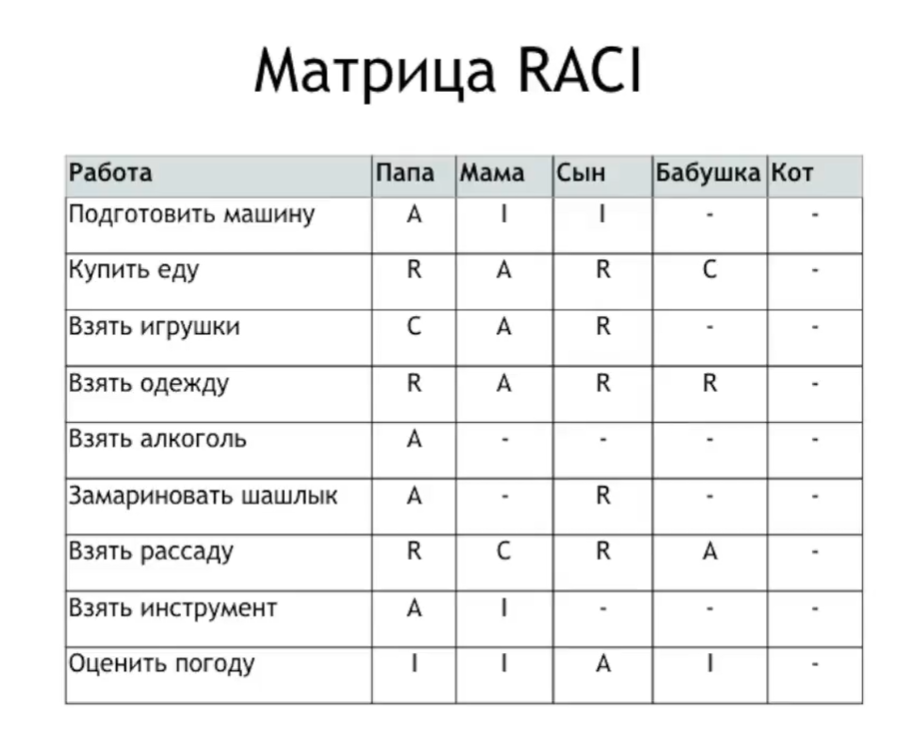
Занимаясь разработкой веб-карт, использующих данные
OpenStreetMap, часто возникает вопрос о том, как показывать карты с корректными русскими названиями. Этой проблемы не возникает, если ваши карты показывают исключительно
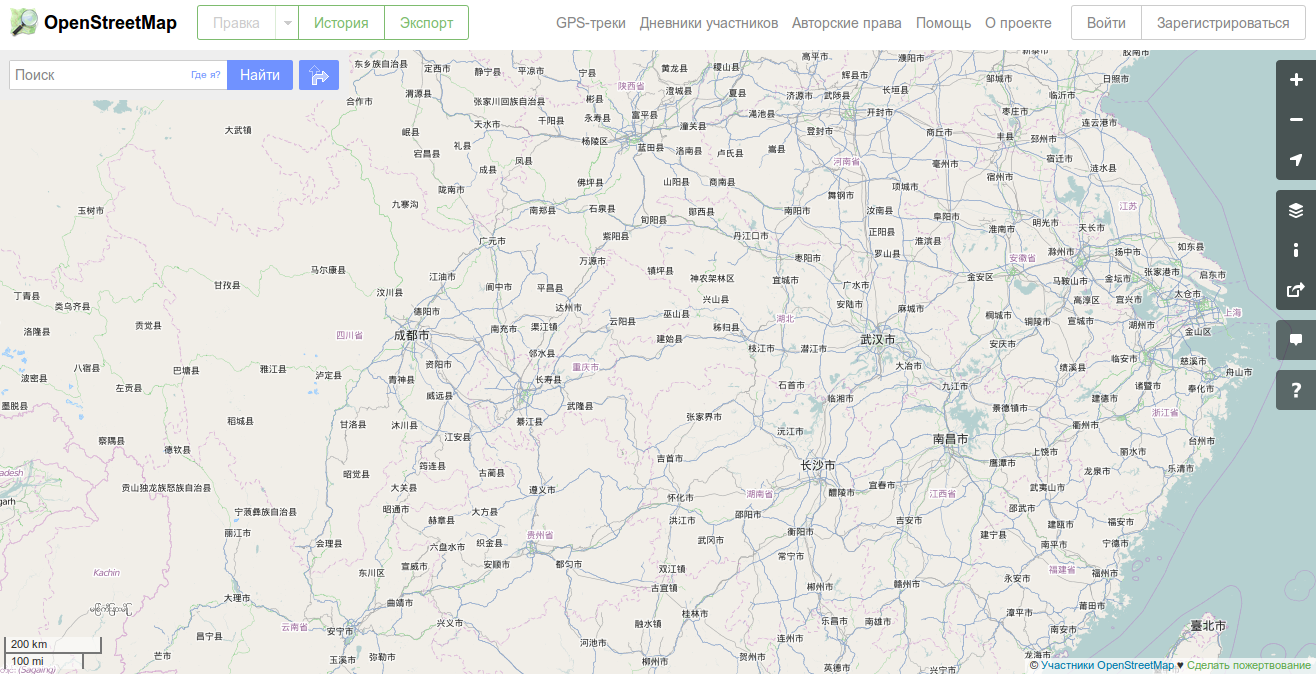
Россию. Однако, если вы посмотрите, например, карту
Китая, то вам вряд ли понравится такое обилие иероглифов, а тщетные попытки найти Пекин на такой карте, скорее всего, не увенчаются успехом.
 Известно
Известно, что свободолюбивый проект
OpenStreetMap позволяет сохранять названия географических объектов на разных языках. Для этого используются специальные теги, типа
name:ru,
name:en или
name:es, и что самое главное, они заполняются участниками
OpenStreetMap. Конечно, наиболее подробные надписи создают пользователи на том языке, на котором они говорят: в России — на русском, в Китае — на китайском, в африканских странах — на местных языках. Шансов, что какая-то улочка в Нигерии будет иметь русский перевод, мало, но все же основные географические объекты (страны, города, реки и т.п.) имеют переводы. Этой небольшой картографической информации бывает вполне достаточно, чтобы русскоязычный пользователь открыл, например, карту Китая и нашел на ней основные названия. Таким образом, ваш ресурс станет чуть более дружелюбным для пользователя.