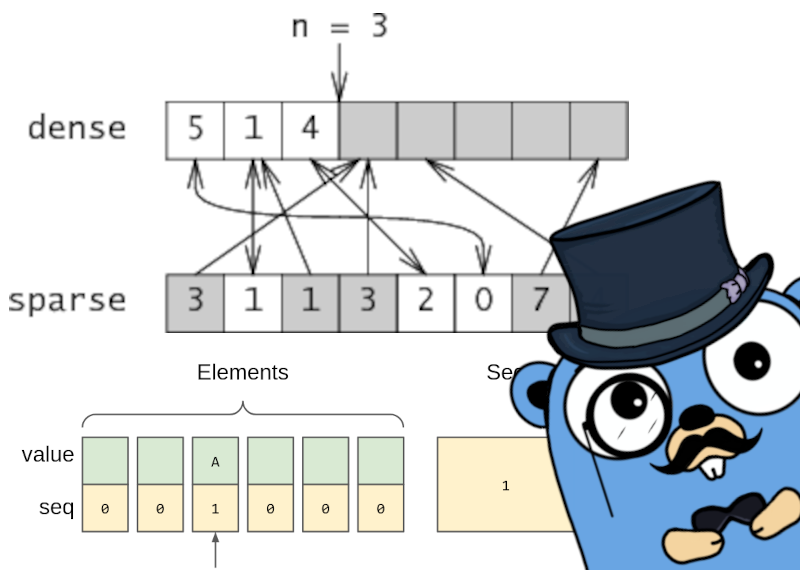
В борьбе со сложностью, или Как обуздать лог-линейный алгоритм (со ссылкой на код)

В этой статье я расскажу об алгоритме, который помогает нам решить задачу дедупликации данных без идентификатора, дам контекст решаемой проблемы и словесное описание алгоритма с визуализацией. Реализацию алгоритма можно посмотреть по ссылке в заключении.
Алгоритм решает простую задачу. Он объединяет персональные данные из разных систем и получает на выходе «золотую запись». Делает он это в батчёвом и транзакционом режимах с приемлемой вычислительной сложностью, несмотря на принадлежность к формальному классу комбинаторных алгоритмов.
«Золотая запись» выступает в дальнейшей цепочке обработки данных в качестве уникального ключа. Это позволяет решить на масштабах компании задачу сопоставления ранее несвязанных событий, что даёт профит бизнесу как напрямую (через лучшее понимание клиентского пути), так и опосредованно через лучшую организацию аналитики и выстраивание предиктивных моделей.