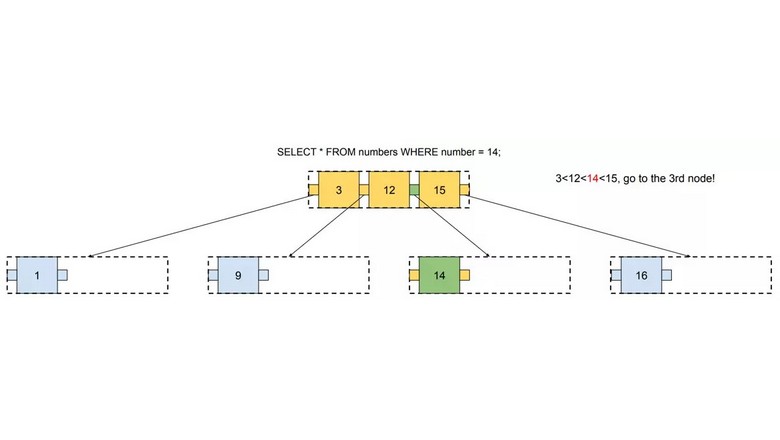
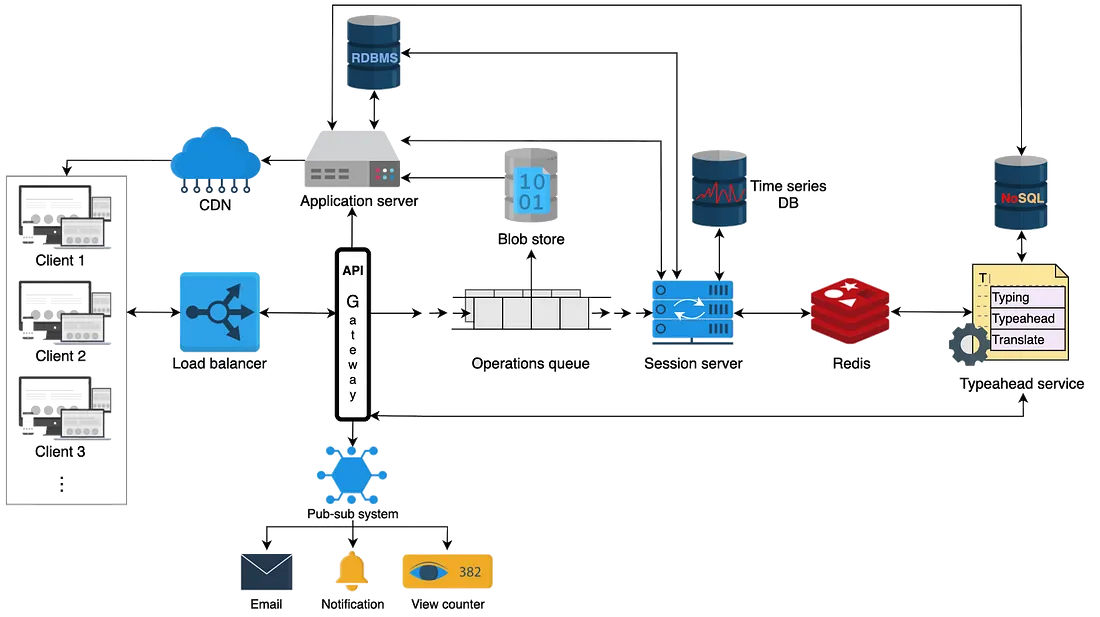
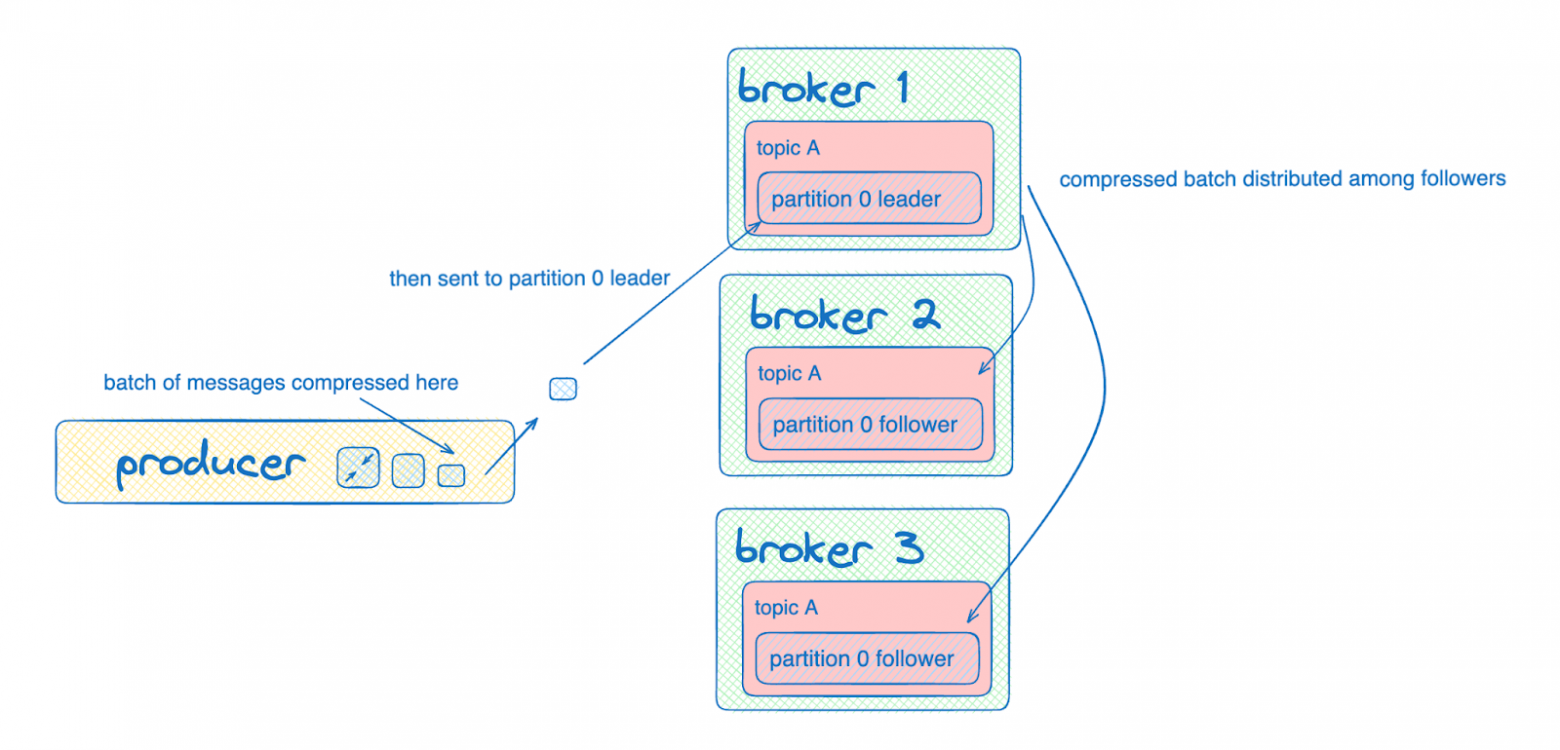
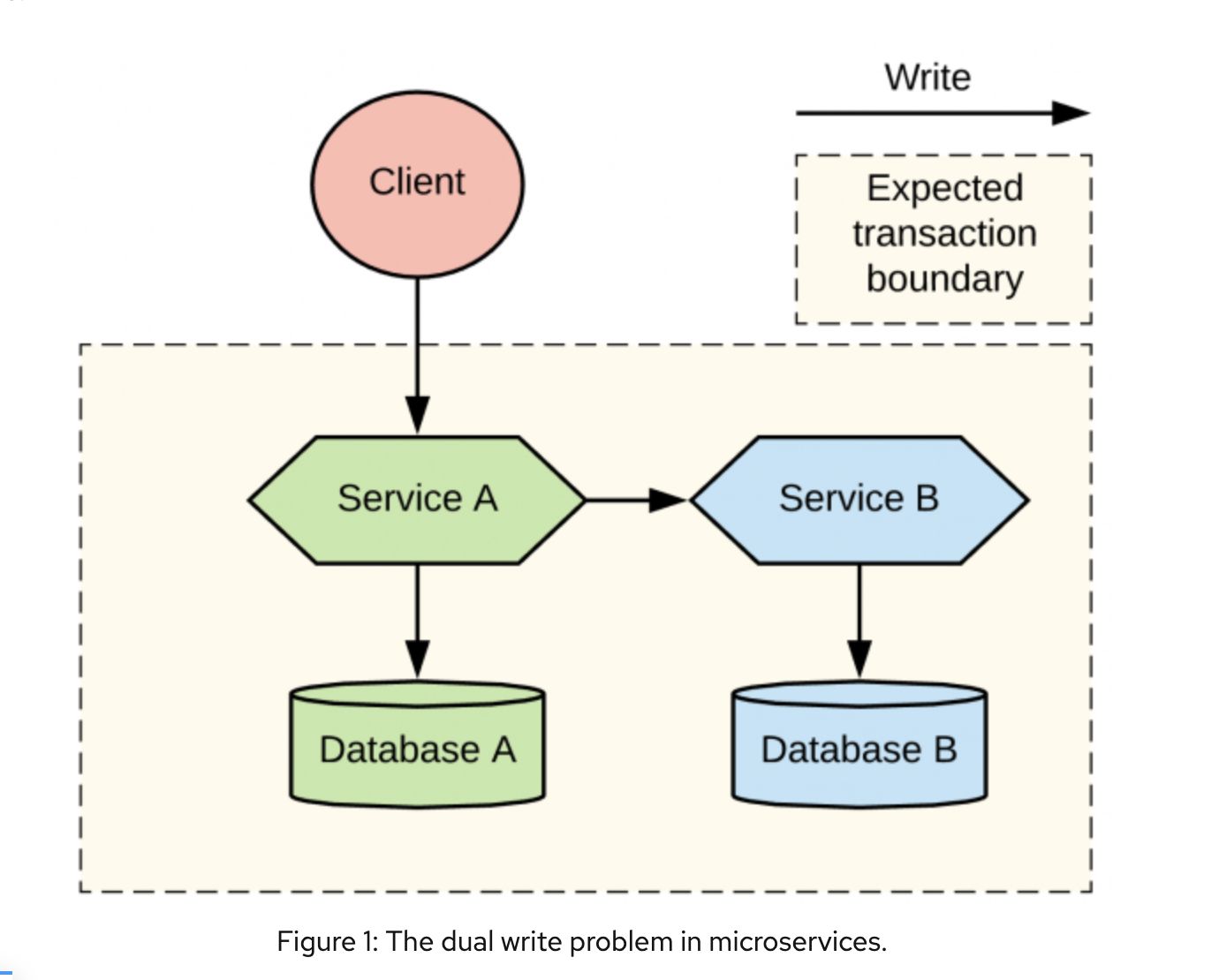
Привет! Меня зовут Владислав Попов, я автор курса «Go-разработчик» Яндекс Практикума. Когда-то я сам был студентом — хотел учиться Go, но такого курса в Практикуме не было, поступил на Python. Прошёл вводную часть — и тут стартовал желанный курс по Go. В тот же вечер оформил возврат и перепоступил. Попал в первый поток, прошёл его, и после сдачи итогового проекта мне предложили стать тестером курса «Продвинутый Go-разработчик».
Оба курса были ещё не идеальны — что-то требовало доработки, некоторые темы казались мне недостаточно раскрытыми. Я сообщил об этом команде курса и предложил варианты, что можно улучшить. В какой-то момент о них узнал продакт-менеджер — и так я получил приглашение поработать с командой Практикума. Мне предстояло разработать концепцию и внести предложения по рефакторингу курса, но я сделал бросок пантеры и написал несколько уроков с нуля. Команде они понравились. Так я стал работать в Практикуме.
За время работы с Go я понял, что сам язык не очень сложный и подходит даже в качестве первого, но нужно выучить синтаксис и погрузиться в некоторые особенности, которые отличают Go от других языков: например, интерфейсы и особенности встраивания. А ещё важно на старте хорошо знать Git и ориентироваться в работе SQL (причём любого).
Эта подборка составлена менторами нашего курса по Go-разработке для практикующих программистов. Она родилась благодаря коллективному разуму наших наставников, которые занимают позиции синьор-разработчиков на Go в разных компаниях.