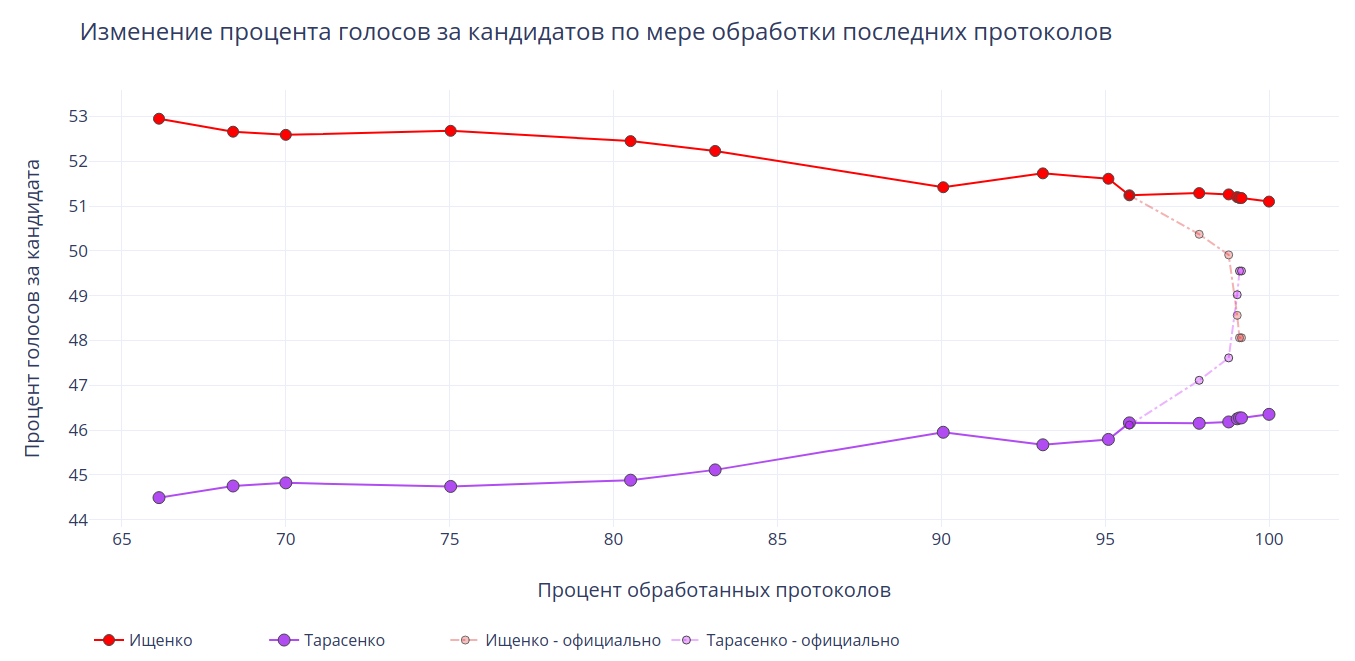
Django 3.0 будет асинхронным
Andrew Godwin опубликовал DEP 0009: Async-capable Django 9 мая, а 21 июля он был принят техническим советом Django, так что можно надеяться, что к выходу Django 3.0 успеют сделать что-нибудь интересное. Он уже упоминался где-то в комментариях Хабра, но я решил донести эту новость до более широкой аудитории путём его перевода — в первую очередь для тех, кто, как и я, не особо следит за новостями Django.
Асинхронный Python разрабатывался много лет, и в экосистеме Django мы экспериментировали с ним в Channels с ориентацией в первую очередь на поддержку вебсокетов.
По мере развития экосистемы стало очевидно, что, хотя нет насущной необходимости расширять Django для поддержки отличных от HTTP протоколов, таких как вебсокеты, поддержка асинхронности даст много преимуществ для традиционной model-view-template структуры Django.
Преимущества описаны в разделе «Мотивация» ниже, но общий вывод, к которому я пришёл, заключается в том, что мы получим так много от асинхронного Django, что это стоит того большого труда, который потребуется. Я также считаю, что очень важно делать изменения итеративным, поддерживаемым сообществом путём, который не будет зависеть от одного-двух старых контрибьюторов, которые могут выгореть.