Примечание переводчика: После публикации статьи с автором связался коммерческий директор из King.com, создателя Candy Crush Saga, и прояснил несколько моментов, после чего автор добавил пару замечаний. Добавленные абзацы отмечены курсивом.
Модель принудительной монетизации основывается на уловках, с помощью которых можно заставить человека совершить покупку с неполной информацией, или сокрытии этой информации так, что технически она остаётся доступной, но мозг потребителя не улавливает эту информацию. Сокрытие покупки может быть осуществлено с помощью простой маскировки связи между действием и ценой, как я писал в статье Системы контроля в F2P.
Согласно исследованиям, добавление даже одной промежуточной валюты между потребителем и реальными деньгами, например «игровых самоцветов» (премиальная валюта), делает потребителя гораздо менее подготовленными к оценке стоимости сделки. Лишние промежуточные предметы, я называю их «наслоения», делают для мозга оценку ситуации очень сложной, особенно под напряжением.
Этот дополнительный стресс часто подаётся в форме того, что Роджер Дики из Zynga называет «весёлыми мучениями». Приём заключается в том, чтобы поставить потребителя в очень неудобное или неприятное положение в игре, а потом предложить ему убрать эти «мучения» в обмен на деньги. Эти деньги всегда замаскированы в слоях принудительной монетизации, поскольку потребитель, столкнувшийся с «реальной» покупкой, скорее всего не поведётся на трюк.
Принудительная монетизация
Модель принудительной монетизации основывается на уловках, с помощью которых можно заставить человека совершить покупку с неполной информацией, или сокрытии этой информации так, что технически она остаётся доступной, но мозг потребителя не улавливает эту информацию. Сокрытие покупки может быть осуществлено с помощью простой маскировки связи между действием и ценой, как я писал в статье Системы контроля в F2P.
Согласно исследованиям, добавление даже одной промежуточной валюты между потребителем и реальными деньгами, например «игровых самоцветов» (премиальная валюта), делает потребителя гораздо менее подготовленными к оценке стоимости сделки. Лишние промежуточные предметы, я называю их «наслоения», делают для мозга оценку ситуации очень сложной, особенно под напряжением.
Этот дополнительный стресс часто подаётся в форме того, что Роджер Дики из Zynga называет «весёлыми мучениями». Приём заключается в том, чтобы поставить потребителя в очень неудобное или неприятное положение в игре, а потом предложить ему убрать эти «мучения» в обмен на деньги. Эти деньги всегда замаскированы в слоях принудительной монетизации, поскольку потребитель, столкнувшийся с «реальной» покупкой, скорее всего не поведётся на трюк.
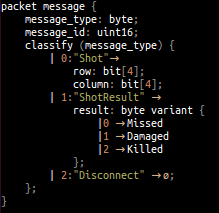 Всем программистам рано или поздно приходится передавать данные. Ни для кого не секрет, что библиотек сериализации в Java существует примерно >9000, а в C++ они вроде и есть, а вроде их и нет. К счастью для большинства, несколько лет назад появился Google Protobuf, который принёс достаточно удобный способ определять структуры данных и быстро завоевал всенародную любовь. Это была фактически первая, доступная широким массам библиотека, позволяющая гонять по сети готовые структуры данных, не связываясь при этом с чем-то вроде XML. На дворе был 2008 год.
Всем программистам рано или поздно приходится передавать данные. Ни для кого не секрет, что библиотек сериализации в Java существует примерно >9000, а в C++ они вроде и есть, а вроде их и нет. К счастью для большинства, несколько лет назад появился Google Protobuf, который принёс достаточно удобный способ определять структуры данных и быстро завоевал всенародную любовь. Это была фактически первая, доступная широким массам библиотека, позволяющая гонять по сети готовые структуры данных, не связываясь при этом с чем-то вроде XML. На дворе был 2008 год.