Как мы используем цепи Маркова в оценке решений и поиске багов. Со скриптом на Python
6 мин
Нам важно понимать, что происходит с нашими студентами во время обучения, и как эти события влияют на результат, поэтому мы выстраиваем Customer Journey Map — карту клиентского опыта. Ведь процесс обучения — не нечто непрерывное и цельное, это цепочка взаимосвязанных событий и действий студента, причем эти действия могут сильно отличаться у разных учеников. Вот он прошел урок: что он сделает дальше? Пойдет в домашнее задание? Запустит мобильное приложение? Изменит курс, попросит сменить учителя? Сразу зайдет в следующий урок? Или просто уйдет разочарованным? Можно ли, проанализировав эту карту, выявить закономерности, приводящие к успешному окончанию курса или наоборот, «отваливанию» студента?
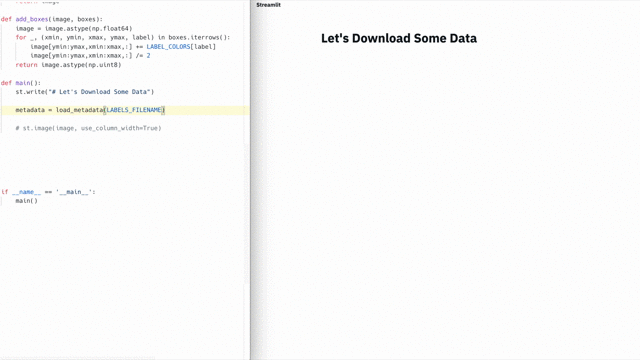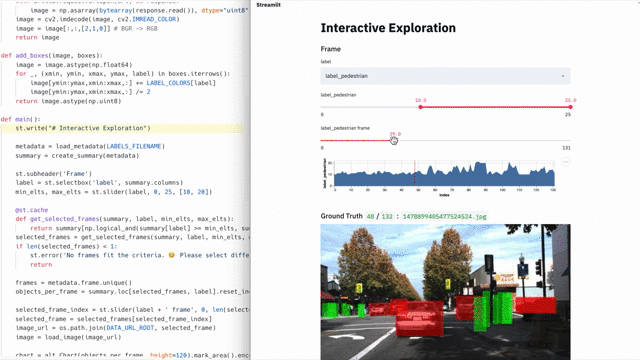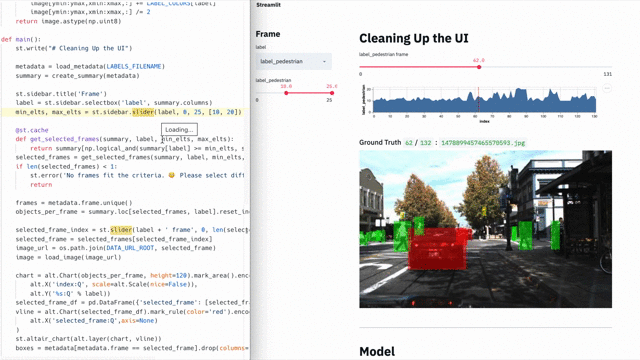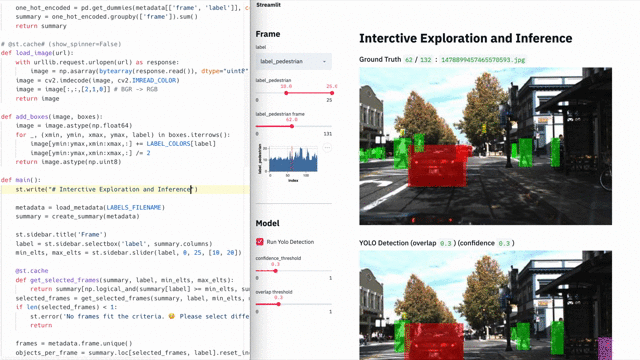
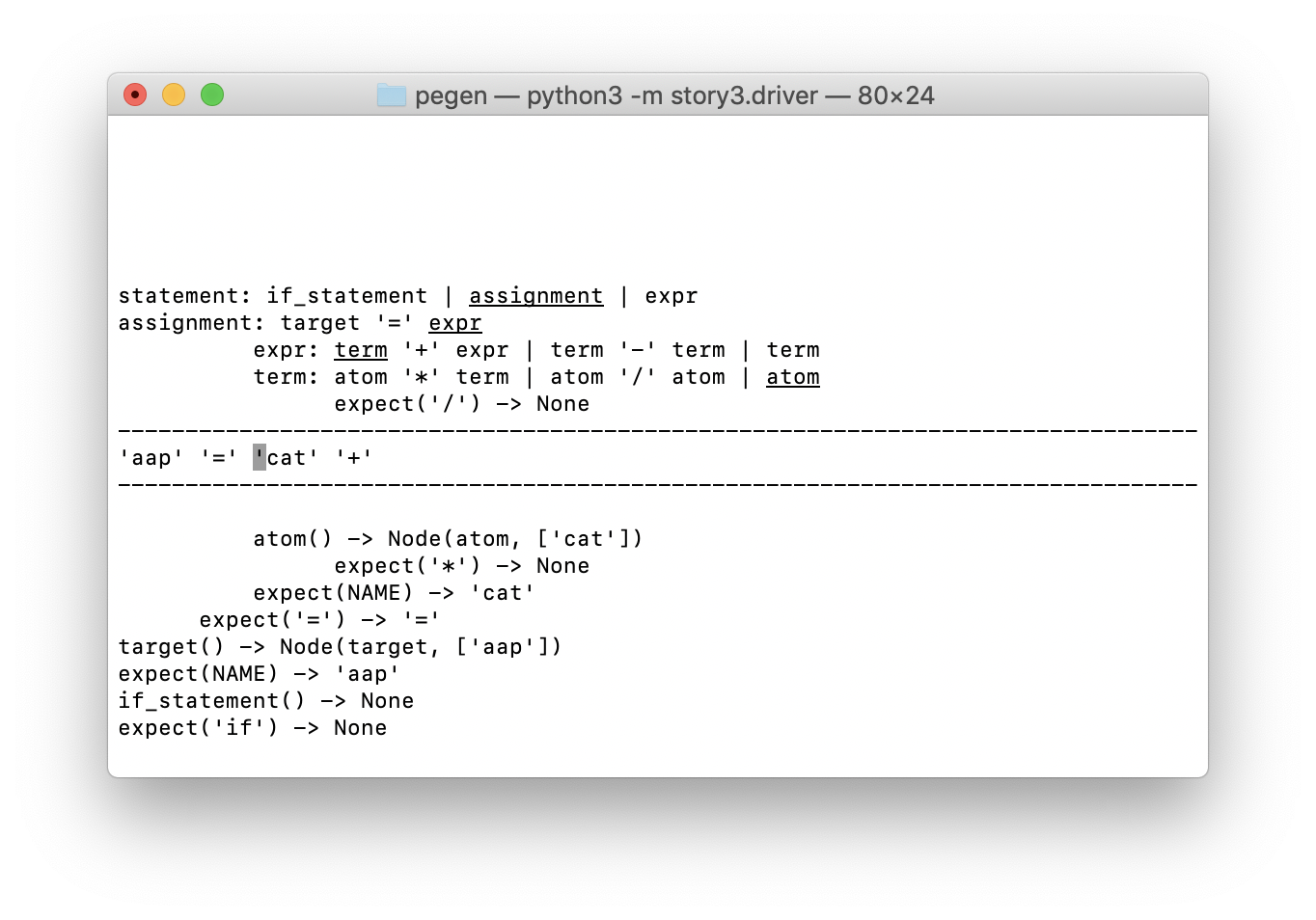
Обычно для выстраивания CJM используют специализированные, весьма дорогие инструменты с закрытым кодом. Но нам хотелось придумать что-то простое, требующее минимальных усилий и по возможности опенсорсное. Так появилась идея воспользоваться цепями Маркова — и у нас получилось. Мы построили карту, интерпретировали данные о поведении студентов в виде графа, увидели совершенно неочевидные ответы на глобальные вопросы бизнеса и даже нашли глубоко спрятанные баги. Все это мы сделали с помощью опенсорсных решений Python-скрипта. В этой статье я расскажу про два кейса с теми самыми неочевидными результатами и поделюсь скриптом со всеми желающими.
Обычно для выстраивания CJM используют специализированные, весьма дорогие инструменты с закрытым кодом. Но нам хотелось придумать что-то простое, требующее минимальных усилий и по возможности опенсорсное. Так появилась идея воспользоваться цепями Маркова — и у нас получилось. Мы построили карту, интерпретировали данные о поведении студентов в виде графа, увидели совершенно неочевидные ответы на глобальные вопросы бизнеса и даже нашли глубоко спрятанные баги. Все это мы сделали с помощью опенсорсных решений Python-скрипта. В этой статье я расскажу про два кейса с теми самыми неочевидными результатами и поделюсь скриптом со всеми желающими.