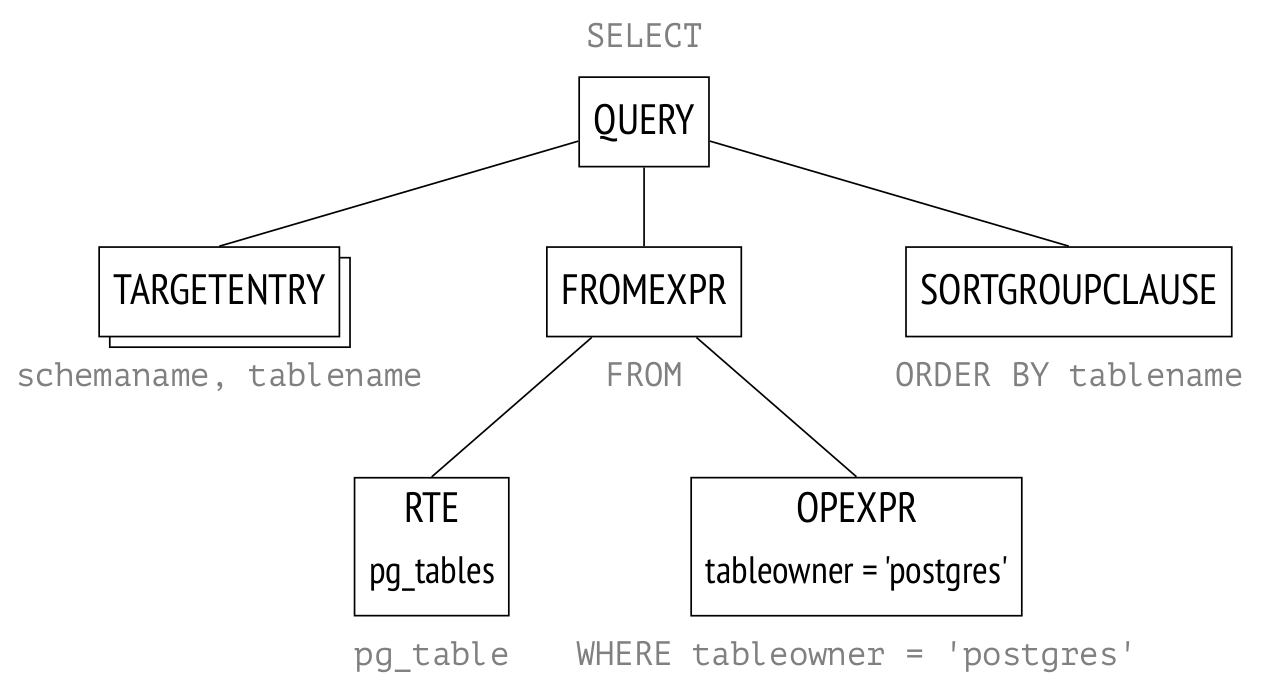
У вас бывают в разработке такие периоды, когда что-то в коде идет не так, ты ищешь баг, а потом оказывается, что за ним стоял еще один баг? Мне нравится искать баги. Это создает ощущение словно ты Шерлок Холмс и являешься главным героем в детективе, где кто-то из обширного списка на вид безобидных классов и функций вызывает неожиданное и даже неопределенное поведение программы, а ты своим зорким взглядом и экспериментами пытаешься вычислить этого мерзавца в кратчайшие сроки.
Можно выделить несколько стадий поиска бага:
• удивление (не знаю как вы, но я каждый раз как в первый раз удивляюсь когда что-то вдруг в моем коде работает не так, как ожидается);
• обвинение всех кругом в баге (коллег по проекту, github, сторонние либы, компилятор), но только не себя;
• смирение с тем, что возможно баг появился из-за меня и поиск бага: анализ выдаваемого результата, локализация ошибки, эксперименты с входными данными; в общем, все, что делает нормальный детектив, только в сфере программирования;
• если причина бага найдена быстро, то я хвалю себя за то, что нашел баг, при этом, я не напоминаю себе, что причиной бага стал тоже я, а не коллеги по проекту, не github, не сторонние либы и не компилятор;
• если причина бага все время ускользает, то приятное ощущение того, что ты суперпупердетектив сменяется глупой злостью, и чем дольше я не могу найти причину бага, тем больше я злюсь. И вот такие истории почему-то всегда запоминаются больше всех. Об одной такой истории я вам как раз хочу поведать.