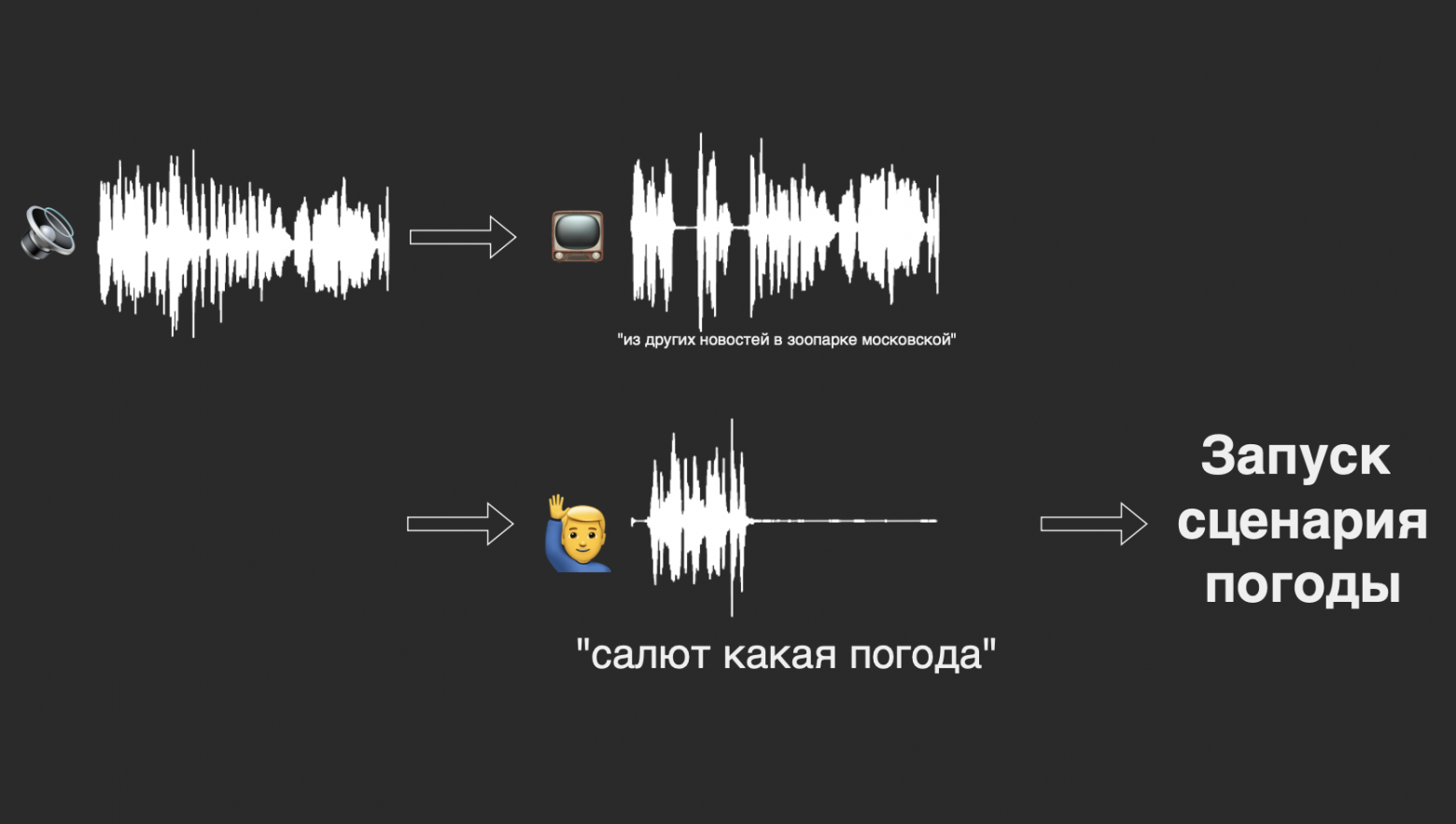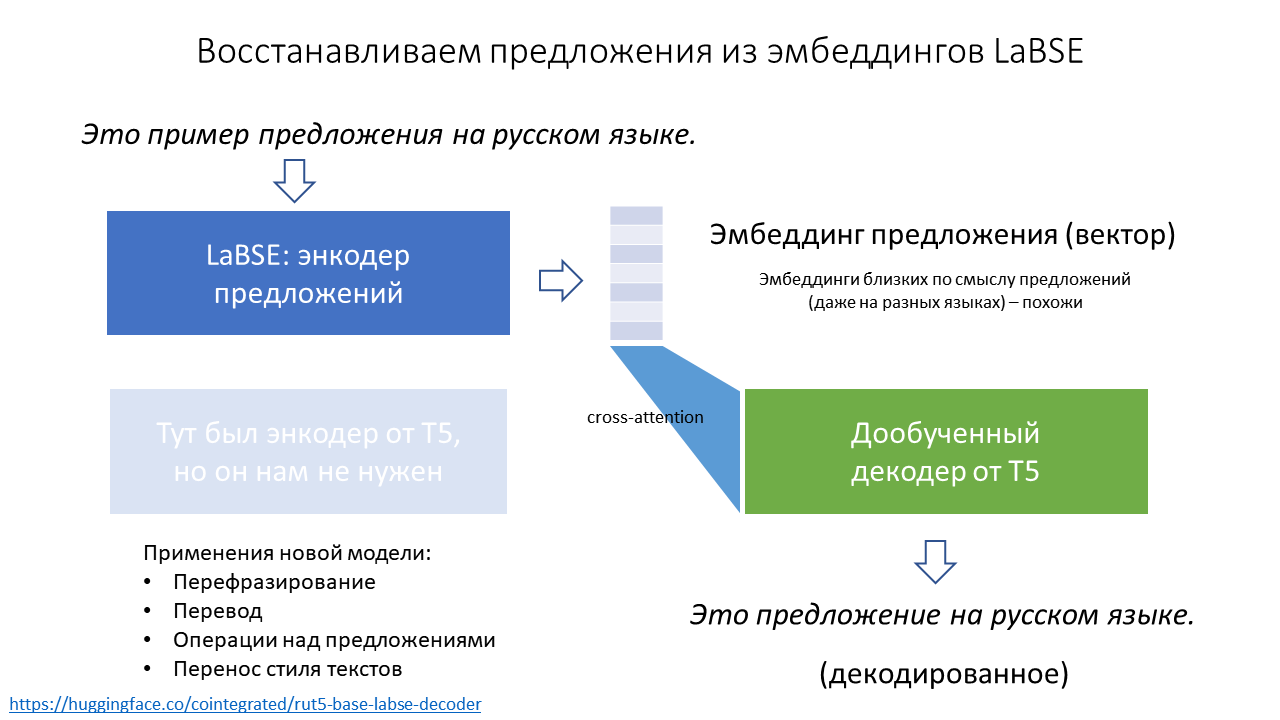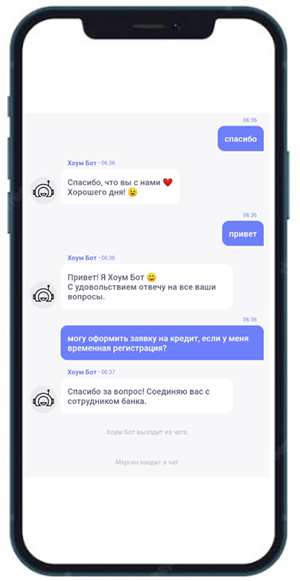
Сначала оказалось, что простые эвристики не работают. Ну вот совсем. То есть тупой чат-бот, который умеет распознавать с десяток жёстких тематик или показывать клавиатуру вроде «Нажмите 1, чтобы узнать свой баланс», несильно экономит время контакт-центру. Люди как не читали инструкции, так и не читают, а при виде такого сразу стремятся выйти на живого оператора.
То есть бот должен быть реально полезным. Таким, чтобы пользователь чувствовал, что диалог с ним — это не конкурс «обойти железного идиота», а что-то всё же даёт.
Здесь ждут следующие грабли: предположим, вы собрали всю базу диалогов контакт-центра с 2002 года. Разметили её и даже обучили на ней бота. Дальше произойдёт следующее:
- Либо актуальность этого обучения будет падать, и так же будет падать процент автоматизации. С каждым месяцем меняются тематики и запросы.
- Либо же вы можете переобучить модели слишком подробными выборками, которые имеют пересечения по категориям.
Речь идёт про то, что если обучать базу на всех диалогах без исключения так, как это подразумевает философия полной автоматизации, то очень быстро база начнёт забиваться откровенным мусором, снижающим точность классификации. Про это вендоры вам не скажут, но нужно либо постоянно что-то подкручивать, либо чистить выборку для обучения, либо обучать не на всех диалогах, которые закончились каким-то удовлетворительным ответом. Иначе очень быстро у вас перепутаются ответы для кредитных и дебетовых карт, например, потому, что клиенты либо путают их в своих стартовых запросах тоже, либо вообще не видят между ними разницы.
Ниже я хочу рассказать про те не совсем очевидные вещи в поддержке чат-бота, которые могут очень сильно уронить качество его работы. Ну или не дать до этого качества дорасти вообще, если архитектура не совсем правильная.