
Как написать средство проверки орфографии кхмерского языка
8 мин
Перевод

Материалом с подробностями о реализации средства проверки и исправления орфографии кхмерского языка, основного в Камбодже, делимся к старту флагманского курса по Data Science.
Материалом с подробностями о реализации средства проверки и исправления орфографии кхмерского языка, основного в Камбодже, делимся к старту флагманского курса по Data Science.


Всем доброго времени суток!
Публикую рецензию подписчика нашего телеграмм-канала IT-старт на книгу "Секреты Python. 59 рекомендаций по написанию эффективного кода" от автора Бретта Слаткина
Краткая, тезисная, но емкая рецензия.
Основные темы книги:
— Действенные рекомендации по основным аспектам разработки ПО с использованием версий Python 3.x и 2.x, дополненные подробными описаниями и примерами.
— Лучшие методики написания функций, снижающие вероятность появления ошибок в коде.
— Точное описание вариантов поведения с помощью классов и объектов. — Рекомендации относительно того, как избежать скрытых ошибок с помощью метаклассов и динамических атрибутов.
— Эффективные подходы к решению проблем, связанных с одновременным и параллельным выполнением множества операций.
— Усовершенствованные приемы работы со встроенными модулями Python.
— Инструментальные средства и лучшие методики коллективной разработки.
— Решения по отладке, тестированию и оптимизации кода.
Книгу мне порекомендовал мой друг и коллега. Добрался до данной книги я не сразу, но исходя из совета моего товарища, прочитал.
Стоит ли читать книгу?
Хочу сэкономить вам ваше время. Данную книгу я не рекомендую к чтению. Некоторые советы вызывают у меня сомнения, что-то нового и прям "вау", я также не узнал. Сложилось также впечатление, что никаких "секретов" тут нет.
Сразу хотелось бы заметить, что я в целом не фанат технической литературы, так как подобная литература отлично подходит для поверхностного и беглого просмотра темы, но читать такие книги "от корки до корки" - дело не из легких.

Одна из наиболее важных задач при разделении системы на микросервисы - обеспечить надежный механизм их репликации и обнаружения и создать набор правил для маршрутизации входящих запросов к соответствующим контейнерам или сетевым узлам. Идеальная система также должна уметь отслеживать состояние доступности и исключать недоступные реплики из маршрутизации. В этой статье мы поговорим об использовании маршрутизатора Kong, который принимает на себя не только задачи умной маршрутизации, но и возможности по протоколированию и трансформации запросов, контролю доступа, мониторингу запросов, а также может быть расширен с использованием плагинов.
Выход практически каждого ролика на канале «вДудь» считается событием, а некоторые из этих релизов даже сопровождаются скандалами из-за неосторожных высказываний его гостей.
Сегодня при помощи статистических подходов и алгоритмов ML мы будем анализировать прямую речь. В качестве данных используем интервью, которые журналист Юрий Дудь (признан иностранным агентом на территории РФ) берет для своего YouTube-канала. Посмотрим с помощью Python, о чем таком интересном говорили в интервью на канале «вДудь».

Научить ИИ разговаривать шёпотом — непростая задача даже сегодня. Но мы покажем, насколько простыми стали распознавание и транскрипция речи, по крайней мере, на поверхности. Интересно? Тогда добро пожаловать под кат.

Привет, Хабр! Меня зовут Игорь Алимов, я ведущий разработчик группы Python в МТС Digital, и это вторая часть статьи, посвященной тому, как писать быстрый код на Python с использованием C-расширений. Я расскажу о всех нюансах и приведу конкретный пример применения этого метода.
Первую часть статьи читайте здесь, чтобы увидеть продолжение – переходите под кат!

Всем привет! На связи Глеб, в предыдущей статье мы рассмотрели работу с объектами на Blender. Но для того, чтобы создать минимально жизнеспособный генератор, нужно разобраться в том, как работают камеры.

Решал я как-то задачку по поиску сущностей в отсканированных документах. Чтобы работать с текстом, надо его сначала получить из картинки, поэтому приходилось использовать OCR. Выбор пал на одну из самых популярных и доступных библиотек Tesseract. С ее помощью задача решается очень неплохо и процент распознавания текста достаточно высокий, особенно на хороших сканах. Но нет предела совершенству, а так же ввиду наличия большого количества документов сомнительного качества, поулучшав пайплайн разными методами, было принято решение попробовать улучшить и сам тессеракт.
Инструкция от разработчиков https://tesseract-ocr.github.io/tessdoc/Home.html не всегда сразу понятна и очевидна, поэтому и появилась мысль записать свой опыт в эту статью.
У меня на компьютере стоит Linux Mint 20.2 Cinnamon, поэтому все действия происходят в этой системе и я не могу гарантировать, что все получится точно так же в Windows или Mac.
Для начала необходимо установить бибилиотеку tesseract на компьютер. Делается это достаточно просто. Сначала проверю версию, которая уже установлена (как правило в комплекте с Linux уже есть пакет tesseract). В терминале набираем

Компьютерное зрение решает задачи поиска, отслеживания и классификации объектов в самых разнообразных областях: промышленности, медицине, сфере безопасности. Одно из возможных новых применений компьютерного зрения — выявление атмосферных осадков при помощи видеокамер наружного наблюдения. О том, как можно реализовать такой алгоритм и поговорим в этом посте.
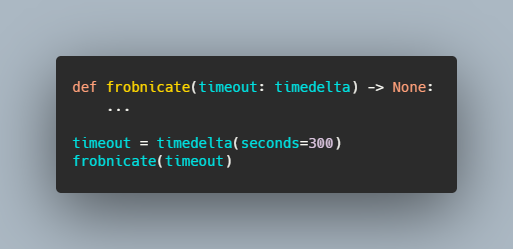
time.sleep(300)Thread.sleep(300)threadDelay 300time.sleep являются секунды, а threadDelay — микросекунды. Если вы часто ищете эту информацию, то рано или поздно её запомните, но как сохранить читаемость кода для людей, никогда не встречавшихся с time.sleep?
В случайно сгенерированном мире Minecraft найдём алмазы с помощью ИИ. Как обученный с подкреплением агент проявит себя в одной из самых сложных задач игры? Подробностями делимся к старту флагманского курса по Data Science.

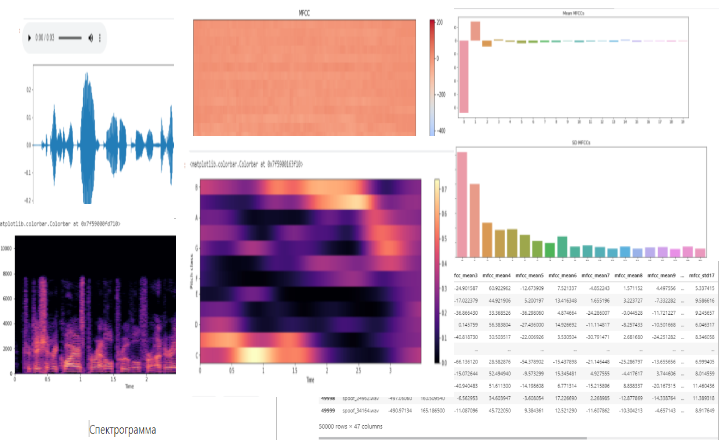
Каждый аудиосигнал содержит характеристики. Из MFCC (Мел-кепстральных коэффициентов), Spectral Centroid (Спектрального центроида) и Spectral Rolloff (Спектрального спада) я провела анализ аудиоданных и извлекла характеристики в виде среднего значения, стандартного отклонения и skew (наклон) с помощью библиотеки librosa.
Для классификации “живого” голоса (класс 1) и его отделению от синтетического/конвертированного/перезаписанного голоса (класс 2) я использовала алгоритм машинного обучения - SVM (Support Vector Machines) / машины опорных векторов. SVM работает путем сопоставления данных с многомерным пространством функций, чтобы точки данных можно было классифицировать, даже если данные не могут быть линейно разделены иным образом. Для работы я использовала математическую функцию, используемой для преобразования (известна как функция ядра) - RBF (радиальную базисную функцию).
В первой части анализа аудиоданных разберем:

Сегодня словосочетания вроде Data Science, Machine Learning, Artificial Intelligence очень популярны. При этом нередко под ними понимаются довольно разные вещи. Это зачастую смущает и запутывает людей, желающих войти в специальность: трудно разобраться, с чего начать, что действительно нужно, а что необязательно для начала. Не претендуя на общность, расскажем, как это видится на основе десятка лет опыта c решением такого рода задач для крупных клиентов со всего мира (сервис / заказная разработка / аутсорс – подставьте термин по вкусу).

Всем привет!
У меня была такая проблема что я каждый день когда ложился спать всегда ставил в нике преписку что то по типу [БУДУ ЗАВТРА В 8:00] так вот в какой то момент меня это доконало и я решил сделать так что бы скрипт сам делал мне эту преписку, но будет брать события с Google Calendar. Думаю это довольно удобно ведь так можно будет записывать в календарь все свои дела а скрипт будет автоматически ко времени преписывать их к нику.
давайте начнем!
и начнем мы с самого сложного, настройкой своего гугл аккаунта
заходим на этот сайт https://console.cloud.google.com/ входим в аккаунт гугл (не бойтесь его потерять, это официальный сайт гугла) и заполняем небольшую анкету:
первым делом мы видим такую картину

Привет, Хабр! Меня зовут Глеб. Я работаю в компании Friflex над проектами по оцифровке спорта. Работая над idChess (приложением для распознавания и аналитики шахматных партий), мы расширяем наш датасет синтетическими данными. В качестве движка используем Blender. В этой статье рассмотрим основы взаимодействия с объектами, получение доступа через API, перемещение, масштабирование и вращение.
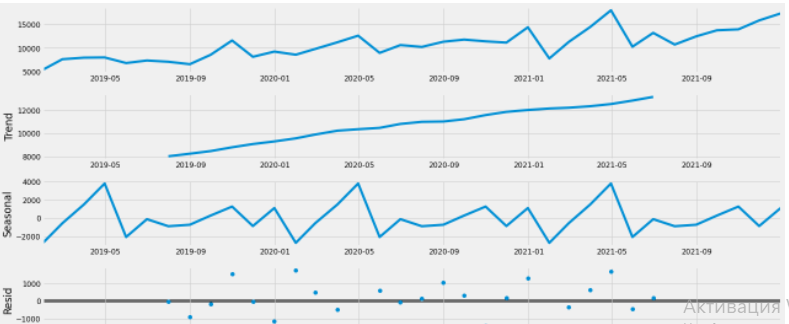
Как вы можете помнить по первой статье "Маркетинговая аналитика на Python. Пишем код для RFM-сегментации", более 8 лет я работаю в сфере маркетинга для B2B и примерно столько же бешусь от дилетантского подхода к аналитике, который тянет за собой ряд проблем с определением ключевых метрик эффективности для компании (и, как следствие, с мотивацией сотрудников):

В интернете можно найти 1000 и 1 статью по тренингу мнистовского датасета для распознавания рукописных чисел. Однако когда дело доходит до практики и начинаешь распознавать собственные картинки, то модель справляется плохо или не справляется вовсе. Преобразуем произвольное изображение числа под MNIST-овский датасет.
