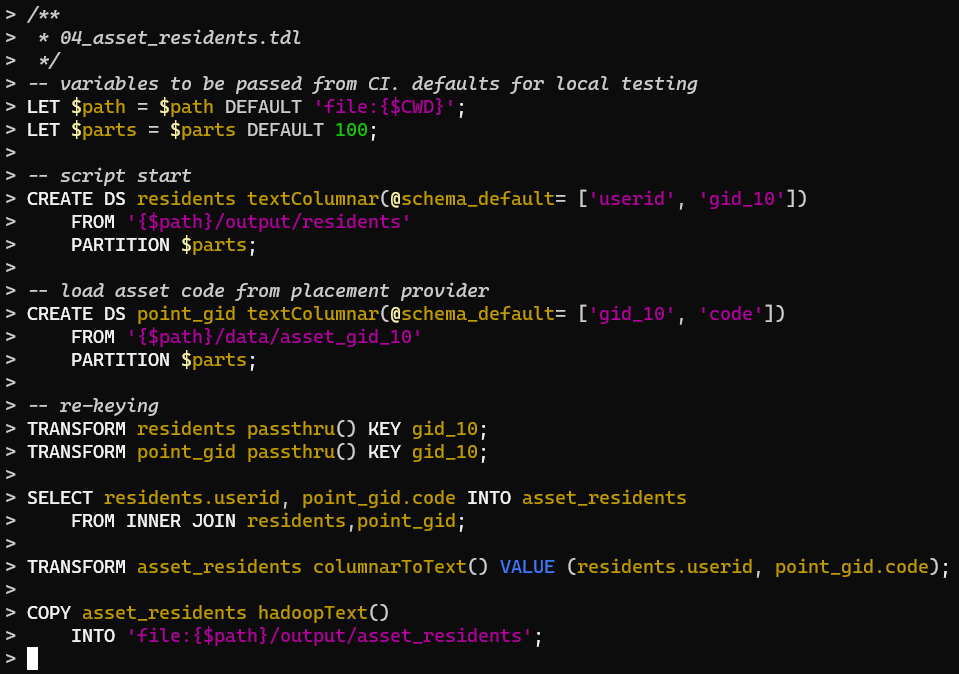
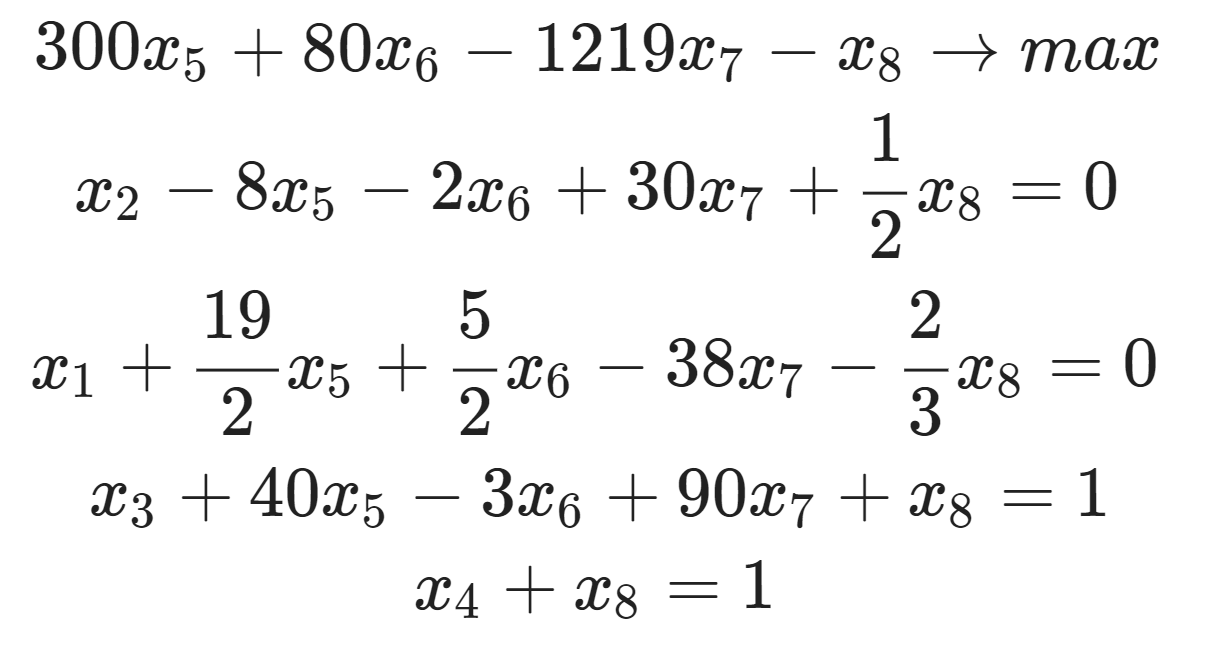Использование ML в онлайн-шоппинге не ограничивается рекомендациями товаров. Покупать одежду и обувь проще, когда у любого бренда ты знаешь нужный размер, видишь удачное сочетания товаров и легко находишь похожие внешне или по цвету вещи.
В Lamoda Tech мы создаем продукты, которые решают самые разные задачи пользователей и бизнеса. На митапе 28 марта мы рассказали, какие ML-модели работают у нас в проде и как мы строили эту работу.
Делимся с вами видео выступлений и презентациями.