
Геоаналитика с помощью Python и открытых данных: пошаговое руководство
11 мин
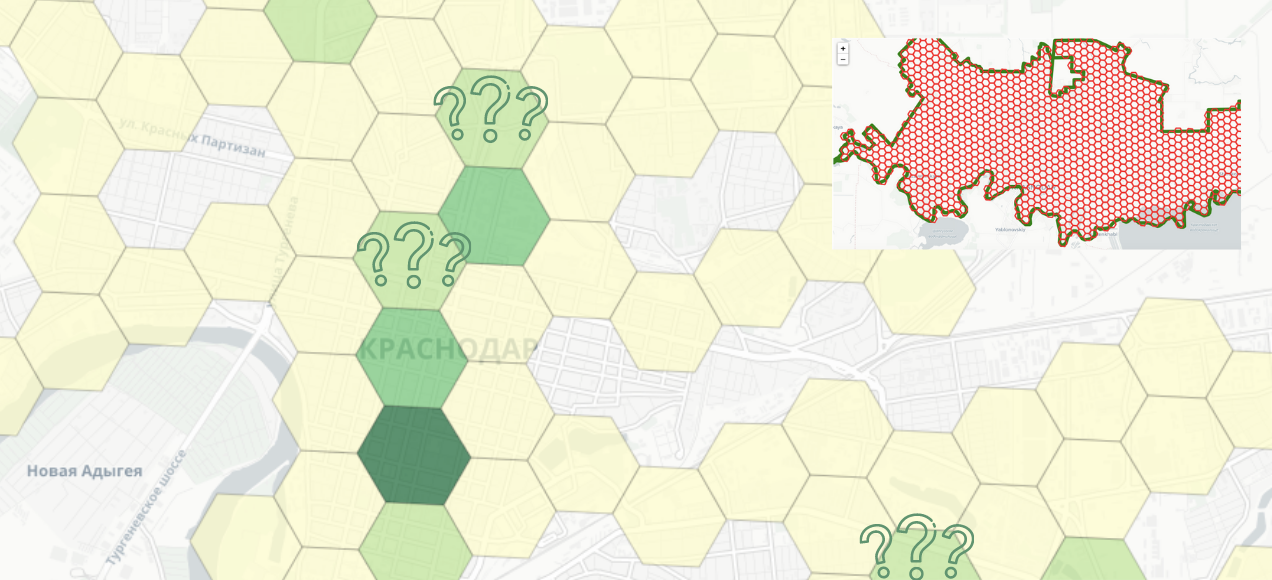
Геоаналитика с помощью Python: GeoPandas, folium, Uber H3, OSM + примеры как можно определять лучшие локации для поиска помещений под открытие кофейни (и не только).
Геоаналитика с помощью Python: GeoPandas, folium, Uber H3, OSM + примеры как можно определять лучшие локации для поиска помещений под открытие кофейни (и не только).

Привет, Хабр! Мы продолжаем рассказывать о новых трендах в BI, и сегодня речь пойдет о расширении возможностей аналитических систем и кастомизации дашбордов под конкретные (и порой уникальные) задачи клиентов. Для этого необходимо работать на стыке DS и BI, а значит — в BI должен быть базовый набор ML- инструментов (Machine Learning), доступных не только суровым математикам, но и бизнес-аналитикам. В этой статье мы рассмотрим возможные варианты пересечения сфер BI и DS для проведения более глубокой аналитики, с плюсами и минусами, а также покажем основные подходы к внедрению ML в BI на уровне стандартного функционала.

Недавно мы с девушкой серьезно поговорили и выяснилось, что я даже не пишу ей “С добрым утром” и вообще редко пишу по утрам. В целом, причина кроется в том, что я не просыпаюсь с восходом первых лучей солнца (как она), а переписываться не очень люблю. Ну а ей, конечно же, приятно получать нежности по утрам и все такое.
Я просто опишу как собрал бота для Instagram, которым движет только одно - слать сообщения в стиле "Привет, доброе утро" моей девушке. Ну, т. е. это не значит, что если кто-то запустит скрипт у себя, то сообщения снова полетят ей. Нет. Просто это бот с функцией отправки сообщений.

Подобный Python Triton уже работает в ядрах, которые в 2 раза эффективнее эквивалентных реализаций Torch. А ядра матричного умножения FP16, сравнимые производительностью с cuBLAS, на Triton займут менее 25 строк. Как утверждает автор, многие программисты не могут написать такие ядра. Подробностями о Triton делимся к старту курса по ML и DL.

DevOps-инженер Константин Кулишов рассказал, как создал свой ChatOps, чтобы дать разработчикам возможность вносить изменения в проект в любое время. Константин выложил ChatOps на GitHub и подробно описал процесс создания.
Сталкивались ли вы когда-либо с проблемой в обучении нейросетей, когда датасет слишком большой, чтобы загрузить его в оперативную память полностью и программа выдает Out-of-Memory Error? Например, при обучении классификатора изображений, у нас нет возможности загрузить все картинки в память до обучения. Даже если это и возможно для игрушечных наборов данных, в реальных задачах объёмы данных измеряются в сотнях, тысячах гигабайт. И мы не можем использовать лишь часть датасета, так как качество обученной модели тоже упадёт. Конечно, у нас есть возможность использовать готовые инструменты (например ImageDagaGenerator в библиотеке Tensorflow), но такой подход работает только если у нас стандартные данные, такие как папки с файлами jpg/png или csv файлы. А что делать, если у нас несколько различных типов данных (например, входные данные - это изображения и их текстовое описание), или большое количество табличных данных, где, например, каждый файл это данные за один день? В этих случаях для загрузки и подготовки данных на вход модели придётся писать свой собственный генератор данных.
В данной статье я детально расскажу, как я создавал свой DataGenerator в Kaggle соревновании по определению наличия опухоли головного мозга по МРТ.
Итак, посмотрим на данные, которые нам предоставили. Для обучения у нас имеется 585 примеров. Каждый пример представляет собой МРТ скан в четырех режимах: Fluid Attenuated Inversion Recovery (FLAIR), T1-weighted pre-contrast (T1w), T1-weighted post-contrast (T1Gd), T2-weighted (T2). Скан в каждом режиме представляет собой набор одноканальных изображений в формате DICOM. Возьмем один из примеров и посмотрим разрешение и количество файлов для каждого режима:

Я собрал умную коробку для круглогодичного выращивания клубники у себя на балконе. Расскажу как сделал управление освещением, поливом, отоплением, какие датчики использовал, с какими проблемами столкнулся и покажу результат.

Для начала нужно обзавестись этим самым "mesh"-ем поверхности, или триангуляцией поверхности, полигональной сеткой, разбиением двумерного многообразия. В данном случае работа будет вестись именно с треугольной сеткой, но все ниже представленные формулы и код (если немного модифицировать), будет работать с сеткой состоящей из любых полигонов. Главное, чтобы они были малые, от этого зависит точность, чем меньше - тем лучше.

На работе, в обеденный перерыв коллега показал игрушку на Яндекс играх – Филворды. Как то не заладилась игра у меня – вроде простые слова, но дело шло медленно. А у товарища уровень был выше 400. Первая мысль при таком фэйле – конечно, показать глупой машине, что есть кто-то умнее ее! То есть - другая машина…

Привет!
В прошлой статье мы познакомились с aiohttp и написали на нем свое первое веб-приложение: стену с отзывами.
В этой статье мы продолжим изучение и подключим к нашему приложению базу данных PostgreSQL, используя для этого Gino, SQLAlchemy и Aiopg, а также автоматически сгенерируем и применим миграции с помощью Alembic.
Если вам интересно асинхронное программирование, приходите к нам на курс в KTS, где мы гораздо подробнее разберем эту тему.

В настоящее время уже сложно найти крупную компанию, которая не использовала бы возможности накопления и использования больших данных. Меня зовут Никита Сурков и я работаю в проекте ценообразования "Пятёрочки" X5 Group. Проект является ярким примером использования больших данных, так как Пятёрочка -- это 18000 магазинов по всей стране. Чтобы построить систему ценообразования в такой сети требуется обработка миллиардов строк информации из чеков, данных по остаткам, себестоимостей и многих других данных. Для всего этого преимущественно используется PySpark, как один из популярных инструментов для работы с расперделёнными системами. В данной статье будет представлен один из методов написания кода на PySpark таким образом, чтобы он был более читаем, легко тестируем и поддерживаем. Сразу оговорюсь, что не представляю здесь единственное правильное решение, но оно доказало свою жизнеспособность на примере того проекта, в котором я работал.


Рассмотрим пример простой программы на Python с помощью библотекы docx для автоматизации рабочего процесса, а именно автоматической вставки файлов (в данном случае изображений) и их подпись в документах Word (docx).
Данная статья будет интересна для начинающих изучающих Python, а также полезна для тех кто работает с большими объемами изображений, графиков, осциллограмм и тому подобное. В ней мы рассмотрим простой и удобный способ вставки изображений в Word и их подписью с помощью Python.
Редактирования кода займет 5 минут, выполнение программы займет 5 секунд. Вы сэкономите 300 минут работы.
Я опишу свой максимально дубовый и непрофессиональный но простой код который Вы сможете повторить в своих проектах. (Полный код в низу статьи).

Привет, друзья!
Я — JavaScript-разработчик. Код пишу в основном на React (иногда на Vue), немного на TypeScript, немного на Node, немного знаю SQL, но...
PythonPythonPythonPython (раньше Гугл тоже его любил, но теперь у него есть Go)Короче говоря, сложно было не заинтересоваться Python.
Как известно, лучший способ научиться "кодить" — это писать код.
Предлагаю вашему вниманию 50 популярных в сфере программирования задач, решенных с помощью Python и JavaScript.
Цель — сравнить языки на предмет предоставляемых ими возможностей.
Задачки не очень сложные, хотя имеется парочка из категории продвинутых.
Предполагается, что вы владеете хотя бы одним из названных языков на среднем уровне.

Компьютерное зрение — очень интересная и востребованная область искусственного интеллекта. Компьютерное зрение сейчас используется повсеместно, начиная от сегментации медицинских изображений, заканчивая управлением автомобилем. Сейчас мы коснемся одной из основных задач компьютерного зрения — обнаружения объектов.
Множество информации хранится в форме сканированных документов. Извлечь текст можно при помощи методов оптического распознавания. Но если нас интересует структурированная информация, например, таблицы, то ограничиться методами оптического распознавания мы не сможем.
Для того, чтобы извлечь информацию из таблицы, нужно в первую очередь эту таблицу найти. С этой проблемой нам поможет справиться PyTorch и готовая модель Fast-RCNN из библиотеки torchvision. Примеры ее использования, можно прочитать в официальной документации или, например, в этом руководстве.
Данные для обучения возьмем с github. Все действия будем производить в облачном сервисе Google Colaboratory.
Извлечем нужные библиотеки.

Привет, Хабр! Меня зовут Сергей Радченко, и мы с командой профессионально занимаемся тестированием уже несколько лет. Сегодня я посчитал количество автотестов, которые мы подготовили для веб-интерфейсов, десктопных приложений, API, систем двухфакторной авторизации и так далее (их оказалось более 5000). И мне захотелось рассказать о нашем опыте создания экосистемы для автоматизированного тестирования. В этом посте вы найдете описание полезных для комплексного тестирования фреймворков, а также исходный код некоторых дополнительных методов, которые мы дописали самостоятельно, чтобы написание тестов происходило быстрее, и тестирование приносило больше пользы.

Добрый день, сегодня мы развернем serverless инфраструктуру на базе AWS lambda для загрузки изображений (или любых файлов) с хранением в приватном AWS S3 bucket. Использовать мы будем terraform скрипты, залитые и доступные в моем репозитории kompotkot/hatchery на GitHub.
Предложенный подход позволяет экономить на содержании сервера, обезопасить процессинг файлов внутри инфраструктуры компании и оптимизировать хранение файлов.
В целях упрощения мы воспользуемся функционалом Bugout.dev Resources, в нашем примере выполняющий функцию удаленной базы данных для хранения записей о принадлежности файла к заметки.

Пусть у нас есть картофель фри, котлета, хлеб, помидор, огурец и молочный коктейль. Сколько чего нужно съесть, чтобы получилось 30 гр. белка, 25 гр. жиров и 60 гр. углеводов? В прошлый раз я баловался и пытался решить это с помощью матриц, на этот раз - с помощью линейных уравнений и python библиотеки PuLP.
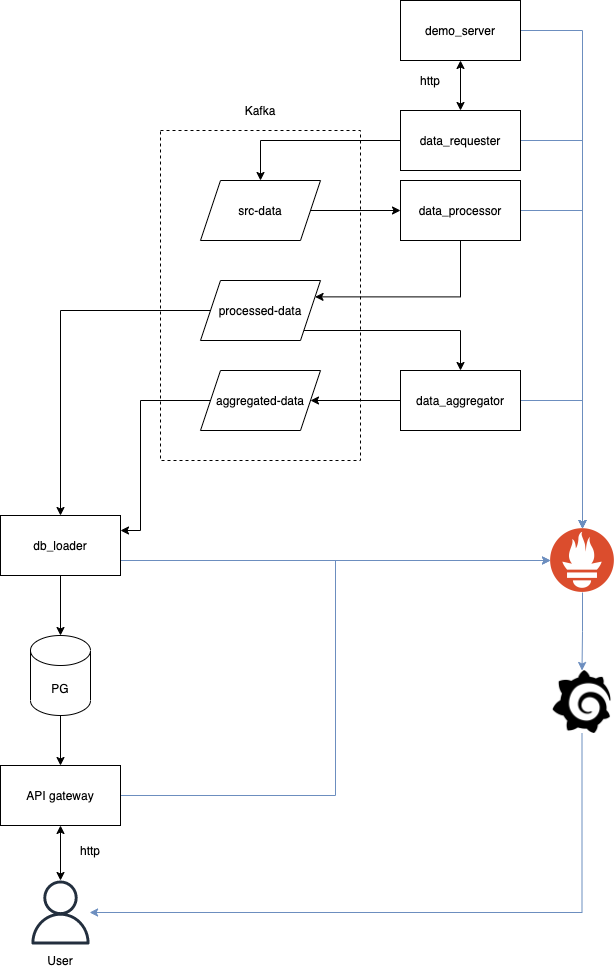
В этой статье я бы хотел поделиться способом написания асинхронных микросервисов на Python, в основе которых библиотека Faust. А в качестве брокера сообщений Kafka. Ну и немного мониторинга с Prometheus и Grafana.