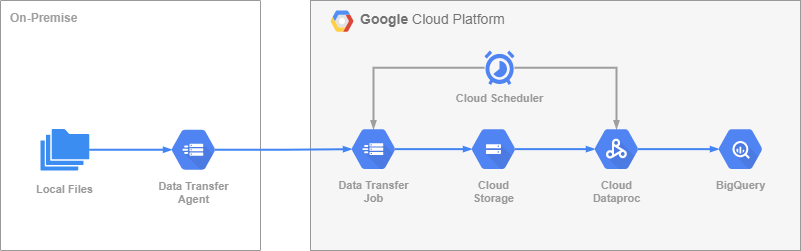
… простите, мигрировали куда? Туда!
CockroachDB — PostgreSQL-совместимая (по SQL-синтаксису DML) распределенная СУБД с открытым кодом (ну, почти). Ее название символизирует, что она, как таракан, выживает в любых экстремальных ситуациях. Лично мне крайне импонирует такая СУБД с привычным SQL-интерфейсом, настройка которой занимает 5 минут, которая хранит данные — как Kafka — на нескольких узлах в нескольких ЦОДах сразу, имеет настраиваемый replication factor на уровне конкретных таблиц, легко переживает потерю как одного узла, так и целого ЦОДа, использует для этого механизм распределенного консенсуса Raft и при этом еще и имеет строгую консистентность и уровень изоляции serializable. Разработчики CockroachDB — выходцы из компании Google, которые решили коммерциализировать архитектуру распределенной СУБД Spanner.

Недостатки тоже есть, не переживайте, но про них лучше в другой раз :)
Почему именно CockroachDB?
Среди распределенных SQL-СУБД есть альтернативы в виде Yugabyte и TiDB, и с прошлого месяца YDB. Вопрос «Почему?» связан в первую очередь с тем, зачем вообще нужна БД. Как мне кажется, БД нужна для того, чтобы надежно хранить данные и доставать их через стандартный язык SQL, а удобство ее использования — приятный, но вторичный фактор. Тут надо заметить, что я почти 9 лет проработал в техподдержке Oracle, и видел достаточно случаев порчи БД, как из-за дисковых сбоев и ошибок администраторов, так и из-за багов в приложении и даже в коде самой СУБД.
Ключевыми критериями выбора были: