Apache Cassandra — это одна из популярных распределенных дисковых NoSQL баз данных с открытым исходным кодом. Она применяется в ключевых частях инфраструктуры такими гигантами как Netflix, eBay, Expedia, и снискала популярность за свою скорость, способность линейно масштабироваться на тысячи узлов и “best-in-class” репликацию между различными центрами обработки данных.
Apache Ignite — это In-Memory Computing Platform, платформа для распределенного хранения данных в оперативной памяти и распределенных вычислений по ним в реальном времени с поддержкой JCache, SQL99, ACID-транзакциями и базовой алгеброй машинного обучения.
Apache Cassandra является классическим решением в своей области. Как и в случае с любым специализированным решением, её преимущества достигнуты благодаря ряду компромиссов, значительная часть которых вызвана ограничениями дисковых хранилищ данных. Cassandra оптимизирована под максимально быструю работу с ними в ущерб остальному. Примеры компромиссов: отсутствие ACID-транзакций и поддержки SQL, невозможность произвольных транзакционных и аналитических транзакций, если под них заранее не адаптированы данные. Эти компромиссы, в свою очередь, вызывают закономерные затруднения у пользователей, приводя к некорректному использованию продукта и негативному опыту, либо вынуждая разделять данные между различными видами хранилищ, фрагментируя инфраструктуру и усложняя логику сохранения данных в приложениях.
Возможное решение проблемы — использование Cassandra в связке с Apache Ignite. Это позволит сохранить ключевые преимущества Cassandra, при этом скомпенсировав ее недостатки за счет симбиоза двух систем.
Как? Читайте дальше, и смотрите пример кода.






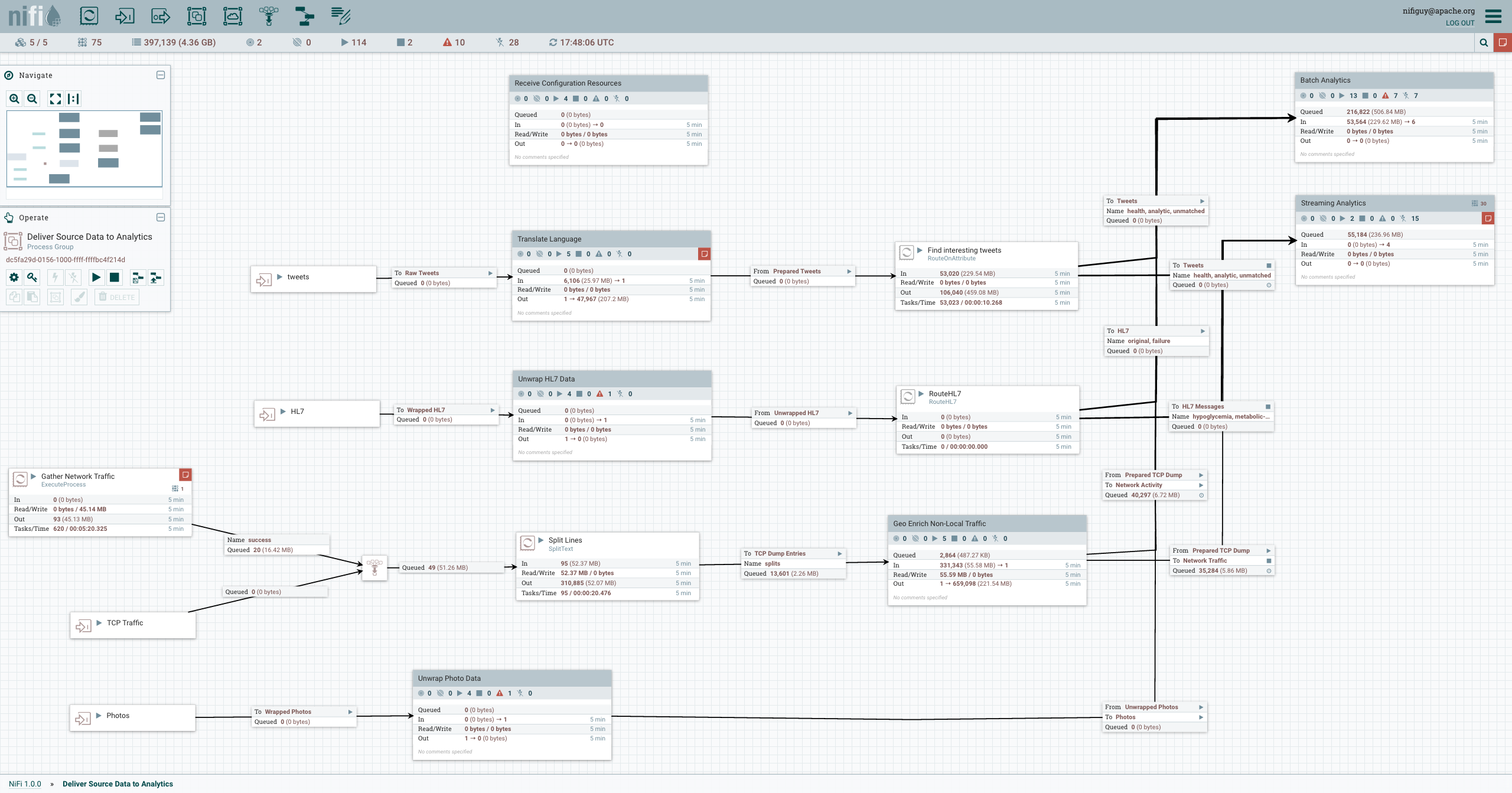 Рис. 1. GUI Apache NiFi.
Рис. 1. GUI Apache NiFi.