Хабрарейтинг: построение облака русскоязычных слов на примере заголовков Хабра
5 мин
Привет, Хабр.
В последней части Хабрарейтинга был опубликован метод построения облака слов для англоязычных терминов. Разумеется, задача парсинга русских слов является гораздо более сложной, но как подсказали в комментариях, для этого существуют готовые библиотеки.
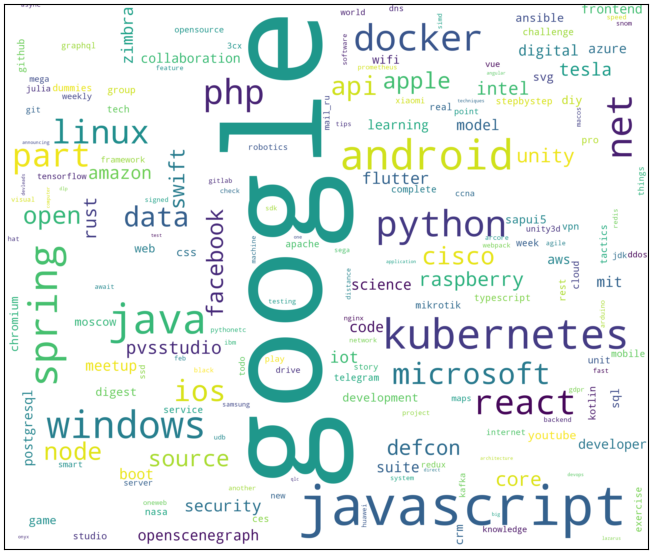
Разберемся, как строить такую картинку:

Также посмотрим облако статей Хабра за все годы.
Кому интересно, что получилось, прошу под кат.
В последней части Хабрарейтинга был опубликован метод построения облака слов для англоязычных терминов. Разумеется, задача парсинга русских слов является гораздо более сложной, но как подсказали в комментариях, для этого существуют готовые библиотеки.
Разберемся, как строить такую картинку:
Также посмотрим облако статей Хабра за все годы.
Кому интересно, что получилось, прошу под кат.