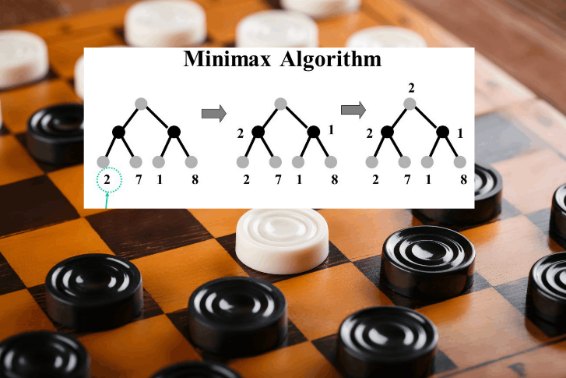
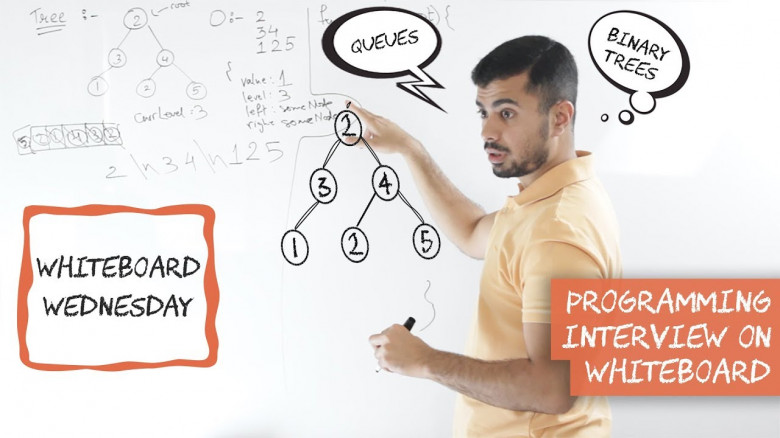
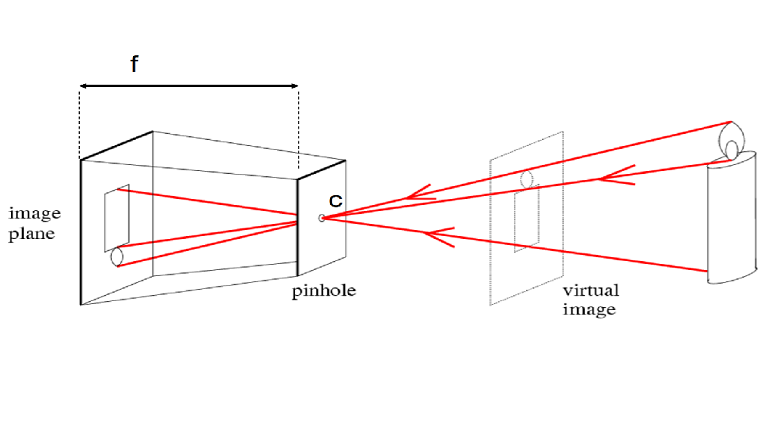
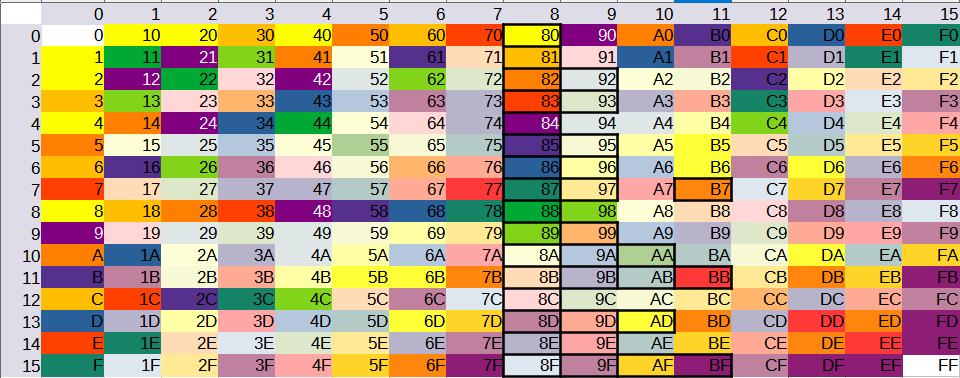
С наступающим наступившим вновь наступающим, Хабр.
Новый год – точка, после которой все мы собираемся что-то начать, чем-то заняться, в чём-то поднатореть. Сегодня я расскажу об одном из таких вариантов – что можно начать и как к этому подойти.
Конечно, про литкод все слышали и, казалось бы, о чём тут рассказывать? Ну задачник, перед техсобесами можно открыть на день-два. Но для того рассказать и стоит, дабы чуть разбавить это мнение.
С сайтом несколько больно знакомиться, он отпугивает вездесущими приписками "premium", пользуясь славой ресурса для техсобесов продвигает функционал вроде списков компаний, где встречался вопрос n и симуляции интервью в компанию m, да и сам не особо стремится рассказать о себе, потому в нём зачастую и видно голый задачник с одной страницей "problems".
За всем этим теряется важный пункт – а можно ли использовать сайт не для механического зазубривания популярных вопрос-ответов, а для изучения/закрепления алгоритмов и структур данных? Можно. Но подход к этому нужно формировать самостоятельно.