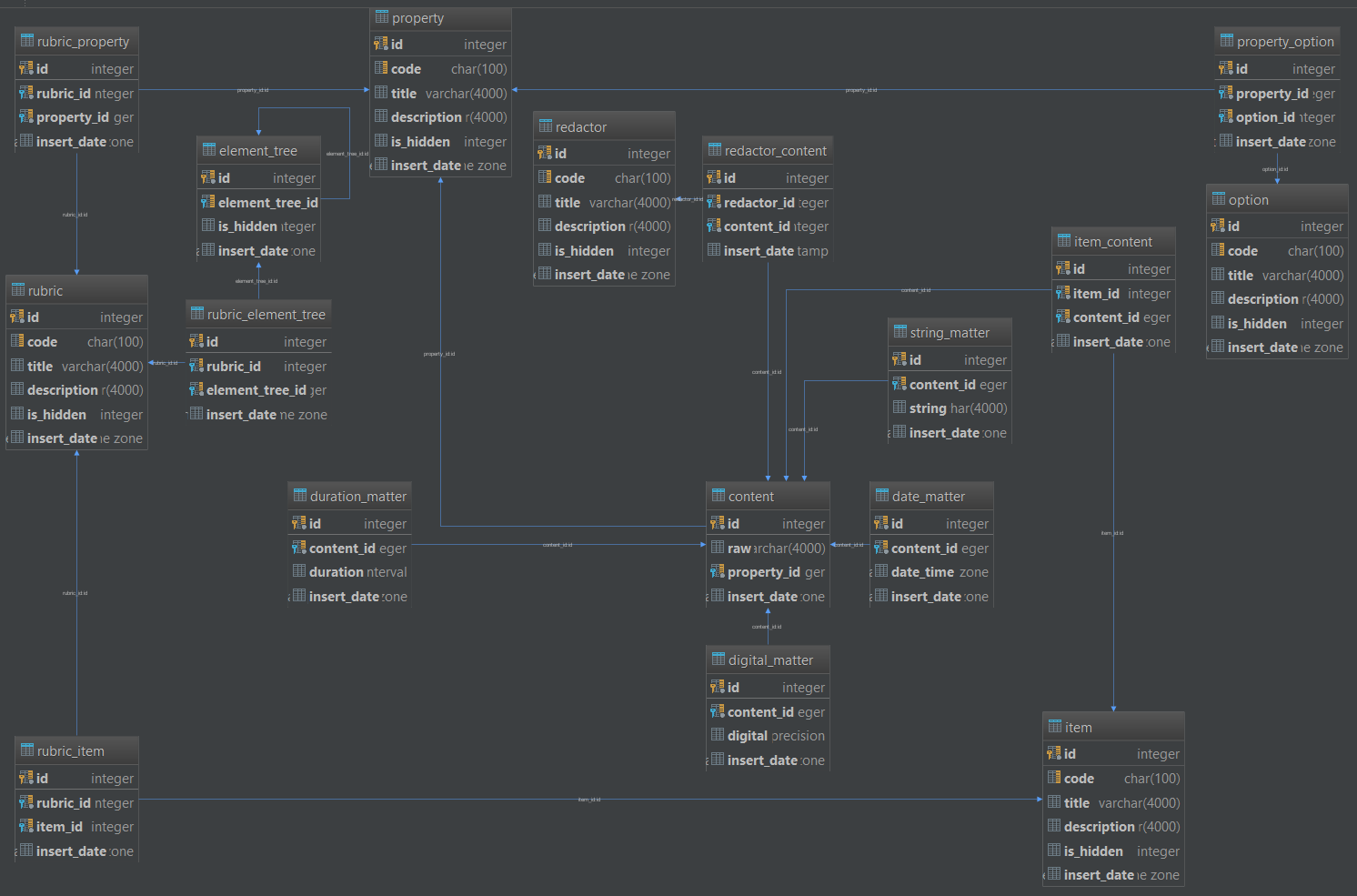
Современные масштабируемые системы состоят из микросервисов, каждый из которых отвечает за свою ограниченную задачу. Такая архитектура позволяет не допускать чрезмерного разрастания исходного кода и контролировать технический долг.
В нашем проекте десятки микросервисов, каждый из которых зарезервирован: две или более абсолютно идентичных копии сервиса установлены на разных физических серверах, и клиент (другой микросервис) может обращаться к любой из них независимо.
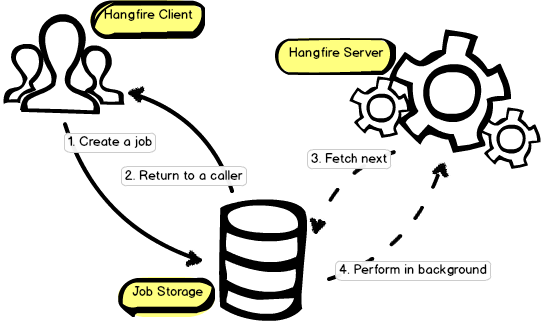
Если микросервис перестает отвечать на запросы в результате аварии, его клиенты должны быть мгновенно перенаправлены на резервный. Для управления потоком запросов часто используют так называемые очереди сообщений (message queues).
Недавно используемая нами очередь перестала нас устраивать по параметрам отказоустойчивости и мы заменили ее. Ниже мы делимся нашим опытом выбора.
В нашем проекте десятки микросервисов, каждый из которых зарезервирован: две или более абсолютно идентичных копии сервиса установлены на разных физических серверах, и клиент (другой микросервис) может обращаться к любой из них независимо.
Если микросервис перестает отвечать на запросы в результате аварии, его клиенты должны быть мгновенно перенаправлены на резервный. Для управления потоком запросов часто используют так называемые очереди сообщений (message queues).
Недавно используемая нами очередь перестала нас устраивать по параметрам отказоустойчивости и мы заменили ее. Ниже мы делимся нашим опытом выбора.