Проблема решена: 317 кликов исправили ошибку
В 1992 году я считал себя лучшим программистом в мире. В свое оправдание могу сказать лишь, что тогда я только закончил колледж (это было еще до появления Интернета) и жил в Боулдере, штат Колорадо, подрабатывая в мелких компаниях – я почитал за большую удачу возможность просто услышать о других программистах, не говоря уже о том, чтобы повстречаться с ними.
В итоге я познакомился с человеком по имени Билл О’Нил, который нанял меня в качестве программиста, работающего по контракту. Он создал компанию с довольно неоригинальным названием Computer Research & Technologies, и мы стали работать над различными задачами вместе.
Мы занимались разработкой CRUD-приложений [Create, Read, Update, Delete – вариант приложения с базовыми функциями создания, просмотра, обновления и удаления записей в базе данных – прим. перев.] для бизнеса на Visual Basic и FoxPro под Windows 3.1 (и иногда под DOS, так как предчувствовали, что новомодный графический интерфейс останется с нами надолго).
Билл был первым профессиональным программистом, с которым я когда-либо работал. Да что тут говорить, он был первым программистом вообще, с которым я когда-либо работал. Он выдавал мне техзадание, по нему я писал программу на Visual Basic и затем отдавал ее на проверку Биллу. После этого он спокойно объяснял мне, что мой код никуда не годится.

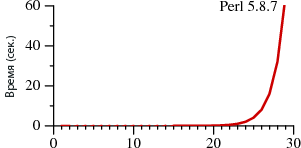
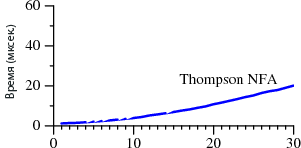






 На недавнем Laracon NYC я читал доклад о гексагональной архитектуре. Несмотря на то, что я получил позитивную реакцию слушателей, мне кажется, что остались люди, которые хотели бы получить чуть более полное представление о том, что это такое. Разумеется, с примерами. Это моя попытка расширить тот доклад.
На недавнем Laracon NYC я читал доклад о гексагональной архитектуре. Несмотря на то, что я получил позитивную реакцию слушателей, мне кажется, что остались люди, которые хотели бы получить чуть более полное представление о том, что это такое. Разумеется, с примерами. Это моя попытка расширить тот доклад.