

Алгоритмы и рыбалка: как работает мозг программиста в естественной среде обитания

Привет, меня зовут Валерий Антонов, я руковожу направлением Java в Уральском банке реконструкции и развития (УБРиР). Сегодня расскажу, как я смог переложить систему алгоритмов на, казалось бы никак с этим не связанное хобби, - рыбалку.
Загадки быстрого преобразования Фурье
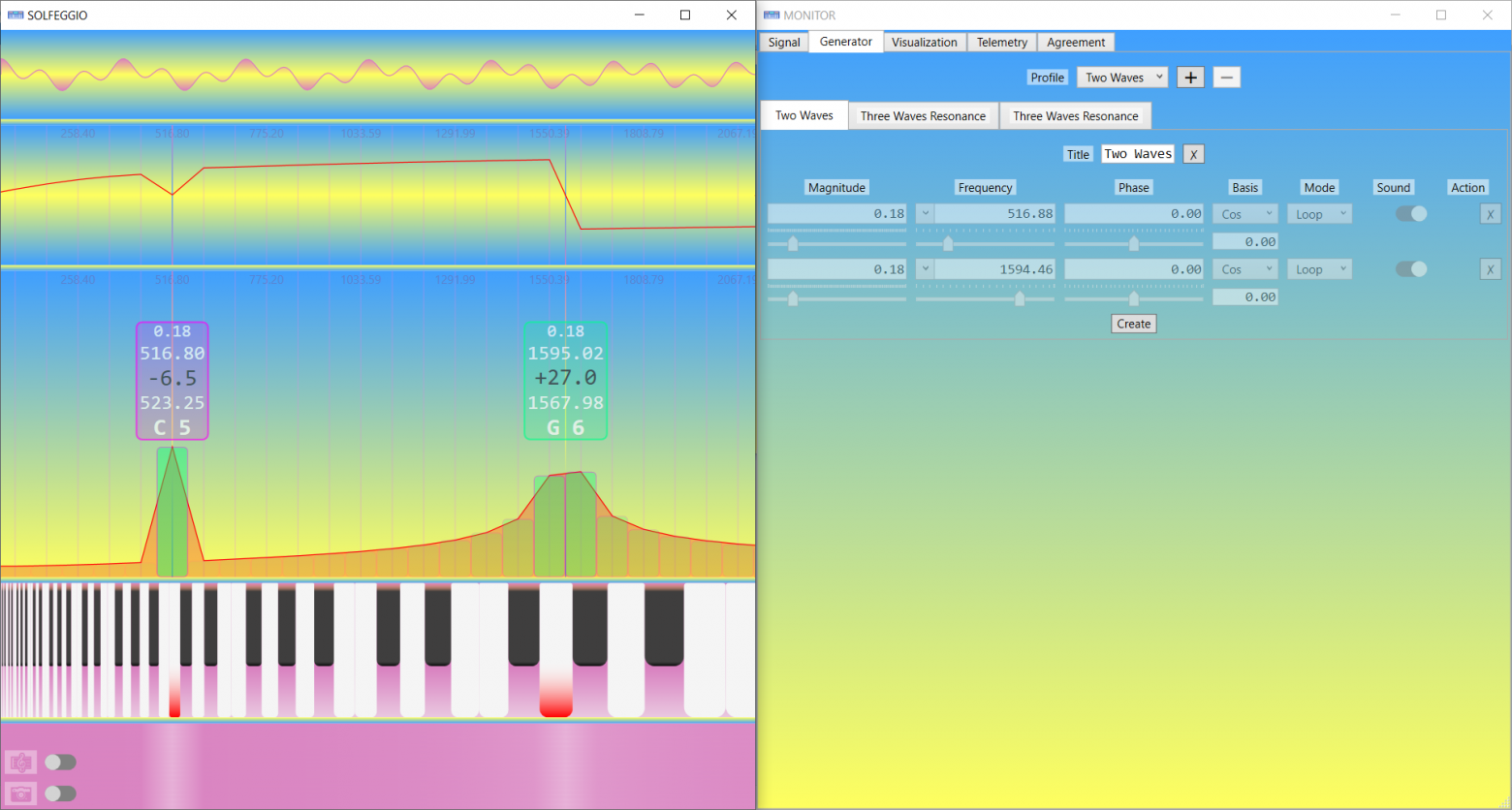
• Метод фазово-амплитудной интерполяции (ФАИ)
• Точное определение частоты, амплитуды и фазы гармоник сигнала
Алгоритм быстрого преобразования Фурье (БПФ) - важный инструмент для анализа и обработки сигналов различной природы.
Он позволяет реконструировать амплитудный и фазовый спектры сигнала в частотной области представления по его амплитудным отсчётам во временной, при этом метод вычислительно оптимизированный при скромном расходе памяти.
Хотя в процессе преобразования никакая информация о сигнале не утрачивается (вычисления обратимы до округлений) алгоритму присущи некоторые особенности, которые затрудняют высокоточный анализ и тонкую обработку результатов в дальнейшем.
В статье представлен действенный способ преодоления таких "неудобных" особенностей алгоритма.
Экономическая модель для ММО

Некоторые соображения о том, как концептуально может быть устроена идеализированная экономика обмена в ммо-игре.
Обработка данных криптовалютного рынка в RavenDB с использованием временных рядов
RavenDB — это документо-ориентированная NoSQL-база данных, оснащённая стандартной поддержкой работы с временными рядами. То есть — получается нечто вроде MongoDB со встроенной InfluxDB. Это позволяет применять RavenDB для хранения и обработки данных, получаемых с финансовых рынков. В частности — строить графики цены Bitcoin с использованием C# и TypeScript.
Вот 5-минутное видео, в котором приведено сравнение поддержки временных рядов в RavenDB с их поддержкой в других подобных системах.
В этом видео идёт речь об интересных рыночных данных и о построении ценовых графиков по образцу популярного приложения для трейдинга, разработанного компанией Robinhood. Данный материал посвящён разбору демонстрационного приложения. Когда вы его освоите, вы должны получить представление о том, как работать с временными рядами в RavenDB.
Азбука блокчейна: протоколы и алгоритмы консенсуса
Всем привет! Для тех, кто уже читал мои посты о блокчейне хочу сказать, что рад вас видеть снова на своей странице. Для тех, с кем мы еще не знакомы, меня зовут Валерий, я junior developer в западном стартапе, приятно познакомиться.
Я как-то уже писал о том, что мы собираем свою “Википедию” о технологиях на крипторынке. Сейчас мой фокус внимания смещен на все составляющие блокчейна, я продвигаюсь снизу вверх, чтобы лучше понять, как это все работает. И вот мне в связи с работой постоянно попадались некоторые обозначения, которые мне поначалу казались синонимами.
Речь идет о протоколах или алгоритмах консенсуса, на которых, собственно, и работает блокчейн. Но этим все не ограничивается, с этими протоколами связано немало терминов, объясняющих их работу. Честно говоря, чтобы изучить протоколы и их составляющие, я потратил довольно много времени и прошерстил немало ресурсов. И я подумал, что добру зря пропадать и решил сделать новую публикацию с моим исследованием.
Сага о моделировании бизнес-процессов на базе конечного автомата (fsm)
Про конечные автоматы (finite state machine, fsm) много кто слышал, но используют их явно в реальных проектах редко. Чаще встречаются конструкции, которые поведением напоминают КА, но ими не являются.
Почему же автоматы обходят стороной и/или изобретают велосипеды, превращая код в спагетти?
По-моему, тут дело в стереотипе: мол, автоматы — это что-то сложное из теоретической математики и к реальной жизни не относится. А применять их можно только в лексических анализаторах или еще чем-нибудь специфичном.
На самом деле, область применения КА куда шире и понятнее. Давайте разберем на примере автоматизации процессов в любимом кровавом enterprise.

Асинхронная обработка данных (асинхронные вычисления). Анализ поведения
Однако различие меду синхронными и асинхронными схемами носит более существенный характер. Синхронные схемы отличаются наличием временных интервалов, маскируемых тактовым сигналом. И эти временные интервалы включают все переходные процессы. То есть синхронные схемы не рассматривают переходные процессы и имеют дело только с результатами переходных процессов. Таким образом синхронная схема по сути представляет собой причинно-следственные отношения на множестве состояний. Асинхронные же схемы рассматривают как результат переходного процесса, так и сам процесс. Говорить в этом случае о состояниях можно лишь с большой долей условности. Переходный процесс и его результат описываются таким явлением, как событие (переключение сигнала). И асинхронная схема представляет собой те же причинно-следственные отношения только на множестве событий.
Как написать решатель «Пятнашек» на C#

Цель этой статьи — пробудить интерес читателей к удивительному миру и показать различные способы решения таких же интересных головоломок, как «Пятнашки». Создайте свою базу данных с шаблонами и начните решать головоломки менее чем за 50 миллисекунд. Материалом делимся к старту курса по разработке на C#.
Проверка ценников в магазине с помощью YOLOv4-Tiny+EasyOCR

Привет всем читателям Хабра! Нас зовут Сергей и Павел, мы студенты Томского государственного университета систем управления и радиоэлектроники (ТУСУР). В прошлом году мы победили в треке “Искусственный интеллект” IV Межвузовского конкурса выпускных проектов «IT Академии Samsung». Там мы представили проект, использующий нейронные сети для анализа информации на ценниках.
Мы распознавали ценники сети магазинов “Лента” при помощи нейронных сетей для сегментации и OCR и теперь хотим рассказать о том, как проходила работа над проектом и что мы узнали за это время.
N (Насти) алгоритм
Памяти Насти. Памяти дочери.
Что знаем об алгоритмах поиска? Есть граф. Чаще ориентированный. И некое целевое состояние. Фиксированное. А если нет?
Как, например, найти ребенка, который потерялся в лесу? Ведь не только вы его будете искать, но и он вас.
Передвигаться случайно? Да. Но еще лучше выбирать те направления, где меньше всего были. Есть дополнительные признаки, например следы? Отлично. В первую очередь ориентируемся на них. Потерялись следы? Вновь возвращаемся к поиску с учетом только памяти.
Создание APP для самотестирования (Python)

Недавно от знакомых прилетела задачка написать программу для самотестирования. Порылся в инете, думал в лёгкую найду наработки, но ничего кроме платных и бесплатных конструкторов тестов не нашёл (может плохо искал, кто знает…). Мне показалось, что устанавливать какие-то инородные проги, а потом ещё туда все вопросы ручками забивать - совсем некрасиво. Так родилось приложение для самотестирования, написанное на Python с помощью GUI библиотеки Tkinter.
Кто такой Thread Pool и как его написать своими руками на С++

Thread Pool достаточно популярный паттерн в программировании, с которым рано или поздно сталкивается каждый первый программист. Если вы новичок и не хотите бездумно пользоваться пулом потоков, то эта статья поможет вам разобраться с его устройством и написать наивные реализации с использованием С++ 14 и С++ 17. Так же статья будет полезна всем, кто изучил теорию по многопоточности, но не знает как можно применить свои знания.
Ближайшие события
Спортивное программирование: не все так просто, как кажется
Меня зовут Абай Баймуканов, я – разработчик-алгоритмист международной IT-компании Relog. Уже несколько лет увлекаюсь олимпиадными программированием, поэтому в этой статье хотел бы поделиться своим видением по этому поводу.
Быть олимпиадником по спортивному программированию довольно весело и интересно. Но быть жюри и составителем задач для самих олимпиад – достаточно ответственное и не менее интересное дело. Спортивное программирование - это те же математические задачки на логику, которые всего то нужно решить. Но программирование, в отличие от любого другого предмета, уникально тем, что решение нужно еще и реализовать в виде компьютерной программы.
Здесь есть свой нюанс: программа может работать настолько долго, сколько не существует даже вселенная, а может сработать за долю секунды. Причем в обоих случаях результат будет один и тот же. Любой олимпиадник стремится к тому, чтобы его программа была как можно эффективнее. Для этого существуют алгоритмы и структуры данных - методы, позволяющие сделать определенные программы более эффективными с точки зрения необходимого времени или памяти компьютера.
Спектр сложности у задач по спортивному программированию достаточно широкий: от задач для новичков до задач мирового уровня для вундеркиндов. Большинство соревнований проводится практически одном и том же формате, то есть дается несколько задач, на их решение 5 часов и за это время нужно решить как можно больше.
На школьных олимпиадах обычно за каждую задачу можно получить от 0 до 100 баллов и общим результатом будет суммарный балл за все задачи, у студентов в результат идет просто количество решенных задач, а если есть участники, решившие одно и то же количество задач, то они группируют по убыванию штрафа. Чем дольше решаешь задачу или чем больше на них нужно попыток решить, тем больше штрафов за нее получишь.
Эзотерическая оптимизация газа в Solidity

Программирование в Солидити отличается от других языков, так как каждое инструкция и байт памяти тратят газ - деньги пользователей. В сети уже есть много ресурсов с основными техниками оптимизации кода (например, стараться использовать calldata вместо memory), но я хочу показать несколько совсем безумных и неочевидных.
Понять о чем я говорю без базового опыта в solidity будет очень сложно, но может быть эти оптимизации проявят в вас интерес в ethereum программировании.
Репликация с нуля за 5 простых шагов (невозможна)
Если вы давно хотели углубиться в эту тему и разобраться в устройстве репликации на живом примере, то эта статья для вас.
Алгоритм Томасуло как фактор импортозамещения российских процессоров

Проектированием простого процессора сейчас никого не удивишь. Любой способный студент может за пару недель написать на верилоге однотактный RISC-V или ARM процессор и синтезировать его для ПЛИС. Процессор будет работать на учебной плате и выполнять простые программы на Си и ассемблере.
Такой процессор можно постепенно усложнять: сделать его конвейерным, добавить кэш и прерывания. Но где находится граница между такими студенческими упражнениями - и взрослыми высокопроизводительными процессорными ядрами, которые стоят в сотовых телефонах и облачных серверах?
На границе между вводным и продвинутым курсом микроархитектуры CPU принято ставить внеочередное выполнение инструкций, именно оно отделяет мальчика от мужа. Эта фича впервые появилась еще в 1960-е годы в суперкомпьютерах CDC 6600 и IBM 360/91, но проникла в персоналки с PentiumPro только в 1996 году и в Apple iPhone в 2012 году.
Именно внеочередное выполнение инструкций - главная козырная карта самого горячего процессорного проекта российской микроэлектроники - двухгигагерцового RISC-V процессора для ноутбуков от компании Ядро / Syntacore. Этот проект был объявлен в прошлом году. Что с ним станет в результате известных событий?
Эвекция Луны, Вариация Луны, Звездный Лунный месяц в часовых отрезках времени в радиоактивном распаде
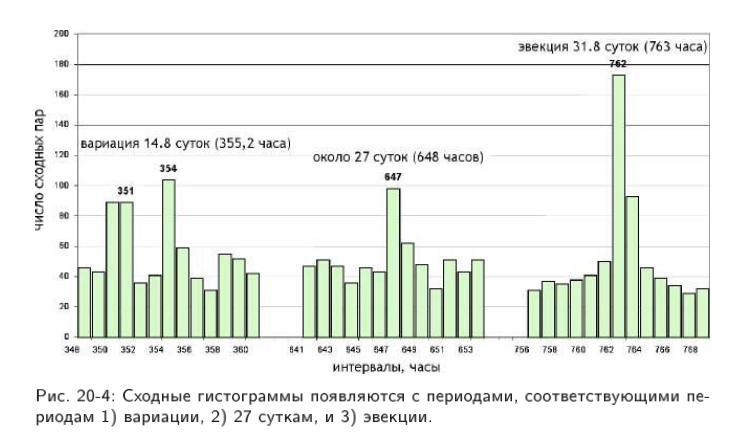
Для всех кто хочет познакомиться с книгой Космофизические факторы в случайных процессах Симона Эльевича Шноля оставляю ссылку
Чтобы решать «нерешаемые» задачи, нужно знать алгоритмы

Артем Мурадов — Senior Software Development Engineer в Amazon и автор курса «Алгоритмы: roadmap для работы и собеседований». Уже больше 14 лет он использует алгоритмы для решения рабочих задач и прохождения собеседований. С помощью алгоритмов он повышал производительность приложений, побеждал в спорах с коллегами и ускорял исследование ДНК. Даже попасть в Amazon ему помогло знание алгоритмов.
Мы пообщались с Артемом, чтобы узнать о его опыте. Он подробно рассказал, как изучал алгоритмы и как они помогали ему в работе.
Логистика. Часть 4. Пришло ли время авиации измениться? Как научиться управлять ценой?
