
В 2007 году Яндекс столкнулся с вирусом, массово подменявшим на компьютерах пользователей поисковую выдачу Яндекса. Вместо релевантных результатов подставлялась реклама, не относящаяся к запросу. Нужно было срочно искать решение проблемы. Изучая ее, мы выяснили, что вирус попадает на пользовательские компьютеры при помощи атак типа drive-by-download. Зараженные страницы инициируют скрытые загрузки вредоносных файлов. Затем, эксплуатируя уязвимости пользовательской системы, вредоносное ПО устанавливается на компьютер.
Антивирусные программы не всегда хорошо защищают пользователей от этого типа атак и нового, только что перепакованного, вредоносного ПО, поэтому пользователям требуется дополнительная защита. Мы осознали, что чтобы побороть данное явление, нужно детектировать заражение сайтов, помогать вебмастерам удалять вредоносный код, а также мотивировать их не участвовать в партнерских сетях, через которые распространяются блоки drive-by-download-атак.
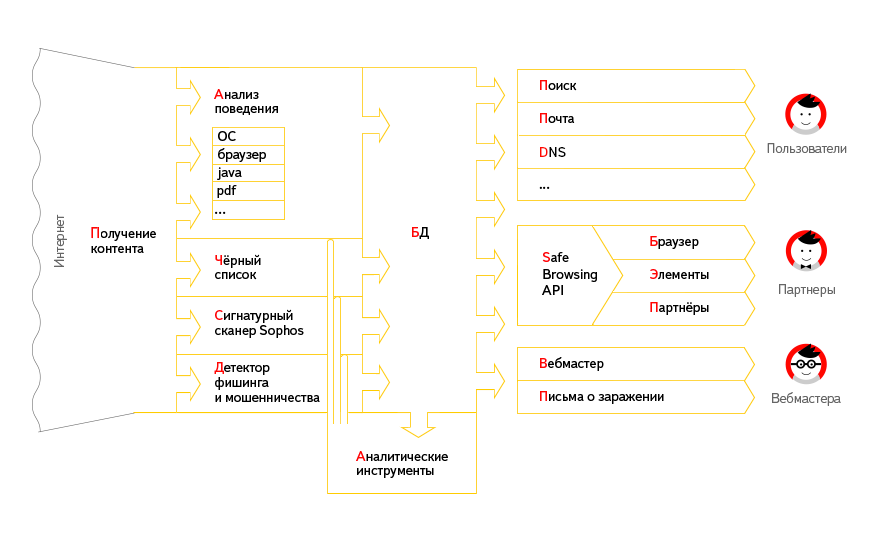
Антивирусные программы не всегда хорошо защищают пользователей от этого типа атак и нового, только что перепакованного, вредоносного ПО, поэтому пользователям требуется дополнительная защита. Мы осознали, что чтобы побороть данное явление, нужно детектировать заражение сайтов, помогать вебмастерам удалять вредоносный код, а также мотивировать их не участвовать в партнерских сетях, через которые распространяются блоки drive-by-download-атак.

 The Khronos Group 18 ноября 2013 года
The Khronos Group 18 ноября 2013 года 





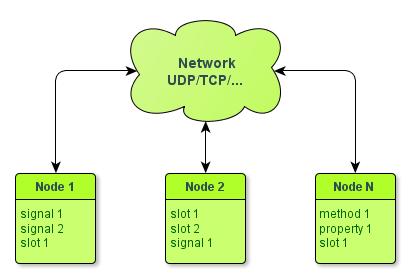


 Доброго вечера, дорогие Хабровчане. Мы продолжаем изучение Erlang для самых маленьких.
Доброго вечера, дорогие Хабровчане. Мы продолжаем изучение Erlang для самых маленьких. 