Реализация целого типа в CPython
7 мин
На Хабре уже были статьи о подробностях реализации менеджера памяти CPython, Pandas, я написал статью про реализацию словаря.
Казалось бы, что можно написать про обычный целочисленный тип? Однако тут не всё так просто и целочисленный тип не такой уж и очевидный.
Если вам интересно, почему x * 2 быстрее x << 1.
И как провернуть следующий трюк:
То вам стоит ознакомиться с данной статьёй.
Казалось бы, что можно написать про обычный целочисленный тип? Однако тут не всё так просто и целочисленный тип не такой уж и очевидный.
Если вам интересно, почему x * 2 быстрее x << 1.
И как провернуть следующий трюк:
>>> 42 == 4
True
>>> 42
4
>>> 1 + 41
4
То вам стоит ознакомиться с данной статьёй.


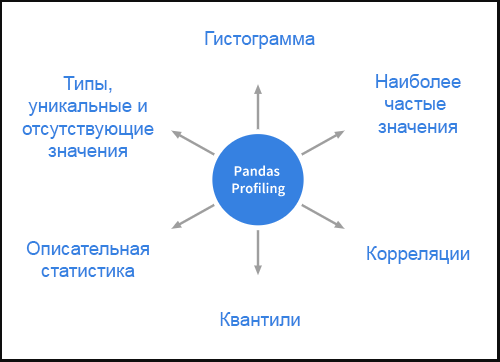


 Перед вами – перевод свободной онлайн-книги Майкла Нильсена «Neural Networks and Deep Learning», распространяемой под лицензией
Перед вами – перевод свободной онлайн-книги Майкла Нильсена «Neural Networks and Deep Learning», распространяемой под лицензией