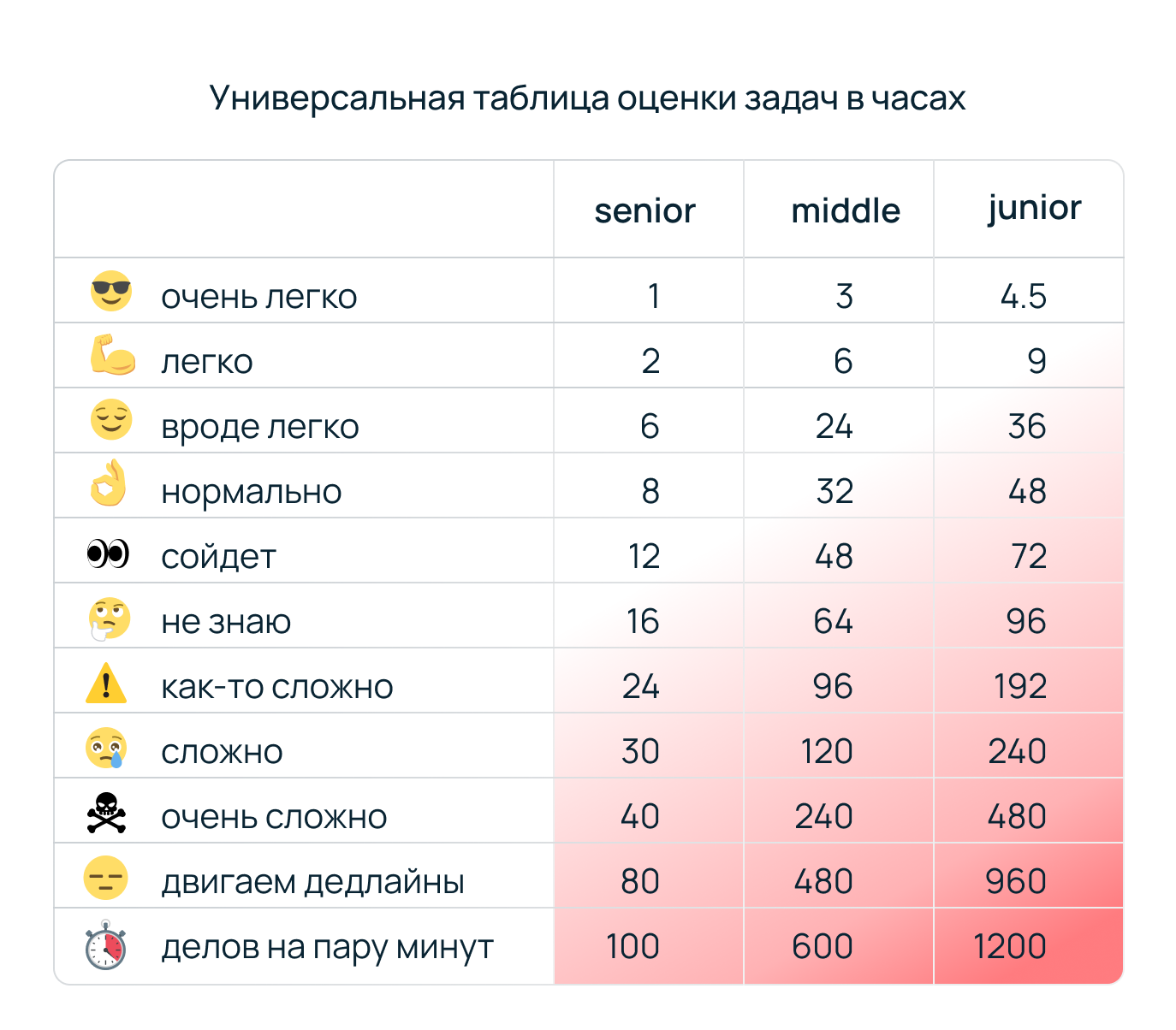
Как я пришёл в дата-анализ после долгих блужданий по онлайн-курсам, маршрут со всеми тупиками и ухабами

Привет! Меня зовут Алексей, я дата-аналитик. Четыре года назад я пришёл в дата-анализ из сферы, далековатой от IT, — пивоварения (хотя о том, что на самом деле они не так далеки, я рассказывал здесь). До того как я нашёл свою нишу, тщетно пробовал вкатиться в IT через разные курсы по Python, TensorFlow и веб-разработке. Потратил на это три года и 100 тысяч рублей, в какой-то момент выгорел ещё в процессе обучения, чуть не бросил попытки, но собрался и в итоге самостоятельно и бесплатно изучил анализ данных, который мне сразу зашёл.
Сейчас я вижу, что многие начинающие блуждают теми же окольными путями. Поэтому решил написать про свой путь с фейлами и граблями и рассказать, что мне помогло найти своё. Надеюсь, мой текст будет полезен — добро пожаловать под кат.