Сложный был год: налоги, катастрофы, бандитизм и стремительное исчезновение малых языков. С последним мириться было нельзя...
Upd. 04.12.2021 — Наш телеграм канал
На территории России проживает большое количество народов, говорящих более чем на 270 языках. Около 150 языков насчитывает менее 1 тысячи носителей, а за последние 20 лет 7 языков уже исчезло.
Этот проект — мои "пять копеек" по поддержке языкового разнообразия. Его цель — помощь исследователям в области машинного перевода, лингвистам, а также энтузиастам, радеющим за свой родной язык. Помогать будем добыванием параллельных корпусов, — своеобразного "топлива", при помощи которого современные модели все успешнее пытаются понять человеческий язык.
Сегодняшние языки — башкирский и чувашский, с популяризаторами которых я в последнее время тесно общался. Сначала я покажу как в принципе извлечь корпус из двух текстов на разных языках. Затем мы столкнемся с тем, что на рассматриваемых языках предобученная модель не тренировалась и попробуем ее дообучить.
Экспериментировать мы будем в среде Colab'а, чтобы любой исследователь при желании смог повторить этот подход для своего языка.
I. Извлекаем параллельный корпус
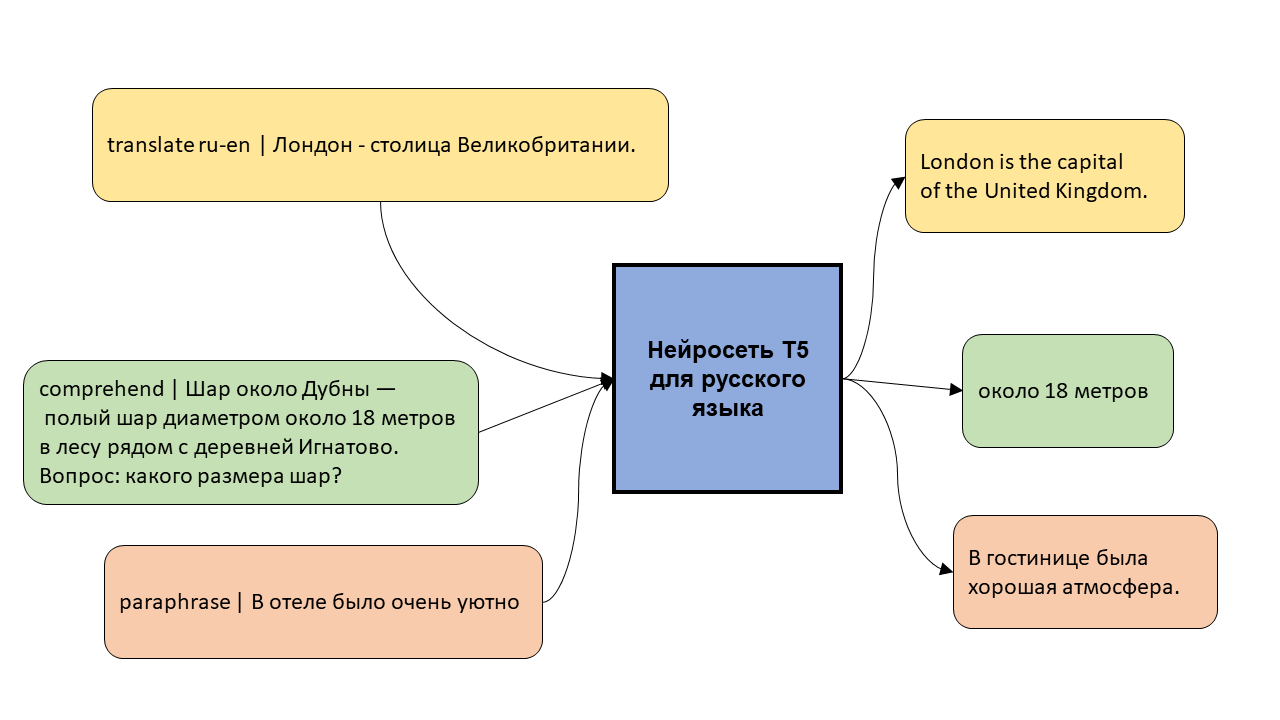
Для выравнивания двух текстов я написал на python'е библиотеку lingtrain_aligner. Код у нее открыт. Она использует ряд предобученных моделей, можно подключать и свои. Одной из самых удачных мультиязыковых моделей сейчас является LaBSE. Она обучалась на 109 языках. Так как соотношение текстов смещено в сторону популярных языков, то для них качество эмбеддингов (эмбеддингом называют вектор чисел применительно к данным, которые он описывает) будет лучше.
Colab
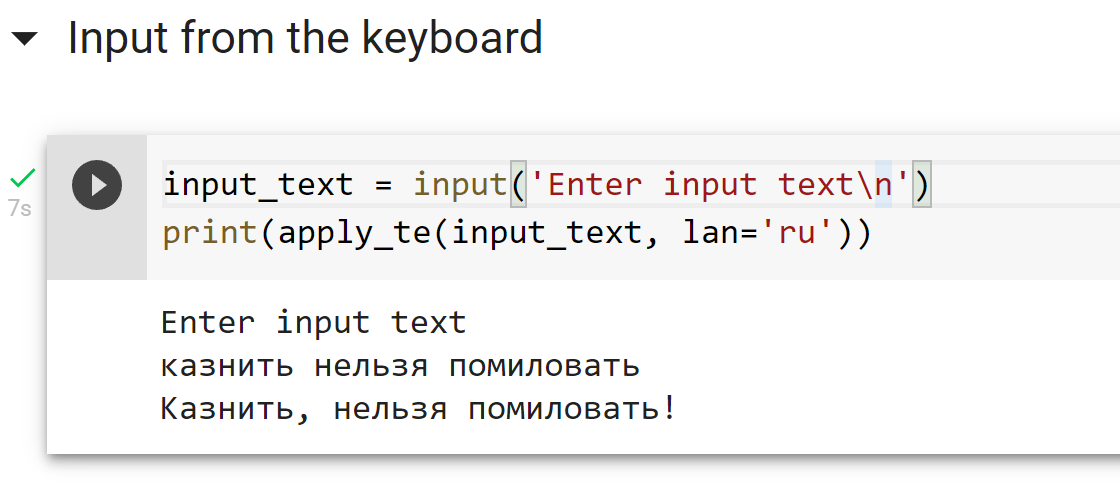
Попробовать извлечь корпус на нужном языке можно в этом Colab'e. Дальше пройдемся по шагам более подробно.
Установка
Установим библиотеку командой
pip install lingtrain_aligner