

Недавно мы писали о забавных, хитрых и странных примерах на JavaScript. Теперь пришла очередь Python. У Python, высокоуровневого и интерпретируемого языка, много удобных свойств. Но иногда результат работы некоторых кусков кода на первый взгляд выглядит неочевидным.
Ниже — забавный проект, в котором собраны примеры неожиданного поведения в Python с обсуждением того, что происходит под капотом. Часть примеров не относятся к категории настоящих WTF?!, но зато они демонстрируют интересные особенности языка, которых вы можете захотеть избегать. Я думаю, это хороший способ изучить внутреннюю работу Python, и надеюсь, вам будет интересно.
Если вы уже опытный программист на Python, то многие примеры могут быть вам знакомы и даже вызовут ностальгию по тем случаям, когда вы ломали над ними голову :)




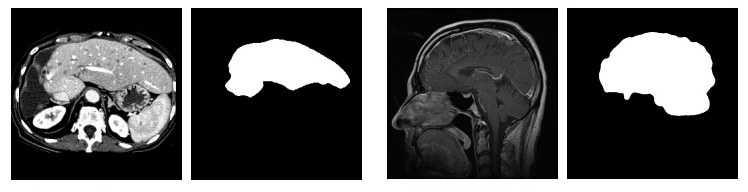 Слева — исходное изображение, справа — сегментированное
Слева — исходное изображение, справа — сегментированное



 Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.