Пользуетесь ли вы структурами данных и алгоритмами в повседневной работе? Я обратил внимание на то, что всё больше и больше людей считает алгоритмы чем-то таким, чем, без особой связи с реальностью, технические компании, лишь по собственной прихоти, интересуются на собеседованиях. Многие жалуются на то, что задачи на алгоритмы — это нечто из области теории, имеющей слабое отношение к настоящей работе. Такой взгляд на вещи, определённо, распространился после того, как Макс Хауэлл, автор Homebrew, опубликовал
твит о том, что произошло с ним на собеседовании в Google:
Google: 90% наших инженеров пользуются программой, которую вы написали (Homebrew), но вы не можете инвертировать бинарное дерево на доске, поэтому — прощайте.
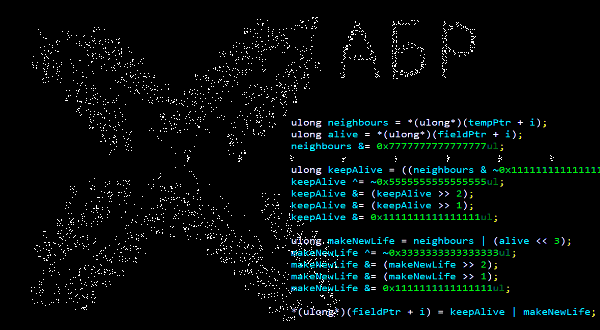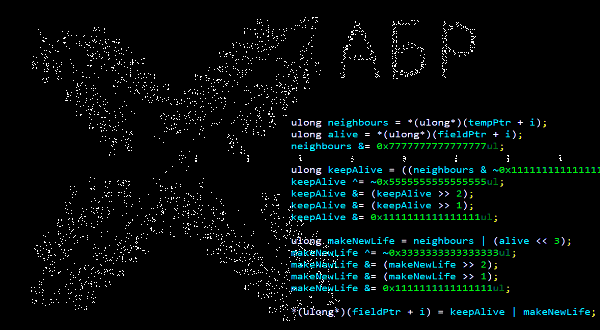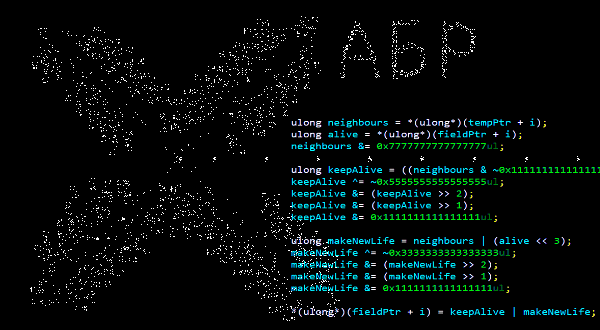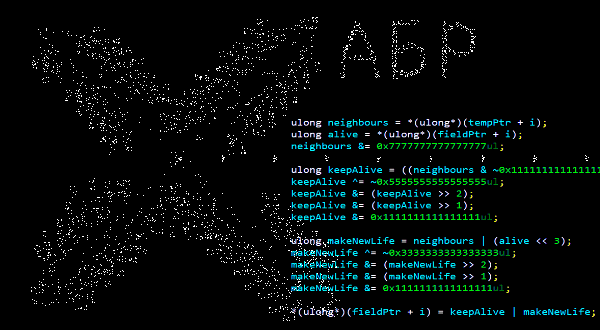
Хотя и у меня никогда не возникало нужды в инверсии бинарного дерева, я сталкивался с примерами реального использования структур данных и алгоритмов в повседневной работе, когда
трудился в Skype/Microsoft, Skyscanner и Uber. Сюда входило написание кода и принятие решений, основанное на особенностях структур данных и алгоритмов. Но соответствующие знания я, по большей части, использовал для того чтобы понять то, как созданы некие системы, и то, почему они созданы именно так. Знание соответствующих концепций упрощает понимание архитектуры и реализации систем, в которых эти концепции используются.

В эту статью я включил рассказы о ситуациях, в которых структуры данных, вроде деревьев и графов, а так же различные алгоритмы, были использованы в реальных проектах. Здесь я надеюсь показать читателю то, что базовые знания структур данных и алгоритмов — это не бесполезная теория, нужная только для собеседований, а что-то такое, что, весьма вероятно, по-настоящему понадобится тому, кто работает в быстрорастущих инновационных технологических компаниях.