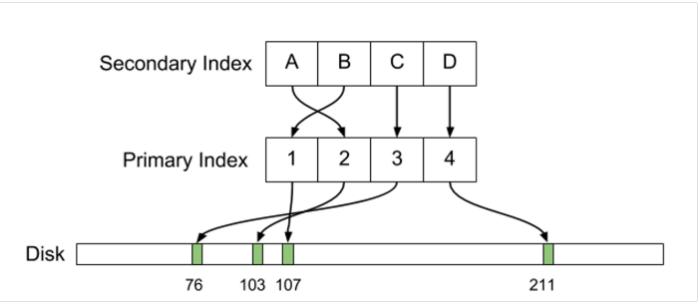
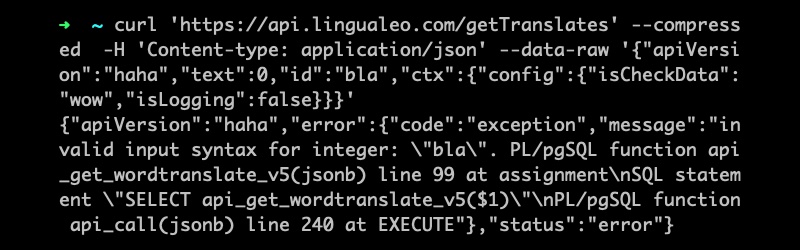
Одиноким вечером, глядя на свою пустую зачётку и осознавая, что конец близок, я снова задумался о том, как бы мне сейчас собрать сумку, или даже просто рюкзак, положить туда рубашку, шорты и свалить в тёплую страну. Было бы хорошо, да вот с дипломом живётся намного лучше. Во всяком случае, мне всегда так говорят.
Также часто слышал много историй про людей, которые приходили на собеседования с красными дипломами МГУ, но при этом абсолютно не разбирались в своей специальности, а потом на корпоративах признавались, что диплом у них купленный.
Но времена сейчас другие, сейчас 21 век, век больших возможностей, любой работодатель, который умеет пользоваться мышкой и знает, как выглядит браузер на рабочем столе, может проверить данные диплома. Каждый диплом, который выдаётся учебным заведением, теперь регистрируется в едином реестре, доступ к которому есть у каждого через сайт Федеральной службы по надзору в сфере образования и науки.

Также часто слышал много историй про людей, которые приходили на собеседования с красными дипломами МГУ, но при этом абсолютно не разбирались в своей специальности, а потом на корпоративах признавались, что диплом у них купленный.
Но времена сейчас другие, сейчас 21 век, век больших возможностей, любой работодатель, который умеет пользоваться мышкой и знает, как выглядит браузер на рабочем столе, может проверить данные диплома. Каждый диплом, который выдаётся учебным заведением, теперь регистрируется в едином реестре, доступ к которому есть у каждого через сайт Федеральной службы по надзору в сфере образования и науки.
Внимание: не пытайтесь повторять действия, описанные в публикации и им подобные. Помните о ст. 272 УК РФ «Неправомерный доступ к компьютерной информации».