Business intelligence и качество исходных данных
Простой
6 мин
Кейс

Сегодня бизнес хочет принимать решения, основываясь на данных, а не на ощущениях, тем более что сейчас для этого есть все возможности. Предприятия накопили терабайты и эксабайты данных, их количество растет в геометрической прогрессии каждый день.
Как повлиял ковид на ценообразование загородной недвижимости? Какой регион выбрать для новой мебельной фабрики? Вложиться в жилой комплекс эконом или бизнес-класса? Какие факторы влияют на продление ДМС? Как должно работать индивидуальное автострахование?
В наши дни ты должен быть data-driven или проиграешь.
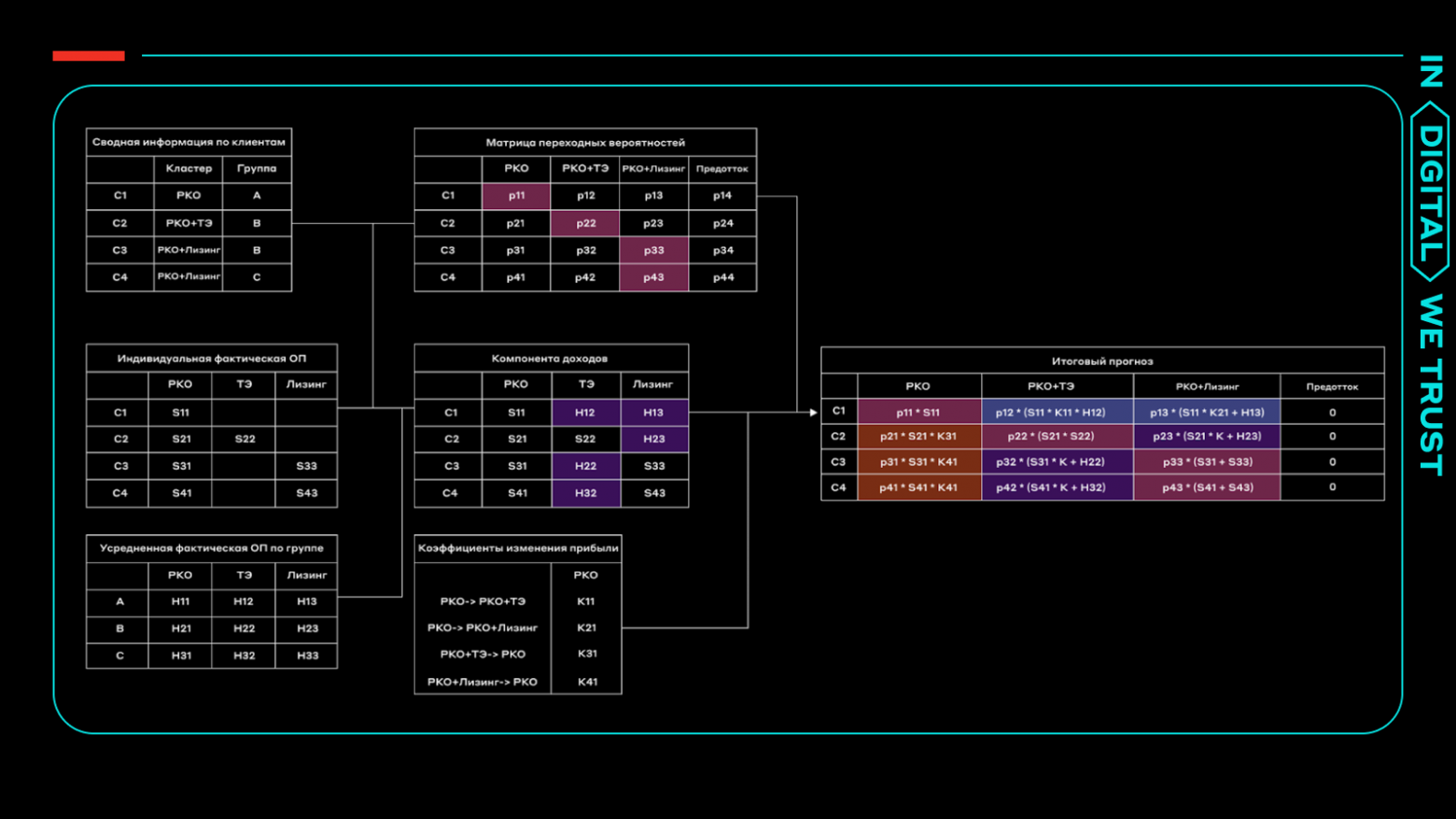
Сырые данные предприятия проходят большой путь, чтобы превратиться в управленческие решения. Этот путь включает такие шаги как: