
Добро пожаловать во вторую часть статьи о фреймворке LangChain.
В этой части мы перейдем к более продвинутым возможностям агентов и узнаем, как использовать их для работы с собственной базой данных и моделирования.

аналитик данных
Добро пожаловать во вторую часть статьи о фреймворке LangChain.
В этой части мы перейдем к более продвинутым возможностям агентов и узнаем, как использовать их для работы с собственной базой данных и моделирования.

Сегодня it-сообщество предлагает большое количество любопытных инструментов для создания RAG-систем. Среди них особенно выделяются два фреймворка — LangChain и LlamaIndex. Как понять, какой из них подходит лучше для вашего проекта? Давайте разбираться вместе!

GenAI стремительно ворвался в нашу жизнь. Ещё вчера мы с опаской смотрели на него, а сегодня уже вовсю используем в работе. Многие эксперты пророчат GenAI большое будущее, считая его предвестником новой промышленной революции.
И ведь действительно, LLM и мультимодальные модели уже сейчас демонстрируют впечатляющие возможности и при этом относительно просты во внедрении. Создать простое приложение на их основе - дело нескольких строк кода. Однако переход от эксперимента к стабильному и надежному решению — задача посложнее.
Как метко подметил Мэтт Тёрк: если в 2023 году мы боялись, что GenAI нас погубит, то в 2024-м мечтаем хоть как-то приручить его и запустить в "мелкосерийное производство".
Если вы уже успели создать свои первые LLM-приложения и готовы вывести их на новый уровень, эта статья для вас. Мы рассмотрим 17 продвинутых RAG-техник, которые помогут избежать типичных ошибок и превратить ваш прототип в мощное и стабильное решение.
Пристегните ремни, мы отправляемся в увлекательное путешествие по миру AGI! Вместе мы:
Поймем, как система отличает ценную информацию от информационного шума;
Разберемся, как правильно подготовить данные для LLM;
Выясним, можно ли строить цепочки из нескольких LLM;
Поймем, как направлять запросы через разные компоненты системы.
Приятного прочтения(:

Всем привет! Я Толя Потапов, MLE в Т-Банке. Руковожу командой разработки фундаментальных моделей.
Почти два года мы плотно работаем с LLM, развиваем продукты на базе больших языковых моделей. Например, Вселенную ассистентов, которая входит Gen-T — семейство собственных специализированных языковых моделей.
Сегодня мы открываем две большие языковые модели — T-Lite и T-Pro, над которыми работали последние полгода, их можно скачать с huggingface. Они распространяются под лицензией Apache 2.0. Для адаптации моделей под бизнес-кейсы рекомендуем воспользоваться нашей библиотекой turbo-alignment с инструментами для полного цикла работы над LLM.

Энкодер предложений (sentence encoder) – это модель, которая сопоставляет коротким текстам векторы в многомерном пространстве, причём так, что у текстов, похожих по смыслу, и векторы тоже похожи. Обычно для этой цели используются нейросети, а полученные векторы называются эмбеддингами. Они полезны для кучи задач, например, few-shot классификации текстов, семантического поиска, или оценки качества перефразирования.
Но некоторые из таких полезных моделей занимают очень много памяти или работают медленно, особенно на обычных CPU. Можно ли выбрать наилучший энкодер предложений с учётом качества, быстродействия, и памяти? Я сравнил 25 энкодеров на 10 задачах и составил их рейтинг. Самой качественной моделью оказался mUSE, самой быстрой из предобученных – FastText, а по балансу скорости и качества победил rubert-tiny2. Код бенчмарка выложен в репозитории encodechka, а подробности – под катом.

Одно из самых прикладных применений языковых моделей (LLM) - это ответы на вопросы по документу/тексту/договорам. Языковая модель имеет сильную общую логику, а релевантные знания получаются из word, pdf, txt и других источников.
Обычно релевантные тексты раскиданы в разных местах, их много и они плохо структурированы. Одна из проблем на пути построения хорошего RAG - нахождение релевантных частей текста под заданный пользователем вопрос.
Еще В. Маяковский писал: "Изводишь единого слова ради, тысячи тонн словесной руды." Примерно это же самое делают би-энкодеры и кросс-энкодеры в рамках RAG, ищут самые важные и полезные слова в бесконечных тоннах текста.
В статье мы посмотрим на способы нахождения релевантных текстов, увидим проблемы, которые в связи с этим возникают. Попытаемся их решить.
Главное - мы натренируем свой кросс-энкодер на русском языке, что служит важным шагом на пути улучшения качества Retrieval Augmented Generation (RAG). Тренировка будет проходит новейшим передовым способом. Схематично он изображен на меме справа)

Салют, Хабр! В начале ноября мы делились с вами новостями о нашем флагмане GigaChat MAX и пообещали рассказать подробнее о процессе создания наших Pretrain-моделей. Пришло время сдержать слово и даже пойти дальше!
Предобучение больших языковых моделей — это одна из наиболее ресурсозатратных стадий, которая непосредственно влияет на весь дальнейший процесс обучения GigaChat. От успешности обучения Pretrain-модели напрямую зависит качество всех следующих этапов обучения, например, Alignment и Vision. Поэтому сегодня мы хотим поделиться весами младшей модели линейки GigaChat версий base и instruct. Модель называется GigaChat-20B-A3B, так как построена на перспективной МоЕ-архитектуре!
Но и это ещё не всё. Вместе с весами мы делимся с сообществом улучшенной реализацией DeepSeek МоЕ, а также кодом для механизма концентрации (а что это такое — читайте дальше ;)). Важно отметить, что хотя GigaChat-20B-A3B обучался на триллионах токенов преимущественно русского текста, он ещё способен на хорошем уровне понимать другие языки. Так что мы делимся мультиязычной моделью. О том, как запускать модель, какие версии доступны и как пользоваться контролируемой генерацией с помощью механизма концентрации, расскажем прямо сейчас!

Наиболее распространенный случай использования ИИ в бизнесе в данный момент— это поиск ответов в имеющихся у компании данных для принятия решений или создание красиво оформленных, но совершенно бесполезных отчетов, чтобы топ-менеджмент мог оправдать свои огромные бонусы. Все это, конечно, очень важные и легитимные кейсы.
Проблема тут если вы один из этих топ-менеджеров или просто не являетесь экспертом в области. Ваш отдел аналитики данных и ИИ, если он у вас есть, вероятно, говорит на своем инопланетном наречии и не может дать связного ответа, почему у нас столько данных, но мы все еще не можем ответить на довольно тривиальные вопросы (что, конечно, задерживает получение бонусов, а новый БМВ сам себя не купит).
Я разделяю вашу боль, давайте разберемся, о чем они говорят.

Если, открывая холодильник вы еще не слышали из него про RAG, то наверняка скоро услышите. Однако, в сети на удивление мало полных гайдов, учитывающих все тонкости (оценка релевантности, борьба с галлюцинациями и т.д.) а не обрывочных кусков. Базируясь на опыте нашей работы, я составил гайд который покрывает эту тему наиболее полно.
Итак зачем нужен RAG?

Перевод статьи "Как освоить Streamlit для Data Science",
Автор: Chanin Nantasenamat
Примечание переводчика: я нашла эту статью достаточно полезной при своем погружении в науку о данных, и по гайдам автора смогла решить многие свои научные задачи. Всем кто только становится на этот путь, приятного чтения :)


Добрый день, уважаемые читатели и авторы Хабра!
Сегодня я рад представить вам подробное руководство по обучению модели ruGPT-3.5 13B с использованием датасетов модели Saiga-2/GigaSaiga, технологии Peft/LoRA и технологии GGML. Эта статья призвана стать полезным и практичным ресурсом для всех, кто интересуется машинным обучением, искусственным интеллектом и глубоким обучением, а также для тех, кто стремится глубже понять и освоить процесс обучения одной из самых мощных и перспективных русскоязычных моделей.
В данной публикации мы разберем каждый этап обучения модели, начиная от подготовки данных и заканчивая конвертацией в формат GGML. Буду рад, если мой опыт и знания помогут вам в вашем исследовании и экспериментах в этой захватывающей области!

? Upd. Добавили пример запуска в Colab'е.
Друзья, свершилось. Сегодня мы рады сообщить вам о релизе в открытый доступ нейросетевой модели, которая лежит в основе сервиса GigaChat.
Про то, что такое GigaChat и как мы его обучаем, вы можете прочитать в нашей предыдущей статье. Скажу лишь, что главной его частью, ядром, порождающим креативный ответ на ваш запрос, является языковая модель обученная на огромном количестве разнообразных текстов — сотен тысяч книг, статей, программного кода и т.д. Эта часть (pretrain) затем дообучается на инструкциях, чтобы лучше соответствовать заданной форме ответа. Обучение такого претрейна занимает около 99% от всего цикла обучения и требует значительного количества ресурсов, которыми обычно обладают только крупные компании.
Этот претрейн, названный ruGPT-3.5, мы выкладываем на Hugging Face под лицензией MIT, которая является открытой и позволяет использовать модель в коммерческих целях. Поговорим о модели подробнее.

На сегодняшний день созданы разные большие языковые модели (LLM), которые показывают превосходные результаты, но для раскрытия их полного потенциала необходимо дообучение для точного решения конкретных задач. Традиционный метод файнтюнинга, при котором настраиваются все параметры предварительно обученной модели, становится непрактичным и вычислительно дорогостоящим при работе с современными моделями LLM.
PEFT(Parameter-Efficient Fine-Tuning) представляет собой эффективный подход, позволяющий не терять производительность при тонкой настройке модели, снижая при этом требования к памяти и вычислительным мощностям.
В этой статье мы рассмотрим общую концепцию PEFT, его преимущества и основные методы.

К моему удивлению, в открытом доступе оказалось не так уж много подробных и понятных объяснений того как работает модель GPT от OpenAI. Поэтому я решил всё взять в свои руки и написать этот туториал.
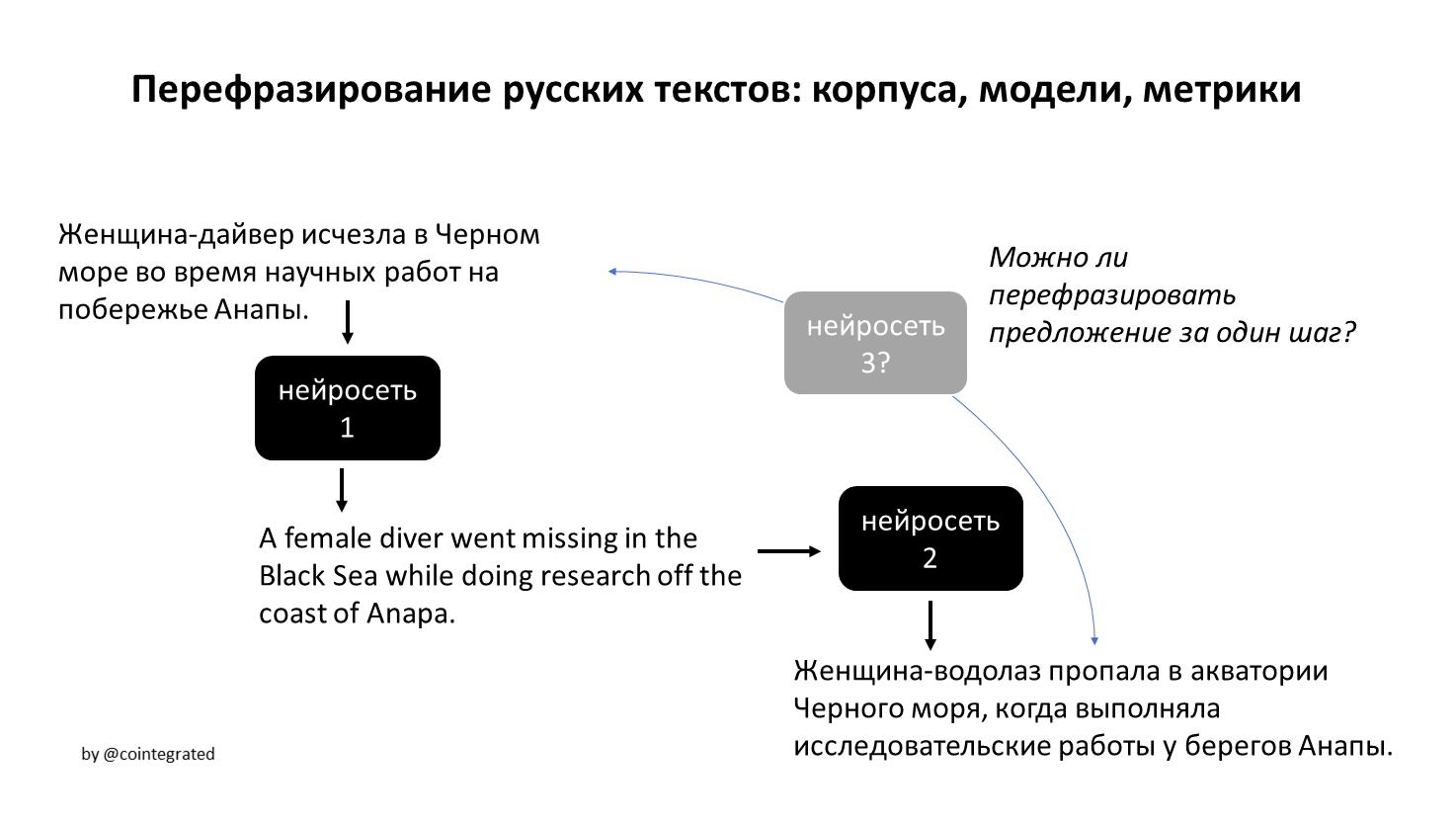
Автоматическое перефразирование текстов может быть полезно в куче задач, от рерайтинга текстов до аугментации данных. В этой статье я собрал русскоязычные корпуса и модели парафраз, а также попробовал создать собственный корпус, обучить свою модель для перефразирования, и собрать набор автоматических метрик для оценки их качества.
В итоге оказалось, что модель для перевода перефразирует лучше, чем специализированные модели. Но, по крайней мере, стало более понятно, чего вообще от автоматического перефразирования можно хотеть и ожидать.

Два года назад я создал свой канал, где делился всем, что меня увлекает — от личных заметок и искусства до новостей Data Science и ИИ. За это время мой канал стал обширным хранилищем текстов, и я решил проанализировать их. Я применил статистический анализ, тематическое моделирование, нейросети и кластерный анализ, чтобы вытащить из данных как можно больше информации. В своей статье я подробно описываю весь процесс и делюсь полученными результатами.
Приглашаю вас на препарацию моих мыслей, заметок и идей!

Существует большое разнообразие методов сегментарного анализа в маркетинге. Во-первых, сегментация — это стратегия, используемая для концентрации ресурсов на целевом рынке/объекте и оптимизации их использования. Во-вторых, сегментация — это алгоритм анализа рынка для лучшего учёта его особенностей.
Эффективно проведённая сегментация упрощает и удешевляет маркетинговую политику, позволяет отказаться от многих затратных методов продвижения. Объяснение очень простое - покупатель приходит к продавцу не за рекламой и скидками, а за удовлетворением своих потребностей. Поэтому продавцы, предлагающие товары или услуги, лучше удовлетворяющие потребности покупателей (по свойствам, качеству, цене и т. д.), могут добиться большего эффекта, а также свести к минимуму затраты на рекламу и скидки.
Рассмотрим частотно-монетарный метод сегментации применительно к e-commerce сфере. Частотно-монетарный анализ (RFM анализ) - анализ, в основе которого лежат поведенческие факторы групп или сегментов клиентов, позволяющий сегментировать клиентов по частоте и сумме покупок и выявлять тех, которые приносят больше денег. Данный метод позволяет получить ценные инсайты по построению маркетинговых стратегий в компании. Также RFM-сегментация помогает применять особый комуникативный подход к каждой группе клиентов.
RFM-анализ частично перекликается с принципом Парето, полагающим, что 80% результатов происходят благодаря 20% усилий. Если данный принцип рассматривать в общем ключе маркетинга - 80% всех ваших продаж исходят от 20% наиболее лояльных и постоянных клиентов. Постоянные клиенты всегда буду иметь высокое влияние на выручку, а значит – возвращаемость этих клиентов крайне важна для показателей дохода.

Продуктовая аналитика - это очень важный процесс, который помогает компаниям понимать, как пользователи взаимодействуют с их продуктом или услугой. Этот процесс включает в себя сбор и анализ большого количества данных, которые помогают понять, как пользователи используют продукт, какие функции наиболее популярны, какие маркетинговые кампании наиболее эффективны и многое другое. Благодаря продуктовой аналитике компании могут получить ценные знания, которые помогают улучшить продукт, увеличить количество пользователей и увеличить доходы.