
Добрый день, уважаемые читатели. Мы тут недавно осознали простую вещь – наш блог так долго рассказывал о том,
как реализовать ту или иную фичу, что мы совершенно упустили из виду
зачем. Другими словами, когда есть конкретная задача, найти под нее инструмент бывает несложно. Тем более, что со своей стороны мы сделали максимум для того, чтобы это было просто и недорого.
Однако нам часто встречается ситуация, когда клиент просто не знает, что именно он может сделать. Не «как», а именно «зачем». В результате ты где-нибудь на конференции, мельком, рассказываешь простой случай, а из рядов доносится: «O, а это мысль!»
Поэтому мы решили сделать несколько публикаций, посвященных задачам, которые решаются, условно говоря, 10 строчками кода, но необходимость которых не всегда приходит в голову. И первая из них: как мы делали телефонию для сервиса вызова личных водителей Wheely.

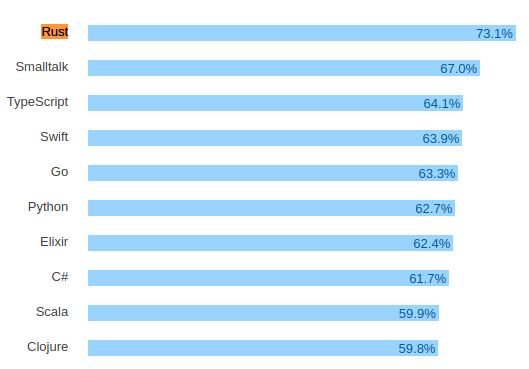 В конце марта вышел очередной мега-опрос разработчиков от StackOverflow, в котором приняли участие десятки тысяч человек. Ссылка на результаты опроса здесь. Отчет получился внушительным по размеру, поэтому давайте просто рассмотрим некоторые интересные моменты из него.
В конце марта вышел очередной мега-опрос разработчиков от StackOverflow, в котором приняли участие десятки тысяч человек. Ссылка на результаты опроса здесь. Отчет получился внушительным по размеру, поэтому давайте просто рассмотрим некоторые интересные моменты из него. 
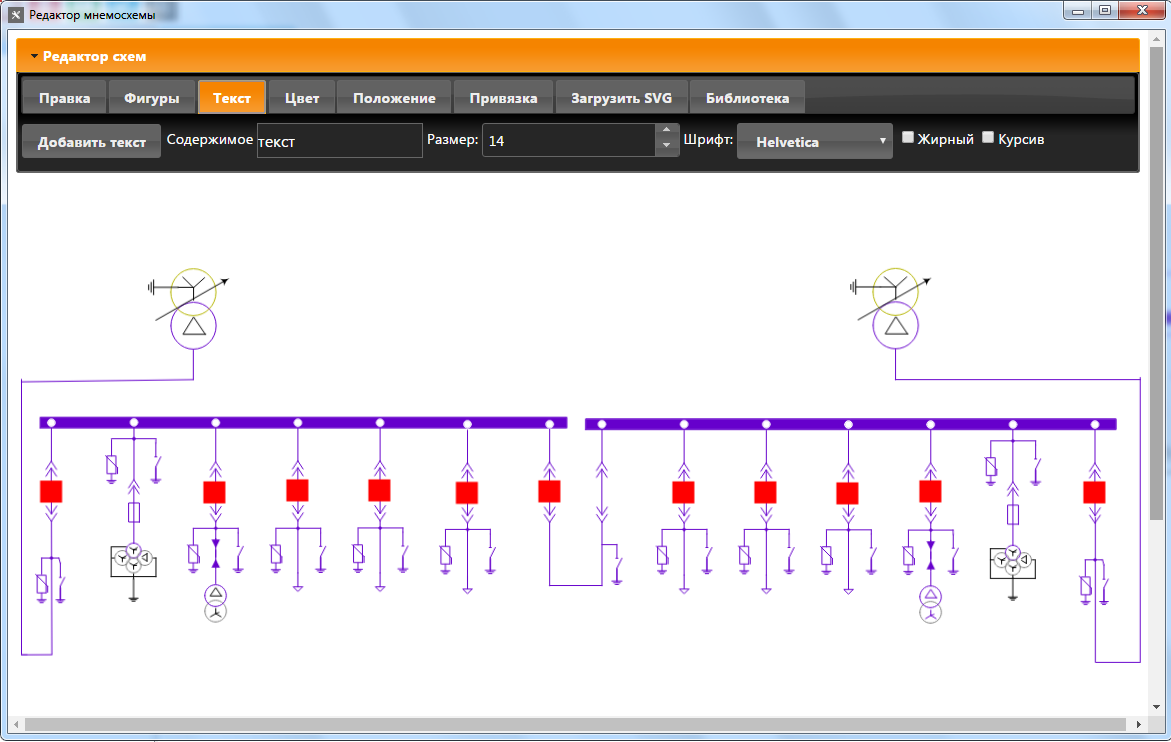











 — Go Template Toolkit
— Go Template Toolkit