Релиз InvokeAI 2.1: теперь с inpainting и Cross Attention
2 мин
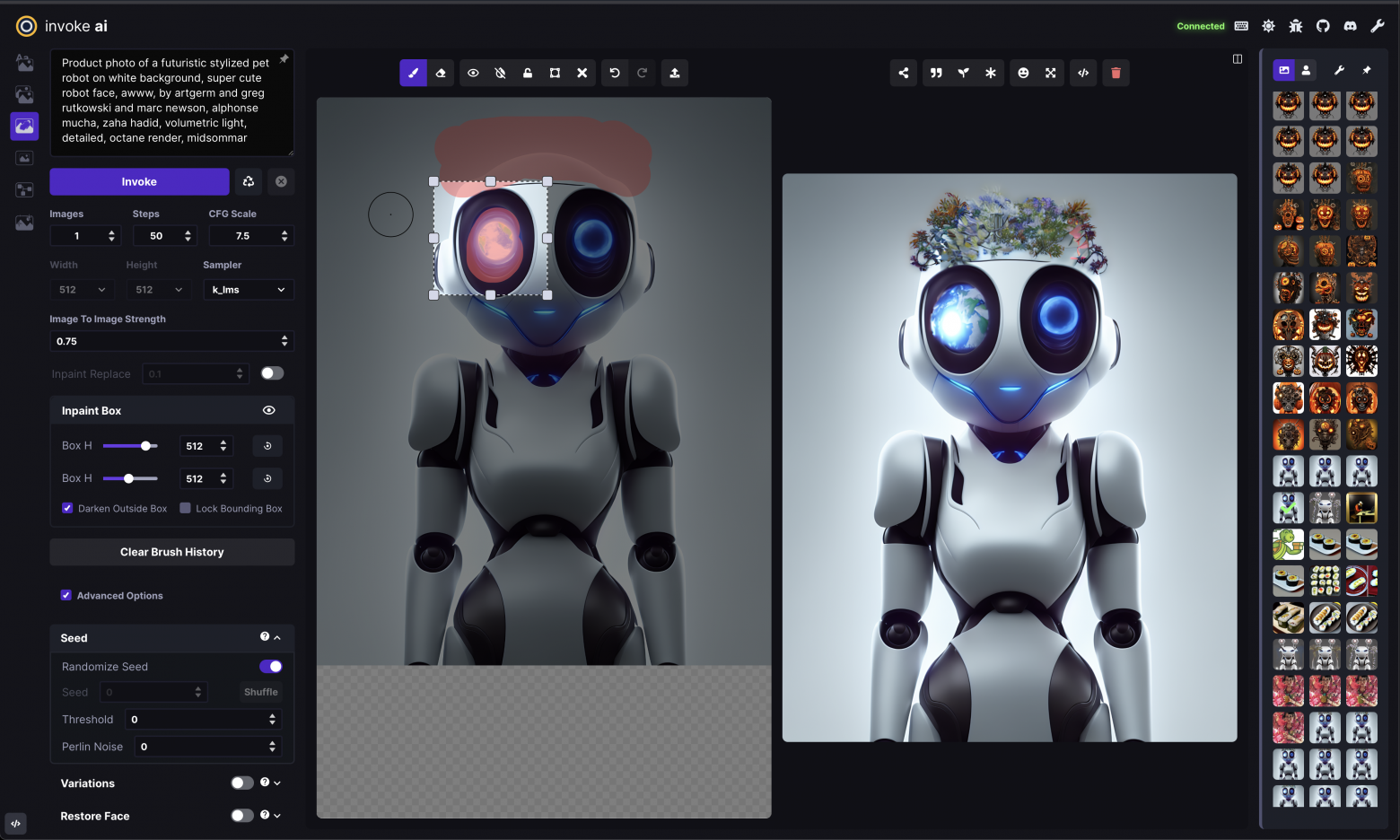
Команда InvokeAI рада поделиться нашим последним релизом с набором новых функций, улучшений графического интерфейса и возможностей командной строки.
Команда InvokeAI рада поделиться нашим последним релизом с набором новых функций, улучшений графического интерфейса и возможностей командной строки.

Python — лучший выбор для анализа данных и машинного обучения. Его производительность в большинстве случаев более чем достаточна. Но как быть, если объемы ваших данных растут значительно быстрее, чем имеющиеся ресурсы, и требуется повышение производительности?
В этой статье мы попробуем решить несколько простых задач, используя чистый Python и два языка расширения: Rust и Cython. Чтобы сравнить два этих подхода, мы оценим трудоемкость каждого из них, а также рассмотрим случаи, в которых следует попробовать что-то другое. Начнем с установки и с простых приложений, а затем перейдем к более сложным экспериментам.

QQ Хабр! В этом гайде мы пройдемся по каждому шагу создания ботов в Telegram - от регистрации бота до публикации репозитория на GitHub. Некоторым может показаться, что все разжевано и слишком много элементарной информации, но этот гайд создан для новичков, хотя будет интересен и для тех, кто уже занимался разработкой в Telegram. Сегодня мы будем делать бота, который отвечает на заданные вопросы.

Всем доброго времени суток!
Так как о Python слышал каждый, кто хотел или хочет связать свою жизнь с IT, предлагаю обзор книги, что поможет вам на первых порах.
Стоит читать? Да! Почему? Опишу в статье.
Python – хороший первый язык программирования, а это лучшая книга для его изучения.
Для кого эта книга?
Книга в первую очередь прекрасно подойдет новичкам, тем , кто только начал свой путь в программирование и на данный момент начинает с нуля, не имеет никакой базы программирования за плечами.
Во вторую очередь я бы посоветовал данную книгу тем, кто уже имеет опыт работы с Python, но хотел бы иметь под рукой полноценный справочник с практическими описаниями основ языка. С примерами, объяснениями – то, что быстро поможет вспомнить простые, но необходимые вещи.

Владение языком Python станет прекрасным активом будущего программиста. Если ваш ребенок увлекается программированием, то процесс обучения можно разнообразить с помощью полезных видео, обучающих игр, вступления в тематические сообщества и многого другого. В этой статье мы собрали полезные ресурсы по Python и поделили их по категориям.

Большинство питонистов не раз слышали о таких правилах как «функции должны быть глаголами» или «не наследуйтесь явно от object в Python 3». В этой статье рассмотрим не такие банальные, но полезные правила чистого кода в Python.

Привет, Хабр!
Меня зовут Андрей, и я data scientist. В этой статье расскажу о том, как я занял второе место в конкурсе «Цифровой прорыв» с решением по автоматизации привязки фотографии к географическому положению. Главный инсайт — базовые решения не всегда хороши и проверены. Спойлер — самодеятельность и использование современных подходов помогают победить :) Расскажу на своем опыте, как не сделать свое решение хуже базового и проанализирую подходы других участников.

Как известно, основной проблемой в тестировании является отчетность по прогонам. Некоторые компании собирают данные в отдельном хранилище. Вместо того, чтобы вручную организовывать хранение, было решено сохранять их в Test IT. Такие данные как: исход, время выполнения и количество автоматизированных кейсов позволяют разделить тесты на выборки и дать оценку покрытия автотестами.
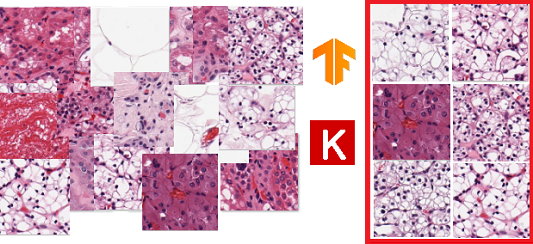
С учётом актуальности Multiple Instance Learning (далее: MIL) и, в частности, наличия преимуществ данного метода для анализа гистологических изображений, решил попробовать обучить модели с целью классификации наборов данных, на те, которые содержат только нормальные ткани и те, в которых встречаются изображения со светлоклеточным раком почки.

В Кремниевой долине есть один весьма своеобразный ресторанчик быстрого питания. Он работает круглосуточно и принимает по одному гостю за раз, ведь там всего один стол. Зато гамбургеры — просто потрясающие. Приходя, вы ждёте, пока стол не освободится. Затем вас приглашают, и, поскольку это Америка, вам задают бесконечную уйму вопросов о том, как готовить и подавать гамбургер.
Но не будем сегодня толковать о кулинарных изысках. В таких ресторанах нам интереснее система очередей. Если вам повезло прийти в ресторан, когда стол свободен и очереди нет, вас сразу посадят за столик. В противном случае вам вручат зуммер (таких «пищалок» у них великое множество!). С таким зуммером вы сможете спокойно бродить по округе, пока он не подаст сигнал. Тот, кто обслуживает гостей, следит, чтобы это делалось в порядке прибытия. Когда подойдёт ваша очередь, он отправит вам сигнал, вы вернётесь в ресторан, и вам найдут место. Продолжение — к старту нашего курса по Fullstack-разработке на Python.
Привет, Хабр! Есть мнение, что прогнозирование временных рядов - сложная задача. Но не будем расстраиваться, ведь есть и плюсы - существует ещё большое количество задач, когда рядов сразу несколько, и такие задачи ещё сложнее! Когда начинаем сравнивать, понимаем, что прогнозировать одномерные временные ряды не так уж и сложно. А вот что делать с ситуацией, когда временной ряд обрастает параллельно идущими с ним последовательностями других параметров (многомерный ряд), какие методы и алгоритмы использовать, и что делать, если задача прогнозировать такие ряды есть, а опыта не очень много (спойлер - используйте AutoML, а пока он работает восполните пробел прочитав пару статей по теме), разбираем под катом.
Что такое временной ряд
Если начинать совсем издалека, то это последовательность значений, упорядоченная по времени. Во временных рядах есть закономерность: текущие значения ряда связаны с предыдущими. Если такого свойства у ряда нет, то поздравляем (или не поздравляем), вы имеете дело с процессом, который прогнозировать классическими (и не очень) моделями не выйдет, в таком случае стоит смотреть в сторону Марковских процессов.
Простенькая картинка ниже иллюстрирует описанное выше свойство, - этого бэкграунда для продолжения чтения поста достаточно (Рисунок 1).

Представьте, что у вас есть функция random(), которая генерируют случайным образом значения в промежутке ![[0;1]](https://habrastorage.org/getpro/habr/upload_files/eff/a38/faa/effa38faa5436724d67f327abc985718.svg)
Вычислите значение числа 
Это задачка с реального собеседования, будем разбираться!

Несколько лет назад генерация 3D-сетки из единственного двумерного изображения была сложной задачей. Но сегодня благодаря продвижению глубокого обучения разработано множество монокулярных моделей оценки глубины, дающих точную оценку карты глубины изображения. С помощью этой карты, выполнив реконструкцию поверхности, можно создать сетку. Подробности — к старту нашего курса по Fullstack-разработке на Python.

В статье я поделюсь опытом, как нам удалось всего за 5 дней собрать команду, придумать идею проекта, создать с нуля работающий прототип продукта, который решает реальную проблему на данных, и параллельно с этим посетить 12 встреч с ML-экспертами из ведущих AI компаний. Надеюсь, мой опыт поможет тебе подготовиться к твоему первому хакатону!

Работаю инженером в компании, у которой есть несколько удаленных филиалов и в каждом из них работают сервера видеонаблюдения. Охрана круглосуточно ведет мониторинг происходящего, а приложение видеонаблюдения на этих серверах имеет привычку зависать. Звонки от охраны могут поступать в любое время суток, что очень неудобно, когда ты спишь или нет доступа к ПК, чтобы подключиться удаленно и перезапустить программу
Я начал задумываться о решении данной проблемы путем создания Telegram бота на Python, с помощью которого можно комфортно перезапускать ПО или делегировать это функцию не компетентным людям, например охране
При всем многообразии решений с помощью Telegram ботов, информации на эту тему в интернете мало, поэтому решил поделиться ей здесь, возможно кому то пригодиться
Так же по этому примеру, через запуск скриптов, возможно управлять инфраструктурой серверов предприятия и пр.., все зависит от вашей фантазии

Когда-то Юрий Орлов решил перейти из врачей в программисты. В 2018 году он устроился в Genix джуном, а сейчас он — тимлид VK Group. Начало истории вы можете послушать здесь, а в статье мы обсудим перипетии тимлидства — как опыт работы врачом помогает находить общий язык с людьми, должен ли тимлид писать код лучше членов команды, как работает Planning poker и что самое сложное в задачах тимлида.
Cтатья подготовлена по мотивам подкаста Moscow Python Podcast при поддержке курсов Learn Python.
 Хорошего настроения, Хаброжители!
Хорошего настроения, Хаброжители!
Привет, Хабр! Меня зовут Николай Суворов, я руководитель направления в МТС Digital. Занимаюсь продуктом МТС Premium – это единая подписка на сервисы МТС и партнеров. Сегодня я расскажу о нашем опыте создания робота для автоматизации повторяющихся действий сотрудников с помощью Jupyter, Python и Selenium. Статья будет интересна прежде всего менеджерам, которые хотят оптимизировать свою работу. Разработчикам мой текст будет полезен с точки зрения понимания возможностей по ускорению повторяющихся действий в интерфейсах. Весь необходимый код – внутри.