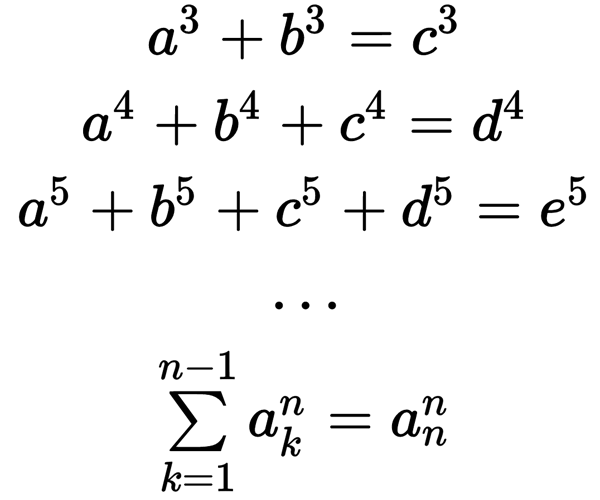История одного бага: выравнивание данных на x86
14 мин
Перевод
Однажды мне пришлось вычислять сумму векторов целых чисел.
Звучит необычно. Кому понадобится делать это в реальной жизни? Обычно такие вычисления встречаются только в задачках из начальной школы или бенчмарках компилятора. Но сейчас это случилось на самом деле.
В реальности стояла задача проверить контрольную сумму заголовков IPv4, которая является суммой обратных кодов (дополнений до единицы) двухбайтных машинных слов. Проще говоря, это означает сложение всех слов и всех битов переноса, которые производятся в процессе. У этой процедуры есть несколько приятных особенностей:
Звучит необычно. Кому понадобится делать это в реальной жизни? Обычно такие вычисления встречаются только в задачках из начальной школы или бенчмарках компилятора. Но сейчас это случилось на самом деле.
В реальности стояла задача проверить контрольную сумму заголовков IPv4, которая является суммой обратных кодов (дополнений до единицы) двухбайтных машинных слов. Проще говоря, это означает сложение всех слов и всех битов переноса, которые производятся в процессе. У этой процедуры есть несколько приятных особенностей:
- её можно эффективно выполнить с помощью процессорной инструкции
ADC(к сожалению, эта функция недоступна в C); - её можно выполнить на словах любого размера (можете добавить по желанию восьмибайтные значения, только результат следует уменьшить до двух байт и добавить все биты переполнения);
- она нечувствительна к порядку следования байтов (удивительно, но это так).



 Lock-free list является основой многих интересных структур данных, — простейшего
Lock-free list является основой многих интересных структур данных, — простейшего