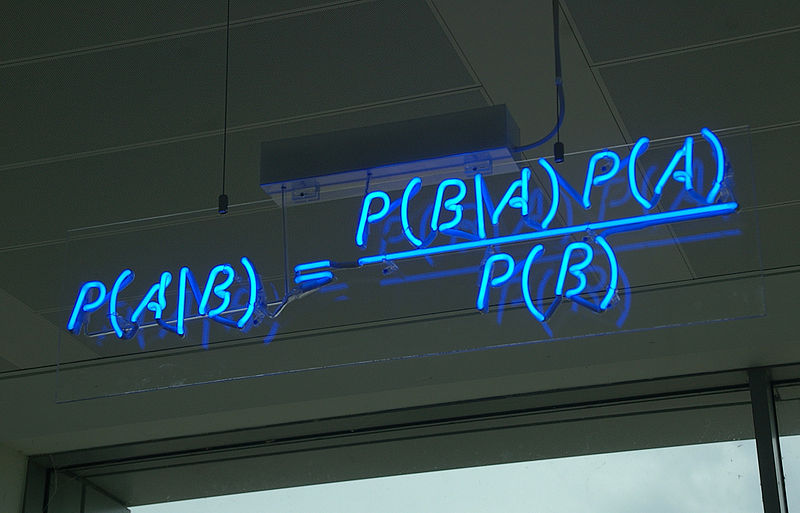Если Вам не очень повезло, и на работе нет n-ядерного монстра, которого можно загрузить своими скриптами, то эта статья для Вас. Также если Вы привыкли запускать скрипты на всю ночь (и утром читать, что где-то забыли скобочку, и 6 часов вычислений пропали) — у Вас есть шанс наконец познакомиться с Amazon Web Services.

В этой статье я расскажу, как начать работать с сервисом EC2. По сути это пошаговая инструкция по полуавтоматической аренде спотового инстанса AWS для работы с Jupyter-блокнотами и сборкой библиотек Anaconda. Будет полезно, например, тем, кто в соревнованиях Kaggle все еще пользуется своим игрушечным маком.
В этой статье я расскажу, как начать работать с сервисом EC2. По сути это пошаговая инструкция по полуавтоматической аренде спотового инстанса AWS для работы с Jupyter-блокнотами и сборкой библиотек Anaconda. Будет полезно, например, тем, кто в соревнованиях Kaggle все еще пользуется своим игрушечным маком.
 Каждый должен делать свою работу качественно и в срок. Допустим, вам нужно сделать веб-сервис классификации картинок на базе обученной нейронной сети с помощью библиотеки
Каждый должен делать свою работу качественно и в срок. Допустим, вам нужно сделать веб-сервис классификации картинок на базе обученной нейронной сети с помощью библиотеки 
 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест 

 Сначала я хотел честно и подробно написать о методах снижения размерности данных —
Сначала я хотел честно и подробно написать о методах снижения размерности данных —