Три года назад Виктор Тарнавский и Алексей Миловидов из Яндекса на сцене
HighLoad++ рассказывали, какой ClickHouse хороший, и как он не тормозит. А на соседней сцене был
Александр Зайцев с
докладом о переезде на
ClickHouse с другой аналитической СУБД и с выводом, что
ClickHouse, конечно, хороший, но не очень удобный. Когда в 2016 году компания
LifeStreet, в которой тогда работал Александр, переводила мультипетабайтовую аналитическую систему на
ClickHouse, это была увлекательная «дорога из желтого кирпича», полная неведомых опасностей —
ClickHouse тогда напоминал минное поле.
Три года спустя
ClickHouse стал гораздо лучше — за это время Александр основал компанию Altinity, которая не только помогает переезжать на
ClickHouse десяткам проектов, но и совершенствует сам продукт вместе с коллегами из Яндекса. Сейчас
ClickHouse все еще не беззаботная прогулка, но уже и не минное поле.
Александр занимается распределенными системами с 2003 года, разрабатывал крупные проекты на
MySQL, Oracle и
Vertica. На прошедшей
HighLoad++ 2019 Александр, один из пионеров использования
ClickHouse, рассказал, что сейчас из себя представляет эта СУБД. Мы узнаем про основные особенности
ClickHouse: чем он отличается от других систем и в каких случаях его эффективнее использовать. На примерах рассмотрим свежие и проверенные проектами практики по построению систем на
ClickHouse.

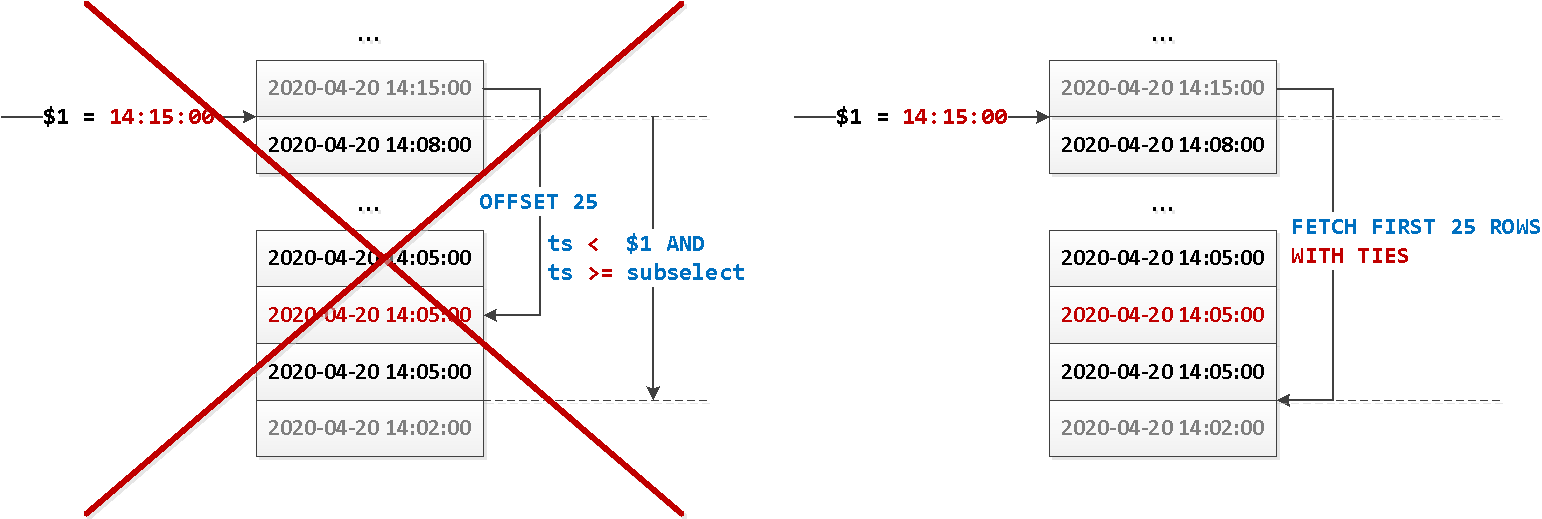


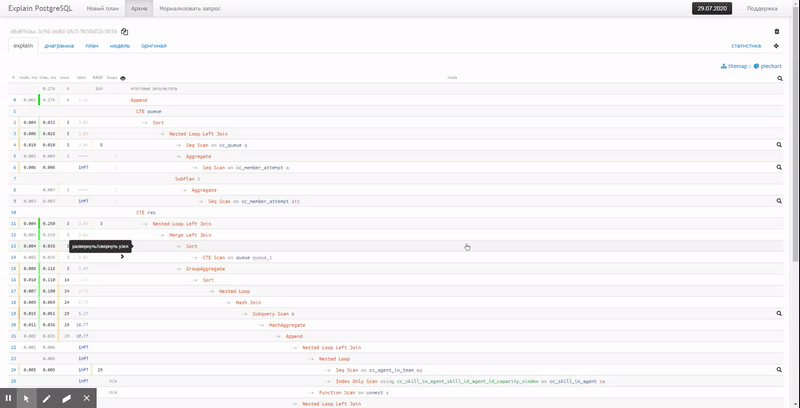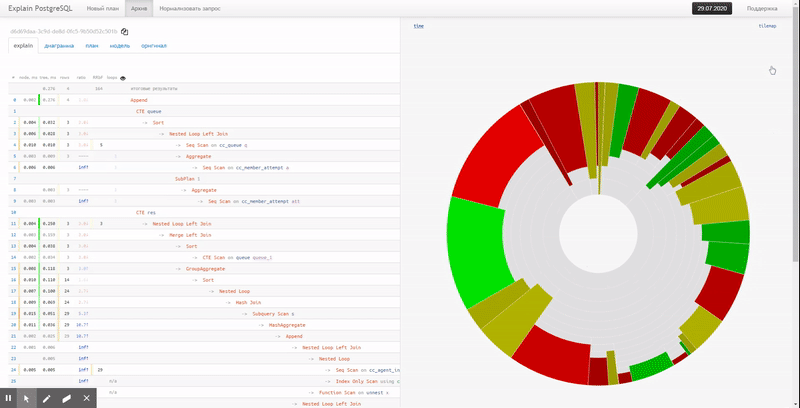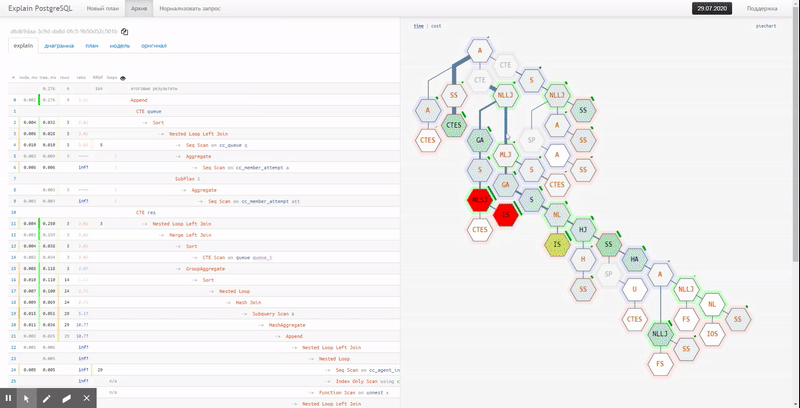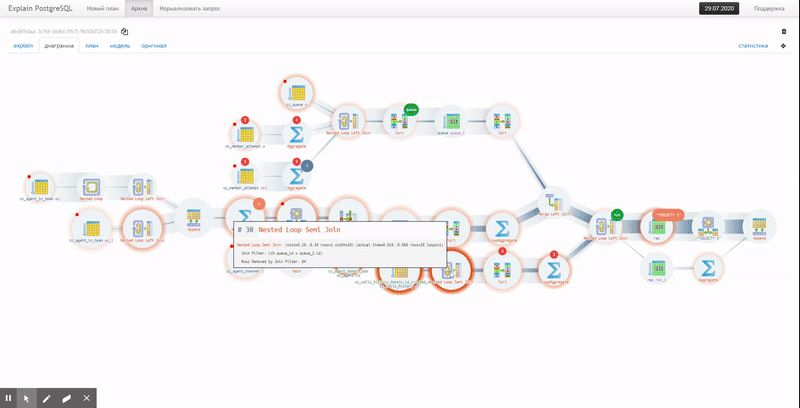

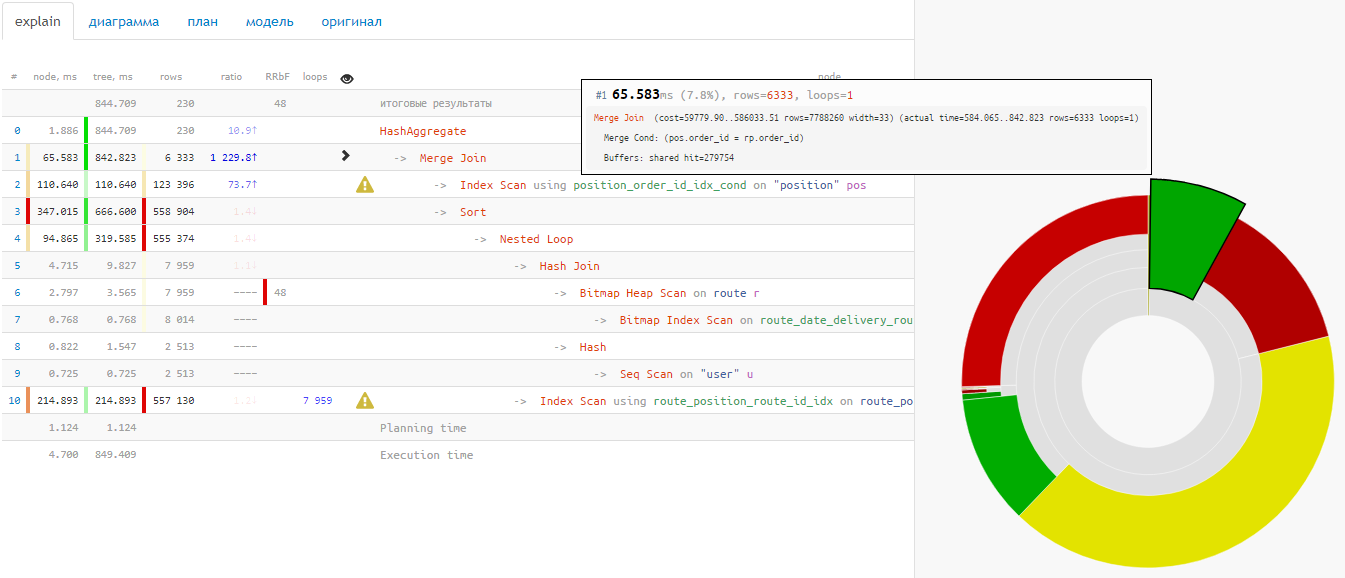




 Существует ли в мире очень большая и крупная база данных, которая время от времени не страдает от проблем с производительностью? Держу пари, что их не так уж много. Поэтому каждый DBA (администратор базы данных), отвечающий за PostgreSQL, должен знать, как отслеживать потенциальные проблемы производительности, чтобы выяснить, что на самом деле происходит.
Существует ли в мире очень большая и крупная база данных, которая время от времени не страдает от проблем с производительностью? Держу пари, что их не так уж много. Поэтому каждый DBA (администратор базы данных), отвечающий за PostgreSQL, должен знать, как отслеживать потенциальные проблемы производительности, чтобы выяснить, что на самом деле происходит.