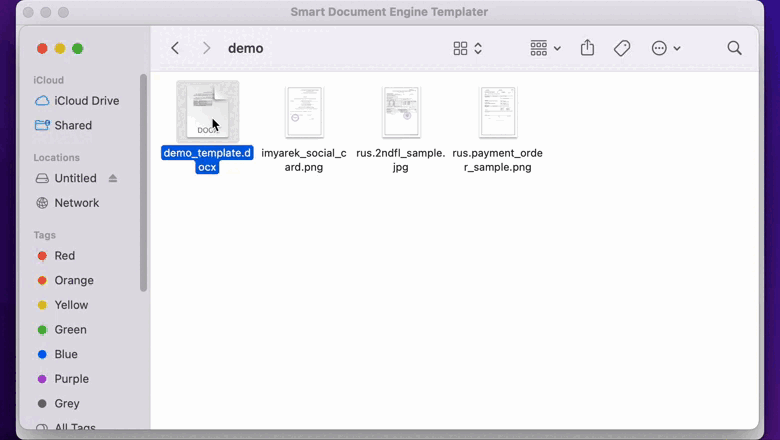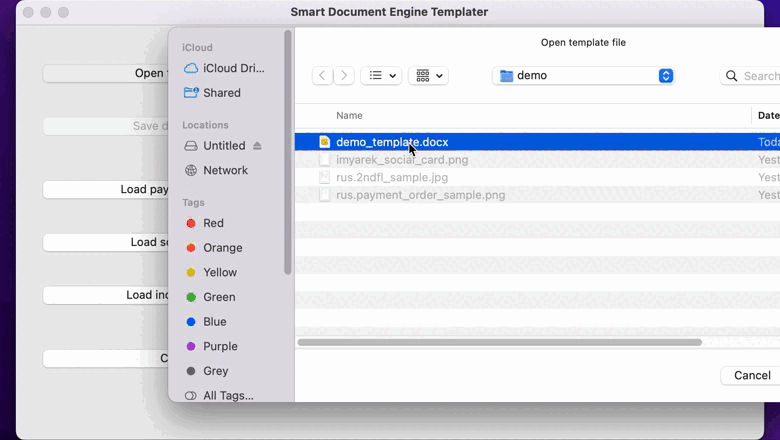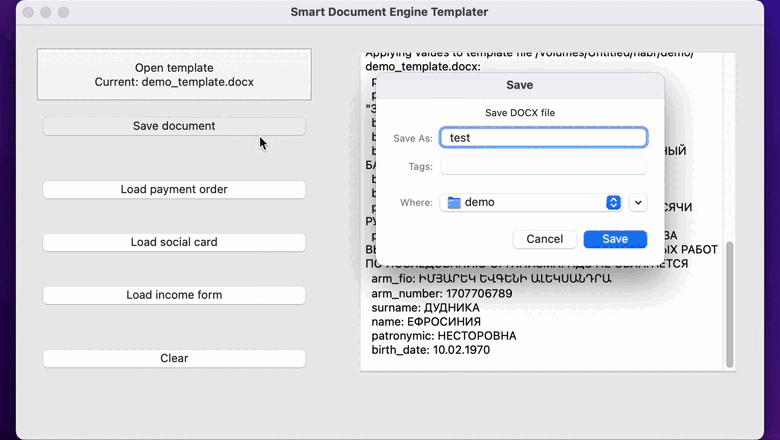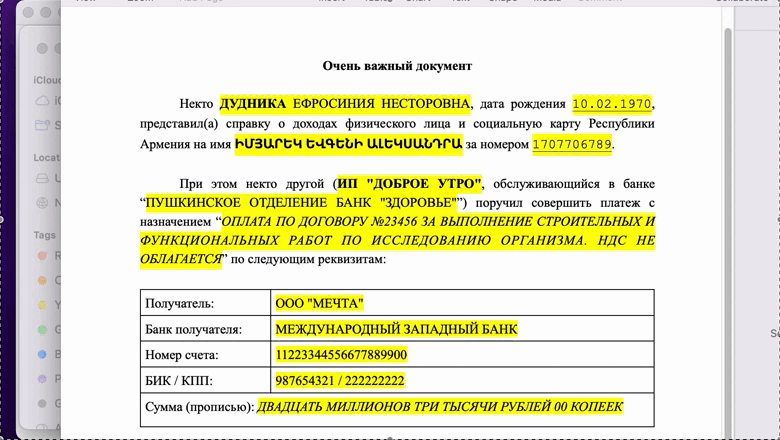
Предлагаю немного поразвлечься и научиться придумывать новые слова, которые звучат совсем как настоящие (прям как товары в Икее). Для начала вот вам десяток несуществующих городов:
• Лумберг, Сеф, Хирнов, Бинли, Лусский, Ноловорск, Сант-Гумит, Хойден, Голтон и Оголенда
И женских имен:
• Инела, Каисья, Ганнора, Целия, Тарисана, Лелена, Феомина, Олиcc, Нулина и Рослиба
Для запуска генерации нам не понадобится технических навыков, хотя технология, стоящая за ней, сейчас является очень перспективной и многофункциональной. Это генеративная нейронная сеть, способная решать множество задач по обработке естествнного языка (NLP). Это такие задачи как суммаризация (сделать из большого текста его резюме), понимание текста (NLU), вопросно-ответные системы, генерация (статей, кода или даже стихов) и другие. Тема эта очень глубокая, поэтому далее я дам пару ссылок для любителей копнуть поглубже. А те, кто хочет "только спросить", может сразу приступить к созданию слов.
Генерировать будем скриптом makemore от Андрея Карпати (недавно писал про скрипт в канале градиент обреченный), который он выложил пару недель назад. Андрей является известным исследователем в мире ИИ и периодически радует народ такими вот игрушками, можно полазить по его репозиторию, там еще много интересного.
Запустим скрипт.