Аномалии электоральной статистики на выборах в Государственную Думу 2021 года по 125 ОИК
10 мин
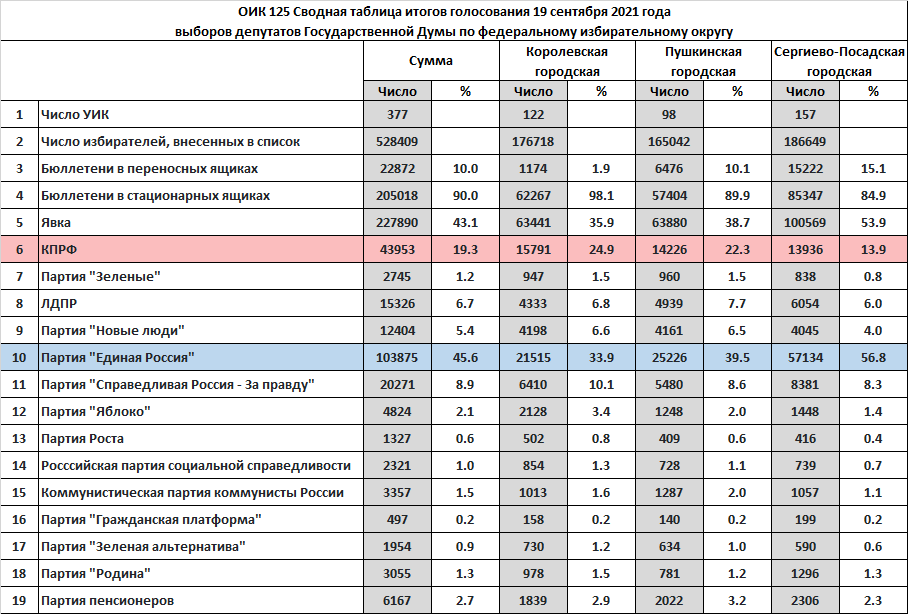
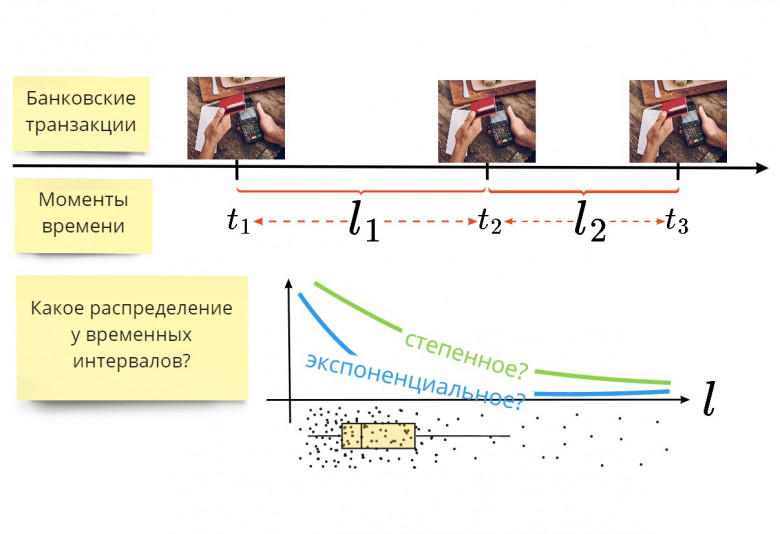
Статистика 377 участковых избирательных комиссий Королёва, Пушкино, Сергиева Посада, входящих 125 ОИК по голосованию 19 сентября 2021 года по выборам депутатов Государственной Думы РФ. Диаграммы явки и результативности партий, поиск критерия определения "предполагаемых" фальсификаций. Расчет скорректированного результата.
Три частично перекрывающихся кластера УИК.
Первый: явка 20-45% при доле Единой России 20-40%, условно его обозначим “гладкое голосование”.
Второй: явка 40-65% при доле Единой России 35-65%, условно его обозначим “административная мобилизация”.
Третий: явка более 65% при доле Единой России более 60%, условно его обозначим “предполагаемые грубые фальсификации”.









 .
.