский нож» науки: как методы Computer Science используются в других дисциплинах
9 мин

Математику часто называют «языком науки». Она хорошо приспособлена для количественной обработки практически любой научной информации, независимо от ее содержания. А при помощи математического формализма ученые из разных областей могут в какой-то степени «понимать» друг друга. Сегодня похожая ситуация складывается с Computer Science. Но если математика — это язык науки, то CS — её швейцарский нож. Действительно, трудно представить современные исследования без анализа и обработки огромных объемов данных, сложных вычислений, компьютерного моделирования, визуализации, применения специального ПО и алгоритмов. Разберем несколько интересных «сюжетов», когда разные дисциплины используют методы CS для решения своих задач.
Биоинформатика: от чашек Петри к биологии In silico
Биоинформатику можно назвать одним из самых ярких примеров стыка CS и других дисциплин. Эта наука занимается анализом молекулярно-биологических данных при помощи компьютерных методов. Биоинформатика как отдельное научное направление появилась в начале 70-х годов прошлого века, когда впервые были опубликованы нуклеотидные последовательности малых РНК и созданы алгоритмы предсказания их вторичной структуры (пространственного расположения атомов в молекуле).
С проекта «Геном человека» по определению последовательности нуклеотидов в ДНК человека и идентификации генов в геноме началась новая эра биоинформатики. Стоимость секвенирования ДНК (определение последовательности нуклеотидов) упала на несколько порядков. Это привело к колоссальному увеличению числа последовательностей в публичных базах данных. На графике ниже изображен рост количества последовательностей в публичной базе данных GenBank с декабря 1982 года по февраль 2017 в полулогарифмическом масштабе. Чтобы накопленные данные стали полезными их нужно каким-то образом проанализировать.

 -битный счётчик позволяет учесть не более
-битный счётчик позволяет учесть не более  событий.
событий.







 . Их линейной комбинацией называется выражение вида
. Их линейной комбинацией называется выражение вида  , представляющее собой сумму произведений векторов на коэффициенты
, представляющее собой сумму произведений векторов на коэффициенты  .
.