Всем привет. В этой статье я опишу свой опыт настройки и использования sway — тайлингового оконного менеджера для Linux.

Илья @Areldar
Пользователь
Под капотом Graveyard Keeper: Как реализованы графические эффекты
5 мин
Всем привет! Целых 4 года я не писал на Хабр. Последняя моя серия постов была о различных инструментах и приемах, которые мы применяли на нашей прошлой игре (разрабатывая ее на Unity). С тех пор игру ту мы благополучно выпустили, а также выпустили и новую. Так что теперь можно немного выдохнуть и написать несколько новых статей, которые могут быть кому-то полезны.

Сегодня я хочу рассказать о графических приемах и ухищрениях, которые мы применяли для создания той картинки, которую вы видите на гифке выше.
Мы очень трепетно относимся к визуалу наших игр и по этому вложили довольно много времени и сил в различные эффекты и прочие плюшки, которые позволили бы сделать наш пиксель-арт максимально привлекательным. Возможно, кто-то найдет что-то полезное для себя.
Для начала, кратко перечислю из чего собирается картинка в нашей игре:
Сегодня я хочу рассказать о графических приемах и ухищрениях, которые мы применяли для создания той картинки, которую вы видите на гифке выше.
Мы очень трепетно относимся к визуалу наших игр и по этому вложили довольно много времени и сил в различные эффекты и прочие плюшки, которые позволили бы сделать наш пиксель-арт максимально привлекательным. Возможно, кто-то найдет что-то полезное для себя.
Для начала, кратко перечислю из чего собирается картинка в нашей игре:
Псевдослучайность нам поможет: подборка инструментов генерации ассетов для игры
3 мин
Перевод
Отгремели выстрелы минувшего Ludum Dare 44, но тяга делать игры, оттачивать свое мастерство ещё не покидает меня, да и думаю многих. Проглядывая главную страницу онлайн-мероприятия, я наткнулся на интереснейший пост, где автор задался вопросом составления инструментария, помогающего разработчикам (командам) создавать свои игровые шедевры. В статье автор задался целью собрать в один список набор инструментов, псевдо-случайным образом генерирующих различные ресурсы для вашей игры, начиная от фиксированной палитры цветов, заканчивая простейшей chiptune-like фоновой музыкой и спрайтами персонажей.

Под катом перевод данной заметки, с небольшими комментариями и примечаниями от себя.
Пишем и сводим альбом под Linux (Ubuntu 16.04, Ardour, Hydrogen, Kontakt)
1 мин
Туториал
Привет, с вами снова группа, которая записывает и сводит песни на лицензионном, преимущественно свободном ПО. В этот раз — в видеоформате + ссылки на файлы проектов в Ardour. В предыдущих сериях:
Что внутри XGBoost, и при чем здесь Go
7 мин
В мире машинного обучения одними из самых популярных типов моделей являются решающее дерево и ансамбли на их основе. Преимуществами деревьев являются: простота интерпретации, нет ограничений на вид исходной зависимости, мягкие требования к размеру выборки. Деревья имеют и крупный недостаток — склонность к переобучению. Поэтому почти всегда деревья объединяют в ансамбли: случайный лес, градиентный бустинг и др. Сложными теоретическими и практическим задачами являются составление деревьев и объединение их в ансамбли.
В данной же статье будут рассмотрены процедура формирования предсказаний по уже обученной модели ансамбля деревьев, особенности реализаций в популярных библиотеках градиентного бустинга
В данной же статье будут рассмотрены процедура формирования предсказаний по уже обученной модели ансамбля деревьев, особенности реализаций в популярных библиотеках градиентного бустинга
XGBoost и LightGBM. А так же читатель познакомится с библиотекой leaves для Go, которая позволяет делать предсказания для ансамблей деревьев, не используя при этом C API оригинальных библиотек.Краткое руководство по сложным вычислительным задачам
5 мин
Перевод
Что компьютеру сделать легко, а что почти невозможно? Эти вопросы лежат в основе вопроса вычислительной сложности. Представляем вам карту этого ландшафта.

Различные классы сложности сортируют задачи в иерархическом виде. Один класс может содержать все задачи другого, плюс задачи, требующие дополнительных вычислительных ресурсов.
Какова фундаментальная сложность задачи? Такова постановка базовой задачи специалистов по информатике, пытающихся рассортировать задачи по т.н. классам сложности. Это группы, содержащие все вычислительные задачи, требующие не более фиксированного количества вычислительных ресурсов – таких, как время или память. Возьмём простой пример с большим числом типа 123 456 789 001. Можно задать вопрос: является ли оно простым числом – таким, которое делится только на 1 и себя? Специалисты по информатике могут ответить на него при помощи быстрых алгоритмов – таких, что не начинают тормозить на произвольно больших числах. В нашем случае окажется, что это число не является простым. Затем мы можем задать вопрос: каковы его простые множители? А вот для ответа на него быстрого алгоритма не существует – только если использовать квантовый компьютер. Поэтому специалисты по информатике считают, что две этих задачи относятся к разным классам сложности.
Выделение подпроекта в отдельный репозиторий на github
3 мин
Недавно я столкнулся с задачей переноса папки с проектом из одного репозитория в другой на github. Звучит примитивно, но если рассмотреть то, что дано и то, что необходимо получить, могут возникнуть некоторые нюансы.
Итак, что дано:
- Есть большой репозиторий, содержащий множество папок. Каждая папка – это отдельный проект.
Что необходимо сделать:
- Одну из папок перенести в отдельный репозиторий с сохранением ее истории коммитов.
В теории можно было бы просто скопировать весь репозиторий со всем содержимым в новое место, а потом просто удалить те папки, которые не нужны. Но такой способ довольно неоптимален и не особо мне понравился, так что я решил поступить иначе.
Я использовал стандартный гитовый filter-branch. За основу я взял следующие статьи:
- Moving Files from one Git Repository to Another, Preserving History
- Splitting a subfolder out into a new repository
В этом посте я хочу немного адаптировать процесс для лучшего восприятия.
Linux Tuning для Современного ноутбука с Пассивной Системой Охлаждения
31 мин
 В последнее время всё больше и больше стало появляться ноутбуков, которые каким-то непостижимым образом работают вобще без вентилятора. Прямо как телефоны, но только ноутбуки. Бесшумно себе НЕ шелестят, и всё такое, интересное прям, ультра. И вот, в порыве, так сказать, молодецкого задора, решил я сменить свой "ещё в прочем очень даже неплохой ноутбук" на нечто этакое. Тем более, что диагональ в 14" мне была великовата, и уже очень давно хотелось вернуться на 11.6, но с сохранением Full HD.
В последнее время всё больше и больше стало появляться ноутбуков, которые каким-то непостижимым образом работают вобще без вентилятора. Прямо как телефоны, но только ноутбуки. Бесшумно себе НЕ шелестят, и всё такое, интересное прям, ультра. И вот, в порыве, так сказать, молодецкого задора, решил я сменить свой "ещё в прочем очень даже неплохой ноутбук" на нечто этакое. Тем более, что диагональ в 14" мне была великовата, и уже очень давно хотелось вернуться на 11.6, но с сохранением Full HD.Выбор пал на среднюю модель в 700-11 линейке Lenovo Yoga. Отличная, по ноутбучным меркам ANSI клавиатура с отдельными Home (+PgUp) и End (+PgDn). Правда, без подсветки, но она мне не нужна. 3 USB разъёма: один из них совмещён с питанием. Заявленых и в итоге достигнутых 4 часа от батарейки. Вес чуть больше килограмма. В общем — красота. Да и рыжий цвет меня устраивает вполне, всё равно наклейками обычно всё заклеено.
Единственный нюанс: работает «без нареканий» под штатным Windows 10 Home. Ну, то есть, как — «без нареканий» — это если не учитывать тот факт, что именно Работать Невозможно Же. Нет, я могу, конечно, но — это если очень много заплатят. А для обычной работы у меня Ubuntu, точней Linux Mint Mate Desktop. И, всё бы ничего, но после переезда — переноса разделов со старого на новый — Sarah отказалась дружить с моим новым ноутбуком:
- Жутко грелся, сразу и всё время градусов до 70 ℃ в Idle режиме
- Очень часто не загружался вообще
- Часто терял WiFi при температурах выше 75 ℃
Безусловно, всё под катом — это субъективное мнение, но, думаю, оно подойдёт для всех свежих Ubuntu Based дистрибутивов, а так же и для других Linux, т.к. большая часть информации совершенно не касается конкретного дистрибутива.
Решение, а так же фотки ноута и ещё немного всякой чепухи, включая Geek Porn с моддингом, под катом (Warning Трафик):
Прокси-сервер с помощью Tor. Основа для многопоточного парсинга
5 мин
Туториал
Всем привет! На днях прилетела интересная задача: «Найти бесплатные прокси-сервера». Взявшись за нее, решил обойти все сайты свободных проксей и понял — дохлые… ну или с высоким пингом.
После нескольких часов безуспешных поисков, было принято решение использовать свои ресурсы!
Итак, что в итоге должно получиться:
1. VM Ubuntu/Debian 2 CPU, 2GB RAM, 8GB HDD (ну тоесть совсем не требовательная)
2. PRIVOXY для проксирования запросов (Можно взять nginx, varnish — я взял Privoxy)
3. TOR сервер
После нескольких часов безуспешных поисков, было принято решение использовать свои ресурсы!
Итак, что в итоге должно получиться:
1. VM Ubuntu/Debian 2 CPU, 2GB RAM, 8GB HDD (ну тоесть совсем не требовательная)
2. PRIVOXY для проксирования запросов (Можно взять nginx, varnish — я взял Privoxy)
3. TOR сервер
Используем Secure Boot в Linux на всю катушку
17 мин
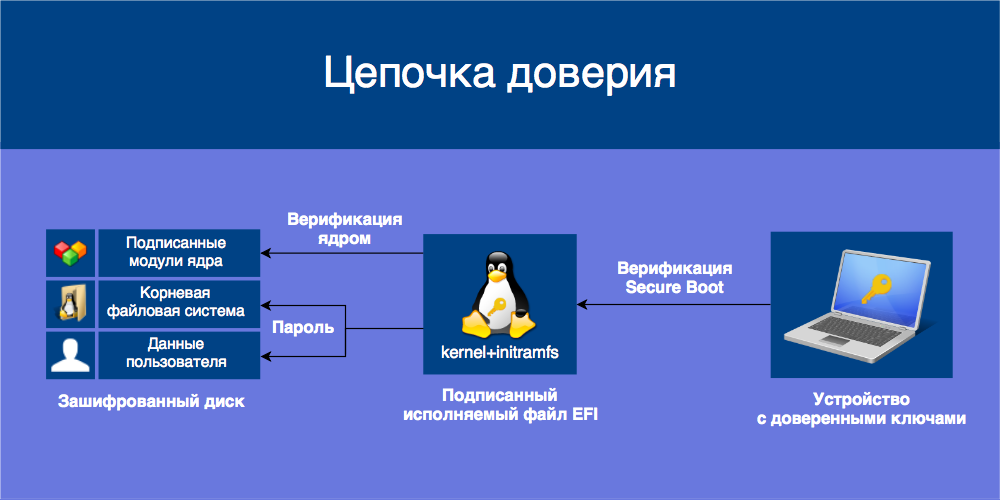
Технология Secure Boot нацелена на предотвращение исполнения недоверенного кода при загрузке операционной системы, то есть защиту от буткитов и атак типа Evil Maid. Устройства с Secure Boot содержат в энергонезависимой памяти базу данных открытых ключей, которыми проверяются подписи загружаемых UEFI-приложений вроде загрузчиков ОС и драйверов. Приложения, подписанные доверенным ключом и с правильной контрольной суммой, допускаются к загрузке, остальные блокируются.
Более подробно о Secure Boot можно узнать из цикла статей от CodeRush.
Чтобы Secure Boot обеспечивал безопасность, подписываемые приложения должны соблюдать некоторый «кодекс чести»: не иметь в себе лазеек для неограниченного доступа к системе и параметрам Secure Boot, а также требовать того же от загружаемых ими приложений. Если подписанное приложение предоставляет возможность недобросовестного использования напрямую или путём загрузки других приложений, оно становится угрозой безопасности всех пользователей, доверяющих этому приложению. Такую угрозу представляют загрузчик shim, подписываемый Microsoft, и загружаемый им GRUB.
Чтобы от этого защититься, мы установим Ubuntu с шифрованием всего диска на базе LUKS и LVM, защитим initramfs от изменений, объединив его с ядром в одно UEFI-приложение, и подпишем его собственными ключами.
Взломать Wi-Fi за 10 часов
12 мин
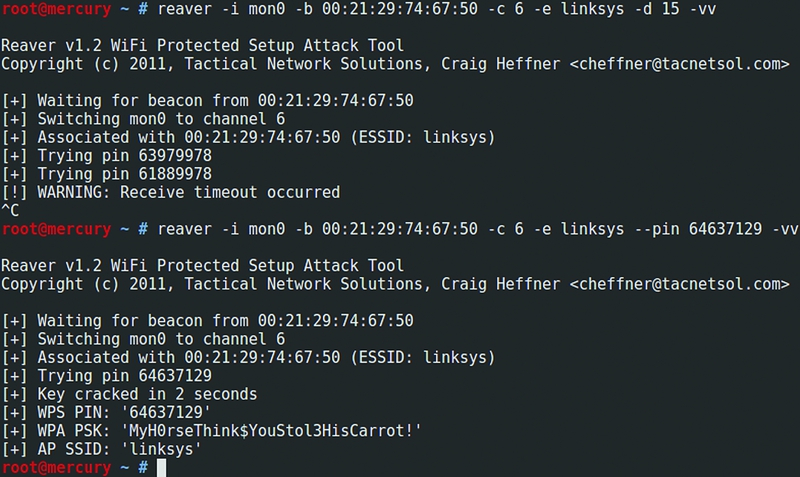
Еще не так давно казалось, что беспроводная сеть, защищенная с помощью технологии WPA2, вполне безопасна. Подобрать простой ключ для подключения действительно возможно. Но если установить по-настоящему длинный ключ, то сбрутить его не помогут ни радужные таблицы, ни даже ускорения за счет GPU. Но, как оказалось, подключиться к беспроводной сети можно и без этого — воспользовавшись недавно найденной уязвимостью в протоколе WPS.
Kill switch для OpenVPN на основе iptables
5 мин
Туториал
Известно, что при подключении к открытым Wi-Fi сетям ваш трафик может быть легко прослушан. Конечно, сейчас всё больше и больше сайтов используют HTTPS. Тем не менее, это ещё далеко не 100%. Возникает естественное желание обезопасить свой трафик при подключении к таким открытым Wi-Fi сетям.
Популярное решение этой проблемы — подключение через VPN. В таком случае ваш трафик передается в зашифрованном виде до VPN-сервера, и уже оттуда идет в интернет.
У такого решения есть небольшой недостаток: пока VPN-подключение ещё не установлено, все приложения на вашем компьютере (включая открытые вкладки браузера) получают доступ в интернет в обход VPN-подключения.
В этой статье я расскажу, как можно этого избежать.
Популярное решение этой проблемы — подключение через VPN. В таком случае ваш трафик передается в зашифрованном виде до VPN-сервера, и уже оттуда идет в интернет.
У такого решения есть небольшой недостаток: пока VPN-подключение ещё не установлено, все приложения на вашем компьютере (включая открытые вкладки браузера) получают доступ в интернет в обход VPN-подключения.
В этой статье я расскажу, как можно этого избежать.
Docker: запуск графических приложений в контейнерах
15 мин
 Строго говоря, Docker не был создан для подобного рода вещей, а именно запуска графических приложений. Однако, время от времени в темах про Docker звучат вопросы о том, нельзя ли запустить GUI-приложение в контейнере. Причины могут быть разные, но чаще всего, это желание сменить излишне громоздкую виртуальную машину на что-то полегче, не потеряв в удобстве и сохранив при этом достаточный уровень изоляции.
Строго говоря, Docker не был создан для подобного рода вещей, а именно запуска графических приложений. Однако, время от времени в темах про Docker звучат вопросы о том, нельзя ли запустить GUI-приложение в контейнере. Причины могут быть разные, но чаще всего, это желание сменить излишне громоздкую виртуальную машину на что-то полегче, не потеряв в удобстве и сохранив при этом достаточный уровень изоляции. Это небольшой обзор способов запуска графических приложений в контейнерах Docker.
Tagsistant: семантическая файловая система
11 мин
Привет. На хабре уже был материал, посвященный Tagsistant, но мне он показался сбивчивым и неполным. Эта попытка подать его по-другому является краткой выжимкой из англоязычного мануала и собственных наблюдений.
Проект Tagsistant позиционирует свое творение, tagfs, как следование за общей тенденцией. Интернет шаг за шагом пытаются переводить на семантические рельсы, а файловые системы, считают авторы проекта, закоснели в устарелых принципах — иерархия, директории,вот это всё.
И в принципе, я с ними в чем-то согласен. Представьте, что у вас есть несколько сотен фотографий, одни из которых сделаны в Кёльне, другие сделаны на закате, на третьих изображены девушки, а четвертые сделаны в 2010 году. Теперь вообразите, что вы хотите выполнить следующую операцию: получить список фотографий, которые сделаны на закате в Кёльне с вашей подругой, исключая те, которые были сделаны в 2010 году.
Да, возможно, скажет кто-то, можно ведь создать директории, например, Koeln, sunset, girls, 2010, потом рассовать в них софтлинки на файлы… Как-то так, но разве это предоставит необходимую гибкость и удобство в составлении запросов (хотя бы в решении приведенного выше примера)?
Да, можно попытаться воспользоваться EXIF-тегами. Но камера не указывает в них присутствия девушек на фото и других критериев, ограниченных вашей фантазией. А если речь вообще не о фотографиях, а об отчетах?
Можно попытаться писать своеобразные теги в атрибуты файлов, используя ext4, при помощи setattr\getattr — по крайней мере, я видел такое предложение в вопросе тегирования файлов, не пробовал. Но это тоже половинчатое решение, даже если будет работать.
Реальный пример для затравки, который я могу придумать, исходя из моих потребностей. У меня есть папка с огромным количеством разного картиночного хлама, когда-либо сохраненного в Downloads и позже протегированного (на самом деле, не одна). Я хочу получить из всего этого мусорного полигона список фотографий форумчан-девушек, которые сделаны в Киеве, содержат изображения пива и сделаны раньше 2012 года. Вместе с ними я хочу получить изображения всех админов форума, которые у меня есть:
Проект Tagsistant позиционирует свое творение, tagfs, как следование за общей тенденцией. Интернет шаг за шагом пытаются переводить на семантические рельсы, а файловые системы, считают авторы проекта, закоснели в устарелых принципах — иерархия, директории,
И в принципе, я с ними в чем-то согласен. Представьте, что у вас есть несколько сотен фотографий, одни из которых сделаны в Кёльне, другие сделаны на закате, на третьих изображены девушки, а четвертые сделаны в 2010 году. Теперь вообразите, что вы хотите выполнить следующую операцию: получить список фотографий, которые сделаны на закате в Кёльне с вашей подругой, исключая те, которые были сделаны в 2010 году.
Да, возможно, скажет кто-то, можно ведь создать директории, например, Koeln, sunset, girls, 2010, потом рассовать в них софтлинки на файлы… Как-то так, но разве это предоставит необходимую гибкость и удобство в составлении запросов (хотя бы в решении приведенного выше примера)?
Да, можно попытаться воспользоваться EXIF-тегами. Но камера не указывает в них присутствия девушек на фото и других критериев, ограниченных вашей фантазией. А если речь вообще не о фотографиях, а об отчетах?
Можно попытаться писать своеобразные теги в атрибуты файлов, используя ext4, при помощи setattr\getattr — по крайней мере, я видел такое предложение в вопросе тегирования файлов, не пробовал. Но это тоже половинчатое решение, даже если будет работать.
Реальный пример для затравки, который я могу придумать, исходя из моих потребностей. У меня есть папка с огромным количеством разного картиночного хлама, когда-либо сохраненного в Downloads и позже протегированного (на самом деле, не одна). Я хочу получить из всего этого мусорного полигона список фотографий форумчан-девушек, которые сделаны в Киеве, содержат изображения пива и сделаны раньше 2012 года. Вместе с ними я хочу получить изображения всех админов форума, которые у меня есть:
$ ls ~/tagsistant/store/forum/girls/beer/=Kyiv/time:/year/lt/2012/+/admin/@/
Еще раз про приведение типов в языке С++ или расстановка всех точек над cast
8 мин

Этот пост попытка кратко оформить все, что я читал или слышал из разных источников про операторы приведения типов в языке C++. Информация ориентирована в основном на тех, кто изучает C++ относительно недолго и, как мне кажется, должна помочь понять cпецифику применения данных операторов. Старожилы и гуру С++ возможно помогут дополнить или скорректировать описанную мной картину. Всех интересующихся приглашаю под кат.
Анализ SSL/TLS трафика в Wireshark
7 мин
Туториал

Как скрыть от посторонних конфиденциальную информацию?
Самое простое – зашифровать.
В Интернет и Интранет-сетях шифрацией данных управляет протокол SSL/TLS.
Солдат спит, служба идет.
Однако иногда возникает необходимость выполнить обратное – расшифровать перехваченный трафик.
Это может потребоваться как для отладки работы приложений, так и для проверки подозрительной сетевой активности.
Или в целях изучения работы SSL/TLS (очевидные, вредоносные цели не обсуждаются).
Как и при каких условиях можно расшифровать дамп SSL/TLS трафика в Wireshark?
Попробуем разобраться.
Откровения метапрограммиста. Программируем программный код на этапе компиляции, используем шаблоны C++ для нешаблонных решений
11 мин
Туториал

Шаблоны можно назвать самым главным отличием и основным преимуществом языка C++. Возможность создать шаблон алгоритма для различных типов без копирования кода и со строгой проверкой типов — это лишь один из аспектов использования шаблонов. Код специализаций шаблона строится на этапе компиляции, а это значит, что поведением создаваемых типов и функций можно управлять. Как тут удержаться от возможности попрограммировать компилируемые классы?
Метапрограммирование становится столь же неотъемлемой частью написания кода на C++, как и использование стандартной библиотеки, часть которой создана именно для использования на этапе компиляции. Сегодня мы произведем на свет библиотеку безопасного приведения скалярных типов C++, метапрограммируя шаблонами!
Размещай и властвуй! Используем размещающий new для оптимизации кода на C++
14 мин
Туториал

Создавая объект за объектом, мы часто не обращаем внимания на такую «мелочь», как динамическое выделение памяти. Наравне с копированием и сериализацией, выделение памяти из кучи через new постепенно сводит на нет преимущества C++ в скорости. Чем интенсивнее мы пользуемся заветным new, тем сложнее становится приложению, поскольку память кончается, фрагментируется и всячески стремится утекать. Эта участь уже постигла удобные, но неявно опасные для производительности контейнеры STL: vector, string, deque, map. Особенно обидно терять скорость на выделении небольших объектов в больших количествах. Но есть способ обработать размещение памяти таких объектов на стеке, при этом скрывая детали реализации в специальный класс данных. В этом нам поможет механизм размещающего new — непревзойденный способ оптимизации приложения, полного частых и мелких выделений памяти из кучи.
Systemd за пять минут
4 мин
Наша компания занимается администрированием веб-серверов на базе CentOS. Довольно часто наши клиенты используют веб-приложения на базе python, ruby или java. Для автозапуска подобных приложений есть готовые шаблоны для написания стартап-скриптов. Но прогресс не стоит на месте, вышел уже второй релиз CentOS 7 и, следуя старой традиции «не ставить dot-zero релизы на продакшен», мы начинаем предлагать клиентам сервера на базе CentOS 7.1 (1503).
В CentOS7, так же как и в его родителе RHEL7, используется systemd — менеджер системы и служб для Linux, совместимый со скриптами инициализации SysV и LSB. systemd обеспечивает возможности агрессивной параллелизации и много всего прочего.

Огромный монстр с множеством возможностей, гибкими настройками и мегабайтами документации…
Но что делать, если стоит задача быстро-быстро, вот прямо вчера, сделать автозапуск некоего сервиса?
Давайте выжмем из документации минимально необходимый набор информации для создания простых старт-стоп скриптов.
В CentOS7, так же как и в его родителе RHEL7, используется systemd — менеджер системы и служб для Linux, совместимый со скриптами инициализации SysV и LSB. systemd обеспечивает возможности агрессивной параллелизации и много всего прочего.
Огромный монстр с множеством возможностей, гибкими настройками и мегабайтами документации…
Но что делать, если стоит задача быстро-быстро, вот прямо вчера, сделать автозапуск некоего сервиса?
Давайте выжмем из документации минимально необходимый набор информации для создания простых старт-стоп скриптов.
Как легко расшифровать TLS-трафик от браузера в Wireshark
2 мин
Перевод
Многим из вас знаком Wireshark — анализатор трафика, который помогает понять работу сети, диагностировать проблемы, и вообще умеет кучу вещей.
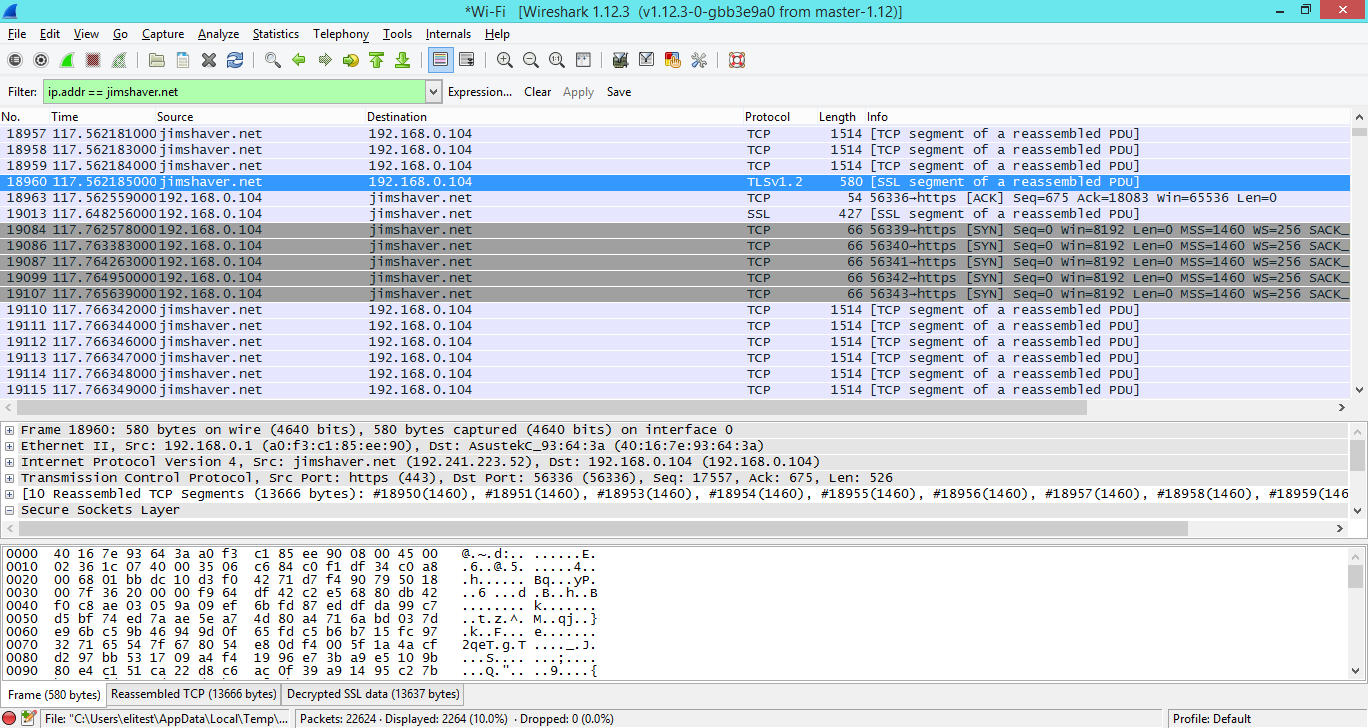
Одна из проблем с тем, как работает Wireshark, заключается в невозможности легко проанализировать зашифрованный трафик, вроде TLS. Раньше вы могли указать Wireshark приватные ключи, если они у вас были, и расшифровывать трафик на лету, но это работало только в том случае, если использовался исключительно RSA. Эта функциональность сломалась из-за того, что люди начали продвигать совершенную прямую секретность (Perfect Forward Secrecy), и приватного ключа стало недостаточно, чтобы получить сессионный ключ, который используется для расшифровки данных. Вторая проблема заключается в том, что приватный ключ не должен или не может быть выгружен с клиента, сервера или HSM (Hardware Security Module), в котором находится. Из-за этого, мне приходилось прибегать к сомнительным ухищрениям с расшифровкой трафика через man-in-the-middle (например, через sslstrip).
Что ж, друзья, сегодня я вам расскажу о способе проще! Оказалось, что Firefox и Development-версия Chrome поддерживают логгирование симметричных сессионных ключей, которые используются для зашифровки трафика, в файл. Вы можете указать этот файл в Wireshark, и (вуаля!) трафик расшифровался. Давайте-ка настроим это дело.
Одна из проблем с тем, как работает Wireshark, заключается в невозможности легко проанализировать зашифрованный трафик, вроде TLS. Раньше вы могли указать Wireshark приватные ключи, если они у вас были, и расшифровывать трафик на лету, но это работало только в том случае, если использовался исключительно RSA. Эта функциональность сломалась из-за того, что люди начали продвигать совершенную прямую секретность (Perfect Forward Secrecy), и приватного ключа стало недостаточно, чтобы получить сессионный ключ, который используется для расшифровки данных. Вторая проблема заключается в том, что приватный ключ не должен или не может быть выгружен с клиента, сервера или HSM (Hardware Security Module), в котором находится. Из-за этого, мне приходилось прибегать к сомнительным ухищрениям с расшифровкой трафика через man-in-the-middle (например, через sslstrip).
Логгирование сессионных ключей спешит на помощь!
Что ж, друзья, сегодня я вам расскажу о способе проще! Оказалось, что Firefox и Development-версия Chrome поддерживают логгирование симметричных сессионных ключей, которые используются для зашифровки трафика, в файл. Вы можете указать этот файл в Wireshark, и (вуаля!) трафик расшифровался. Давайте-ка настроим это дело.