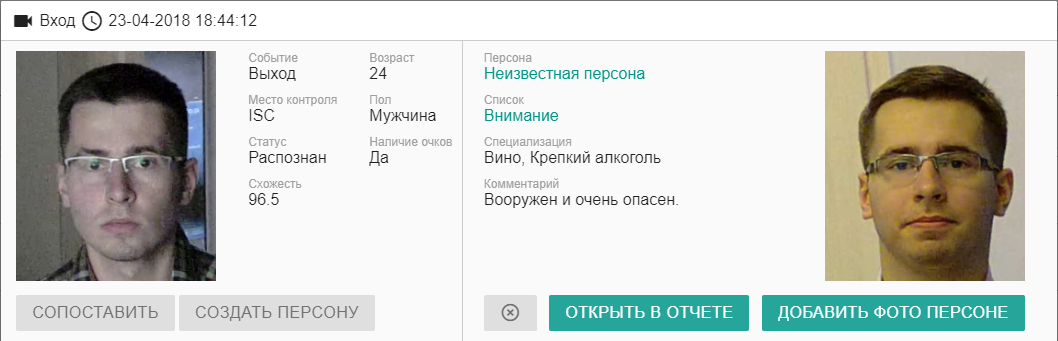
Группа из 3–4 лиц по предварительному сговору способна вынести из большого магазина типа «Ашана» или «Перекрёстка» товара до 400 тысяч рублей в месяц. Если обычные шоплифтеры просто мирно воруют колбасу, протаскивая её под одеждой или ещё где, то эти парни оказываются в разы наглее и деструктивнее.
Разница вот в чём. Во-первых, они имеют возможность запутать всю систему наблюдения, выстроенную для поиска одиночных воров. Самая простая связка — один берёт товар, передаёт незаметно другому, тот относит в слепую зону камер, там его берёт третий.
Во-вторых, они воруют не на предел административки в 1000 рублей, а сразу по максимуму для перепродажи.
В-третьих, при попытке их остановить и вызвать полицию они применяют силовые меры к охраннику и уходят. Силовые меры — это от банального оттеснения охранников от подозреваемого до угроз оружием.
К нам обратилось ЧОП, которое попросило сделать видеоаналитику по тем, кого они уже знают. Чтобы при входе в магазин такого товарища сразу вызывалась полиция и их брали уже тёпленькими.


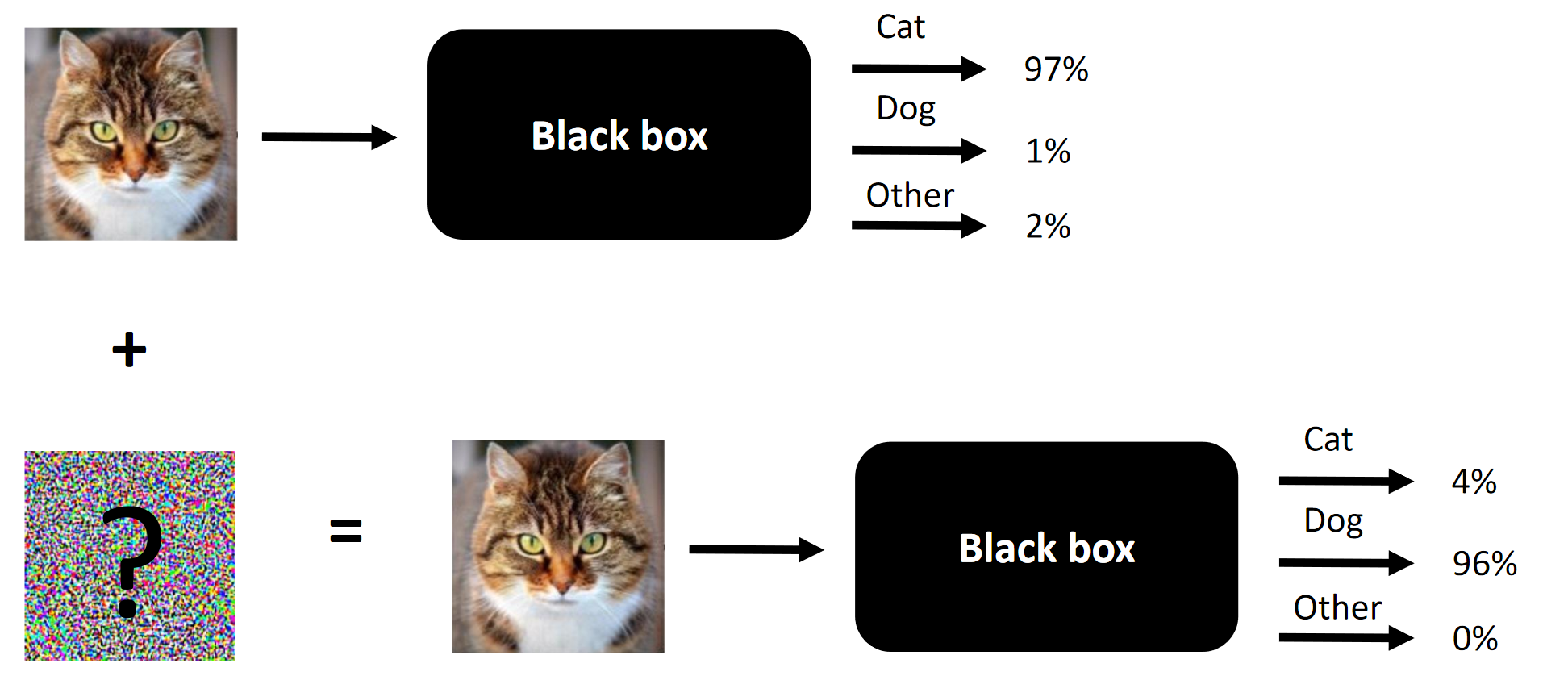











 AV1 — это новый универсальный видеокодек, разработанный Альянсом за открытые медиа (Alliance for Open Media). Альянс взял за основу кодек VPX от Google, Thor от Cisco и Daala от Mozilla/Xiph.Org. Кодек AV1 превосходит по производительности VP9 и HEVC, что делает его кодеком не завтрашнего, а послезавтрашнего дня. Формат AV1 свободен от любых роялти и всегда останется таковым с разрешительной лицензией свободного и открытого ПО.
AV1 — это новый универсальный видеокодек, разработанный Альянсом за открытые медиа (Alliance for Open Media). Альянс взял за основу кодек VPX от Google, Thor от Cisco и Daala от Mozilla/Xiph.Org. Кодек AV1 превосходит по производительности VP9 и HEVC, что делает его кодеком не завтрашнего, а послезавтрашнего дня. Формат AV1 свободен от любых роялти и всегда останется таковым с разрешительной лицензией свободного и открытого ПО.

{kind=link}