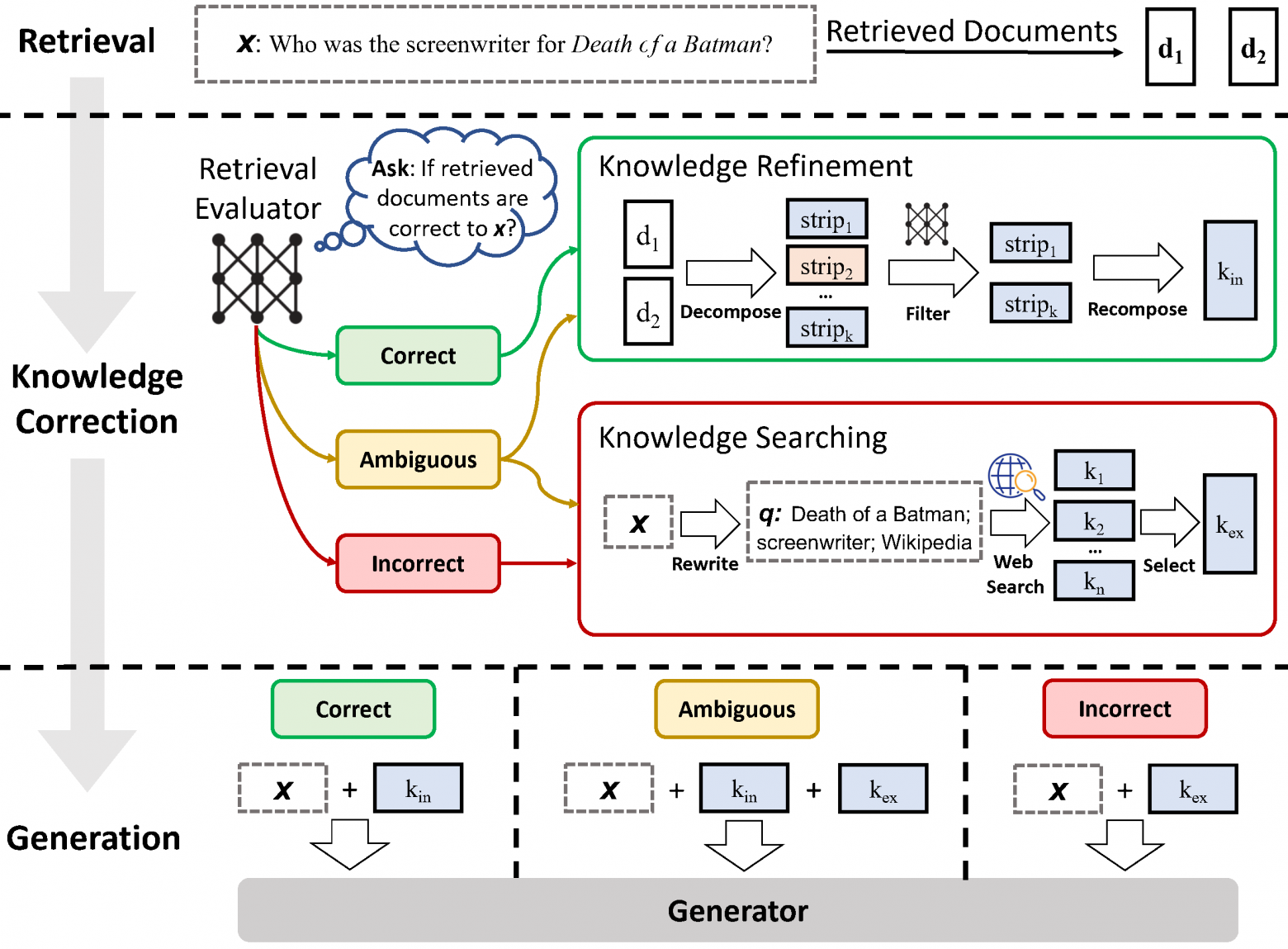
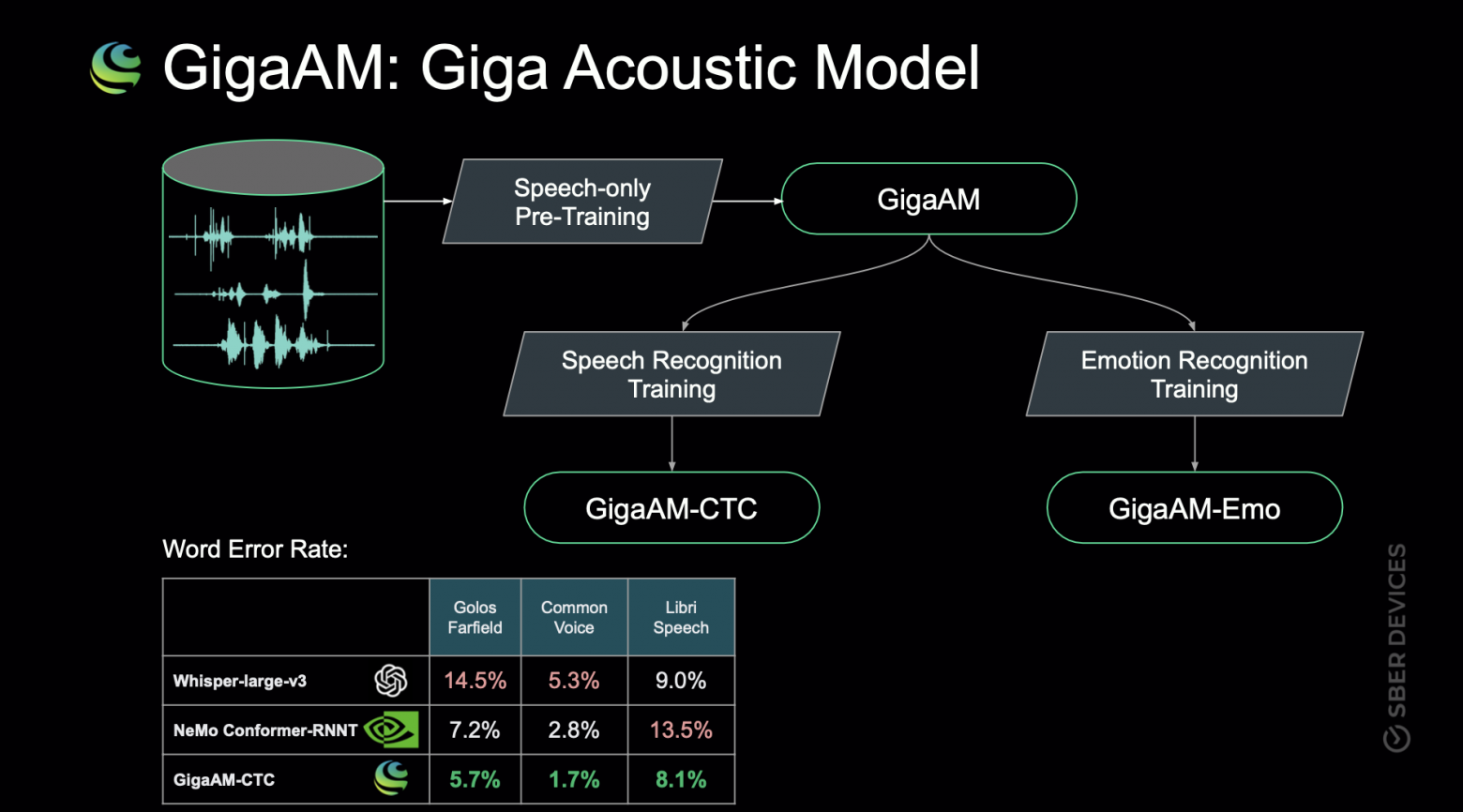
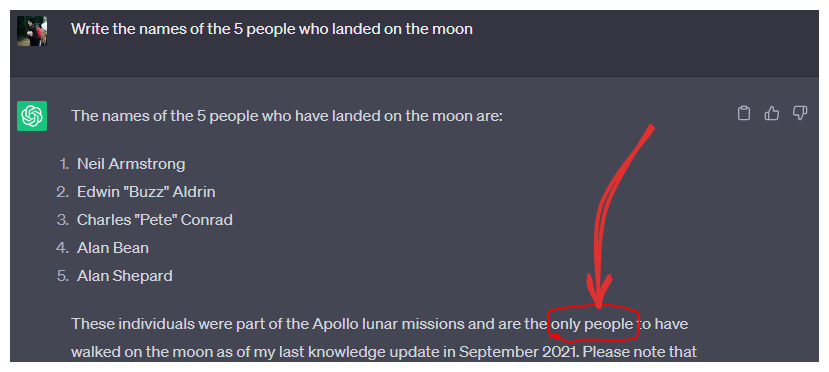
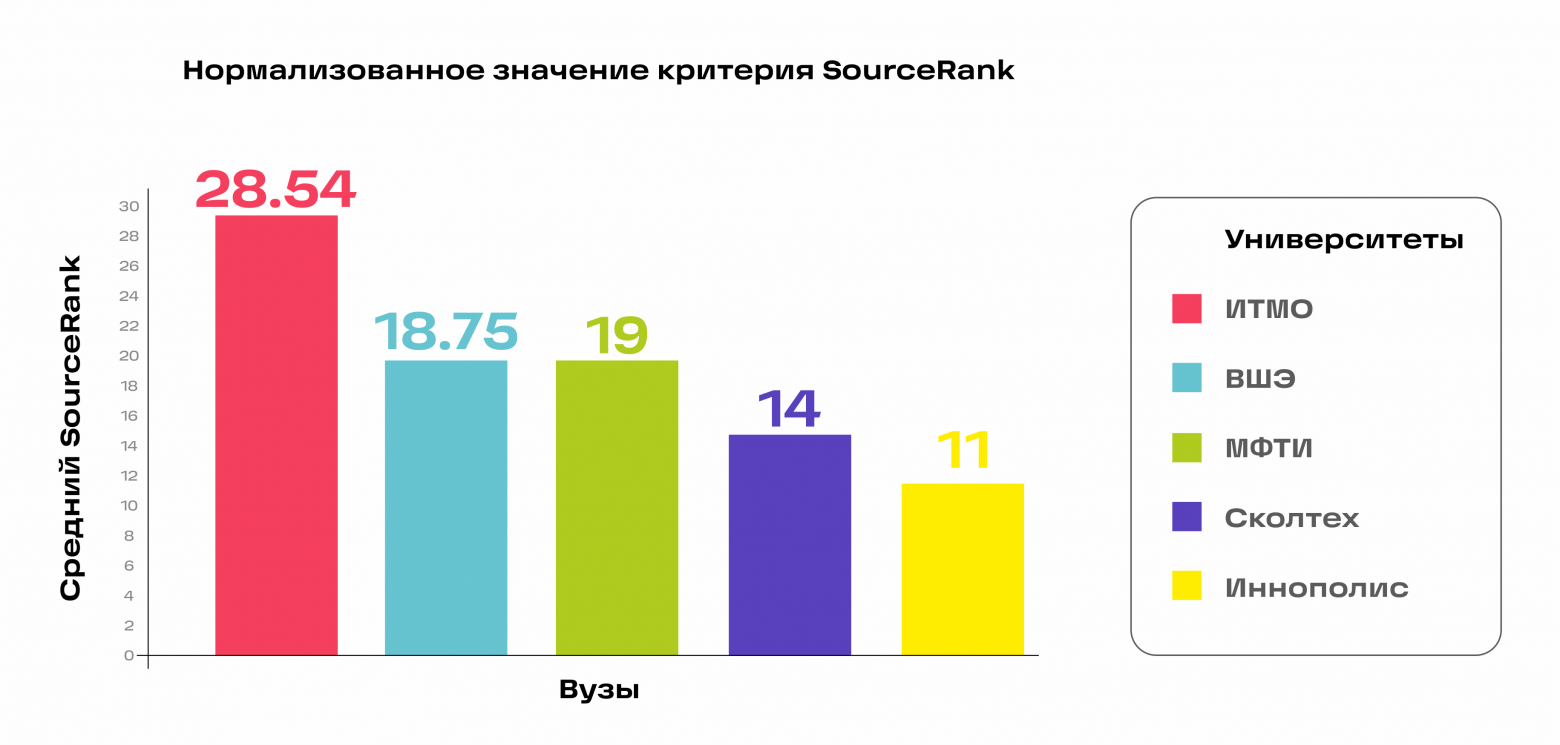
Искусственный интеллект развивается, используя подход, аналогичный коллективному интеллекту людей. Вместо одной мощной системы, разработчики создают много маленьких систем с разными специализациями, которые взаимодействуют между собой.
Сейчас в открытом доступе уже есть огромное количество ИИ-моделей, которые разработчики улучшают и комбинируют, чтобы создавать новые модели для более глубоких и сложных задач. И нынешние технологии позволяют им делать это, не тратя много времени и ресурсов на обучение.
Слияние моделей — это методика, которая объединяет две или более LLM-модели в одну. Это относительно новый и экспериментальный метод создания новых моделей без использования GPU, а значит, недорого. И да, это работает. Причем работает на удивительно хорошо, что в результате дает множество современных моделей на доске лидеров Open LLM.
Сегодня мы рассмотрим, как работает объединение больших языков моделей с использованием библиотеки mergekit. Если более конкретно, то мы рассмотрим четыре метода слияния и предоставим примеры конфигураций. Затем мы воспользуемся mergekit для создания собственной модели, Marcoro14-7B-slerp, которая стала самой эффективной моделью на доске лидеров Open LLM (02/01/2024).
Код доступен на GitHub и Google Colab. Кстати, для простого запуска mergekit можно использовать LazyMergekit.