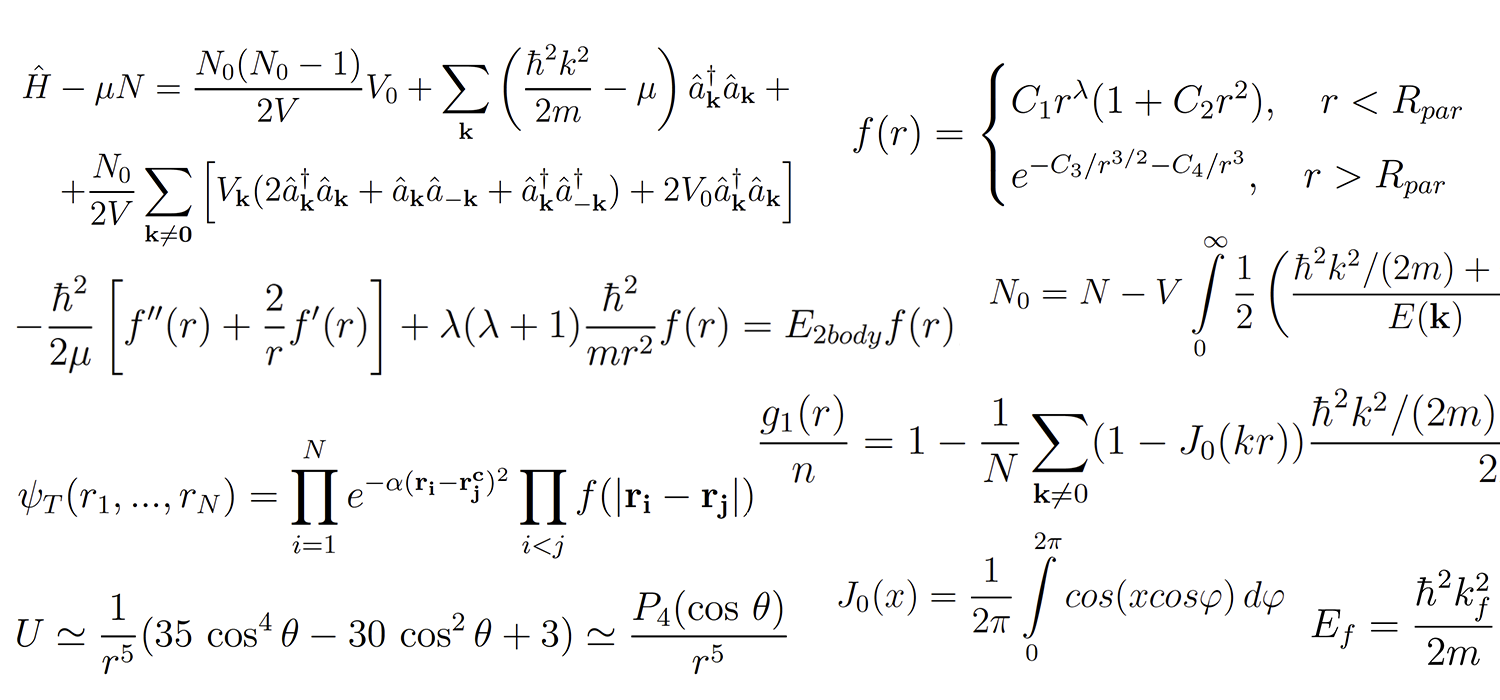Время пополнять копилку хороших русскоязычных докладов по Machine Learning! Копилка сама не пополнится!
В этот раз мы познакомимся с увлекательным рассказом Андрея Боярова про распознавание сцен. Андрей — программист-исследователь, занимающийся машинным зрением в компании Mail.Ru Group.
Распознавание сцен — одна из активно применяемых областей машинного зрения. Задача эта посложнее, чем изученное распознавание объектов: сцена — более комплексное и менее формализованное понятие, выделить признаки труднее. Из распознавания сцен вытекает задача распознавания достопримечательностей: нужно выделить известные места на фото, обеспечив низкий уровень ложных срабатываний.
Это 30 минут видео с конференции Smart Data 2017. Видео удобно смотреть дома и в дороге. Для тех же, кто не готов столько сидеть у экрана, или кому удобней воспринимать информацию в текстовом виде, мы прикладываем полную текстовую расшифровку, оформленную в виде хабростатьи.
В этот раз мы познакомимся с увлекательным рассказом Андрея Боярова про распознавание сцен. Андрей — программист-исследователь, занимающийся машинным зрением в компании Mail.Ru Group.
Распознавание сцен — одна из активно применяемых областей машинного зрения. Задача эта посложнее, чем изученное распознавание объектов: сцена — более комплексное и менее формализованное понятие, выделить признаки труднее. Из распознавания сцен вытекает задача распознавания достопримечательностей: нужно выделить известные места на фото, обеспечив низкий уровень ложных срабатываний.
Это 30 минут видео с конференции Smart Data 2017. Видео удобно смотреть дома и в дороге. Для тех же, кто не готов столько сидеть у экрана, или кому удобней воспринимать информацию в текстовом виде, мы прикладываем полную текстовую расшифровку, оформленную в виде хабростатьи.






 Это реальная история. События, о которых рассказывается в посте, произошли в одной теплой стране в 21ом веке. На всякий случай имена персонажей были изменены. Из уважения к профессии всё рассказано так, как было на самом деле.
Это реальная история. События, о которых рассказывается в посте, произошли в одной теплой стране в 21ом веке. На всякий случай имена персонажей были изменены. Из уважения к профессии всё рассказано так, как было на самом деле.