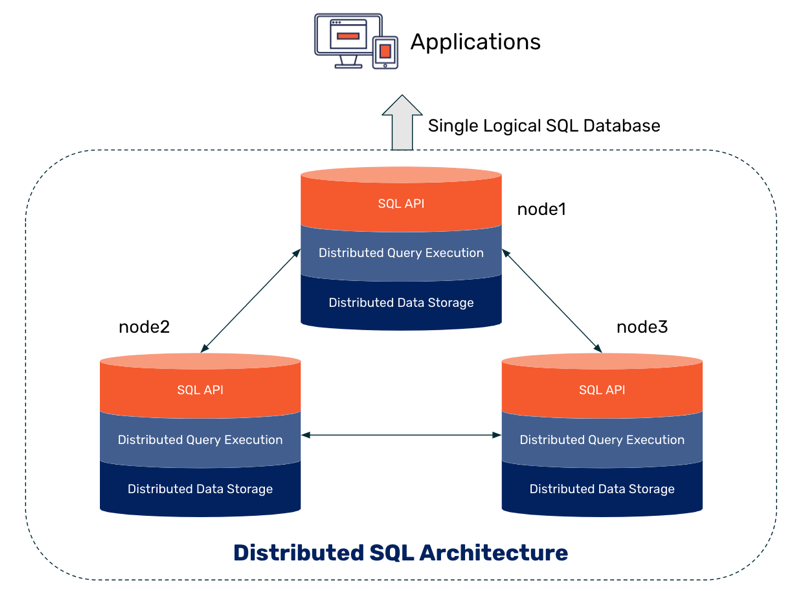
При выборе баз данных для текущего проекта (или при замене тех, которые не отвечают вашим текущим потребностям) количество возможных вариантов очень велико. Это и хорошо, и плохо, ведь нужны какие-то критерии фильтрации.
Сегодня есть гораздо больше баз данных, чем когда-либо. В декабре 2012 года, когда DB-Engines.com впервые начал ранжировать базы данных, у него получился список из
73 систем (существенный рост по сравнению с самым первым списком из
18 систем). Спустя десять лет, на декабрь 2022 года в списке было уже
почти четыреста систем. За последнее десятилетие произошёл настоящий кембрийский взрыв технологий баз данных. Нужно ориентироваться в обширном пространстве вариантов: SQL, NoSQL, множество «многомодельных» баз данных, которые могут быть сочетанием SQL и NoSQL, или множественные модели данных NoSQL (сочетающие две или более опций: документы, ключи-значения, широкие столбцы, графы и так далее).
Кроме того, пользователи не должны путать
популярность с
применимостью для них. Хотя сетевой эффект имеет свои преимущества («Все пользуются X, поэтому не ошибусь, если выберу её»), он также может привести к
групповому мышлению, торможению инноваций и конкуренции.
Мы с моим коллегой Артуром Песа недавно рассмотрели
пять факторов, которые пользователи должны учитывать в первую очередь при выборе и сравнении баз данных.