Прим. перев.: service mesh — явление, которое ещё не имеет устойчивого перевода на русский язык (более 2 лет назад мы предлагали вариант «сетка для сервисов» или «сервисная сетка», а чуть позже некоторые коллеги стали продвигать сочетание «сервисное сито»). Постоянные разговоры об этой технологии привели к ситуации, в которой слишком тесно переплелись маркетинговая и техническая составляющие. Этот замечательный материал от одного из авторов оригинального термина призван внести ясность для инженеров и не только.
 Комикс от Sebastian Caceres
Комикс от Sebastian Caceres
Введение
Если вы инженер-программист, работающий где-то в районе бэкенд-систем, термин «service mesh», вероятно, уже прочно закрепился в вашем сознании за последние пару лет. Благодаря странному стечению обстоятельств, это словосочетание захватывает отрасль все сильнее, а хайп и связанные с ним рекламные предложения нарастают словно снежный ком, летящий вниз по склону и не подающий никаких признаков замедления.
Service mesh зародилась в мутных, тенденциозных водах экосистемы cloud native. К сожалению, это означает, что значительная часть связанной с ней полемики варьируется от «низкокалорийной болтовни» до — если воспользоваться техническим термином — откровенной чуши. Но если отсеять весь шум, можно обнаружить, что у service mesh есть вполне реальная, определенная и важная функция.
В этой публикации я попытаюсь проделать именно это: представить честное, глубокое, ориентированное на инженеров руководство по сервисным сеткам. Я собираюсь ответить не только на вопрос:
«Что это такое?», — но и
«Зачем?», а также
«Почему именно сейчас?». Наконец, попытаюсь обрисовать, почему (по моему мнению) конкретно эта технология вызвала такой сумасшедший ажиотаж, что само по себе интересная история.




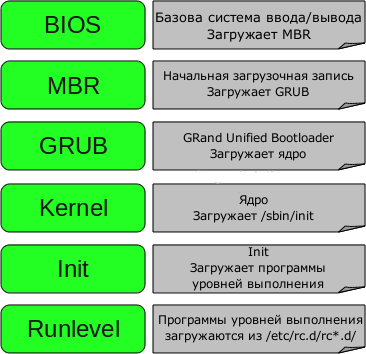 Нажмите кнопку включения питания на вашем системнике, и спустя несколько секунд вы увидите окно входа в систему.
Нажмите кнопку включения питания на вашем системнике, и спустя несколько секунд вы увидите окно входа в систему.