Привет, Хабр. Сегодня мы, Юрий Темкин и Алексей Федоров, расскажем о том, как в нашем Кибер Бэкапе устроена поддержка PostgreSQL и СУБД на ее основе, а также обсудим новинки, появившиеся в версиях 16.5, 17.0 и 17.1.

Software Engineer, Development Manager
Привет, Хабр. Сегодня мы, Юрий Темкин и Алексей Федоров, расскажем о том, как в нашем Кибер Бэкапе устроена поддержка PostgreSQL и СУБД на ее основе, а также обсудим новинки, появившиеся в версиях 16.5, 17.0 и 17.1.

Привет, Хабр! Сегодня мне хотелось бы поговорить о такой интересной метрике, как Maintainability - возможность вести доработки и улучшения при создании сложных систем. Ведь при развитии любого программного продукта возникает вопрос, сколько будет стоить его поддержка и развитие. Мы в Киберпротекте разрабатываем линейку продуктов для защиты данных и сегодня это — миллионы строк кода, требующие ощутимых затрат как на поддержку, так и на расширение возможностей или исправление найденных ошибок. В этой статье я делюсь своими мыслями о том, как оценить Maintainability, из чего она состоит, можно ли ее измерить, и как принимать правильные решения при работе с кодом.

Привет Хабр! Сегодня мы рассмотрим кейс интеграции системы резервного копирования Кибер Бэкап с платформой виртуализации ECP VeiL от НИИ “Масштаб”. Скажу сразу, что это был непростой путь, и нам пришлось приложить немало усилий с обеих сторон, чтобы продукты действительно начали взаимодействовать друг с другом так, как надо. Но, как говорят психологи, “над отношениями надо работать”. Что же, мы работали и продолжаем работать. А под катом — небольшой рассказ том, как развивались взаимоотношения Кибер Бэкап и ECP VeiL.

В прошлых двух статьях мы рассказывали об IIoT — индустриальном интернете вещей — строили архитектуру, чтобы принимать данные от сенсоров, паяли сами сенсоры. Краеугольным камнем архитектур IIoT да и вообще любых архитектур работающих с BigData является потоковая обработка данных. В ее основе лежит концепция передачи сообщений и очередей. Стандартом работы с рассылкой сообщений сейчас стала Apache Kafka. Однако, для того, чтобы разобраться в ее преимуществах (и понять ее недостатки) было бы хорошо разобраться в основах работы систем очередей в целом, механизмах их работы, шаблонах использования и основной функциональности.

Мы нашли отличную серию статей, которая сравнивает функциональность Apache Kafka и другого (незаслуженно игнорируемого) гиганта среди систем очередей — RabbitMQ. Эту серию статей мы перевели, снабдили своими комментариями и дополнили. Хотя серия и написана в декабре 2017 года, мир систем обмена сообщениями (и особенно Apache Kafka) меняется так быстро, что уже к лету 2018-го года некоторые вещи изменились.

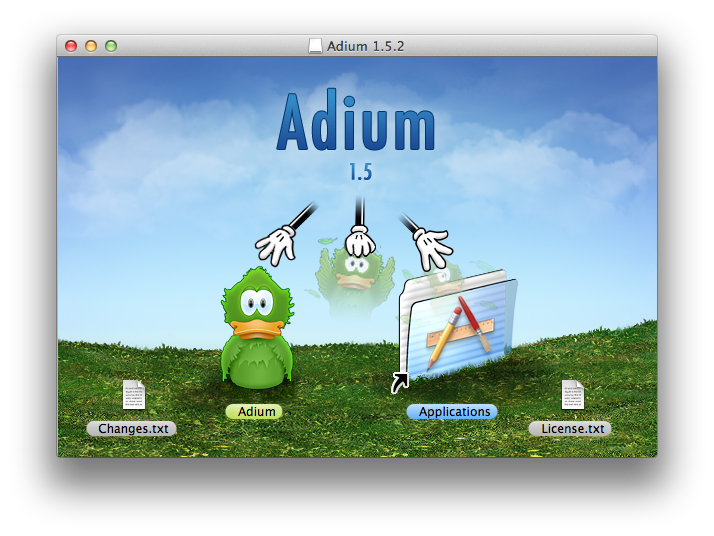 Сегодня я расскажу вам о том, как красиво преподнести пользователю инсталлятор своей программы. Наверняка каждый, кто пользуется не только программами из AppStore, сталкивался с красивыми образами диска .dmg, как вот у Адиума, к примеру. Такой образ представляет из себя, так сказать, интерактивный инсталлятор, в котором дана чёткая подсказка: перетащи значок вот сюда. Всё предельно понятно и просто.
Сегодня я расскажу вам о том, как красиво преподнести пользователю инсталлятор своей программы. Наверняка каждый, кто пользуется не только программами из AppStore, сталкивался с красивыми образами диска .dmg, как вот у Адиума, к примеру. Такой образ представляет из себя, так сказать, интерактивный инсталлятор, в котором дана чёткая подсказка: перетащи значок вот сюда. Всё предельно понятно и просто.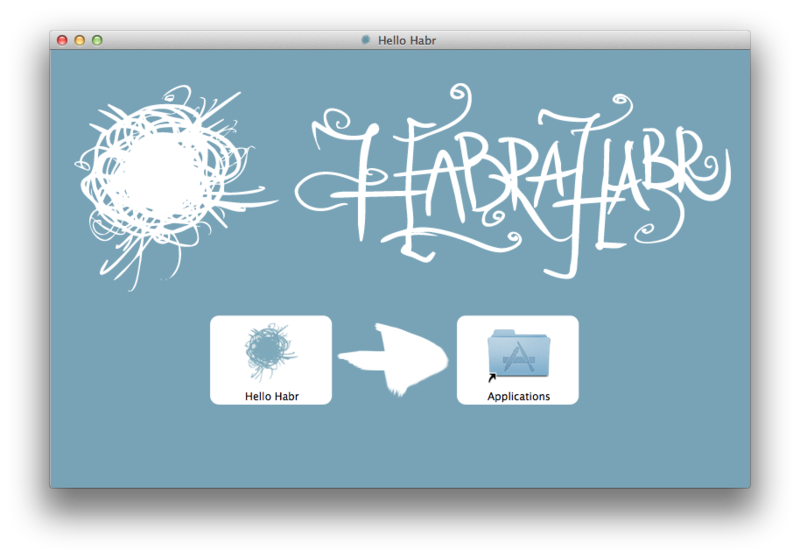
 Делиться с ближним своим для нас, божьих тварей, это очень характерно, считается добродетелью, и вообще, как утверждает первоисточник, положительно отражается на карме. Однако в мире, созданном архитекторами микропроцессоров, такое поведение не всегда приводит к хорошим результатам, особенно если это касается разделения памяти между потоками.
Делиться с ближним своим для нас, божьих тварей, это очень характерно, считается добродетелью, и вообще, как утверждает первоисточник, положительно отражается на карме. Однако в мире, созданном архитекторами микропроцессоров, такое поведение не всегда приводит к хорошим результатам, особенно если это касается разделения памяти между потоками. 
Определение Докера в Википедии звучит так:
программное обеспечение для автоматизации развёртывания и управления приложениями в среде виртуализации на уровне операционной системы; позволяет «упаковать» приложение со всем его окружением и зависимостями в контейнер, а также предоставляет среду по управлению контейнерами.
Ого! Как много информации.
autonullptroverride и finalenumbegin() и end()static_assert и классы свойств Перформансные задачи от Контура уже были, настала и наша очередь: представляем хардкорные задачи с Java-конференции JBreak 2018, aka «ад от Excelsior».
Перформансные задачи от Контура уже были, настала и наша очередь: представляем хардкорные задачи с Java-конференции JBreak 2018, aka «ад от Excelsior».
Задачи даны в оригинальных формулировках, в каждой задаче может быть несколько правильных ответов, и к каждой задаче дано решение под спойлером.
Ваш коллега начитался Java Language Specification и написал следующее:
void playWithRef() {
Object obj = new Object();
WeakReference<Object> ref = new WeakReference<>(obj);
System.out.println(ref.get() != null);
System.gc();
System.out.println(ref.get() != null);
}А разгребать вам: какие результаты исполнения возможны?
 Сейчас уже никто не создает программы в консоли. Используя любимую IDE, разработчик чувствует себя неуютно за чужим компьютером, где её нет.
Сейчас уже никто не создает программы в консоли. Используя любимую IDE, разработчик чувствует себя неуютно за чужим компьютером, где её нет. У Вас когда-либо случались такие ситуации, когда Ваше Java приложение трещит по швам? В моём случае это случилось из-за нехватки доступной оперативной памяти. И, естественно, обнаружилась нехватка в самый неподходящий момент: на носу очередной долгожданный релиз, один из серверов остановлен для обновления кода и данных и реинкарнация старого кода уже невозможна, в ближайшие дни запланировано несколько совещаний и собеседований, что сильно отвлекает от процесса оптимизации — в общем, ЧП не прошло незамеченным.
У Вас когда-либо случались такие ситуации, когда Ваше Java приложение трещит по швам? В моём случае это случилось из-за нехватки доступной оперативной памяти. И, естественно, обнаружилась нехватка в самый неподходящий момент: на носу очередной долгожданный релиз, один из серверов остановлен для обновления кода и данных и реинкарнация старого кода уже невозможна, в ближайшие дни запланировано несколько совещаний и собеседований, что сильно отвлекает от процесса оптимизации — в общем, ЧП не прошло незамеченным.
Как известно, на любом языке можно писать, как на Java, а первая любовь джависта — это написание Garbage Collectors и JIT Compilers. С этим связано множество восхитительных вопросов, например: каким образом можно из управляемого кода напрямую работать с машинным кодом и ассемблером?
Кроме того, в этой статье будет небольшой пример на C#. В какой-то момент стало понятно, что нельзя всегда изучать одну Java. Рантаймы динамических языков используют общую теорию и на практике работают в рамках похожих проблем. Самый простой способ продвинуть свою работу — посмотреть, как там у соседей, и скопировать себе что-нибудь хорошее.
Теперь про ассемблер и машинный код. Зачем это нужно — вопрос открытый. Например, вы наслушались о Meltdown и хотите написать для него красивое API :-) Ну, и не надо забывать, что Oracle — не боги, поддержку того же AVX-512 добавили только в Девятке, прямое управление аппаратной транзакционной памятью не ложится на язык, часть стандартных методов можно реализовать лучше, чем это сделали в SDK и т.п. — у нас всегда есть с чем покопаться!