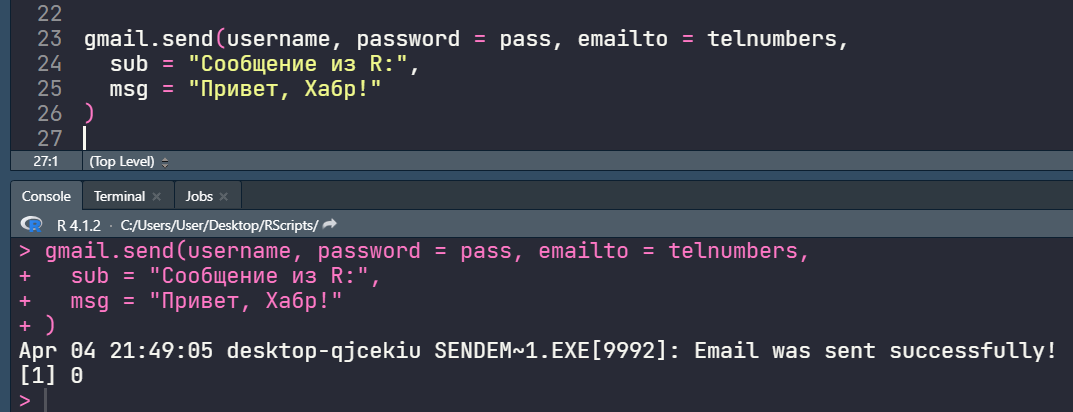
Обход графа: поиск в глубину и поиск в ширину простыми словами на примере JavaScript
5 мин
Перевод
Доброго времени суток.
Представляю вашему вниманию перевод статьи «Algorithms on Graphs: Let’s talk Depth-First Search (DFS) and Breadth-First Search (BFS)» автора Try Khov.
Простыми словами, обход графа — это переход от одной его вершины к другой в поисках свойств связей этих вершин. Связи (линии, соединяющие вершины) называются направлениями, путями, гранями или ребрами графа. Вершины графа также именуются узлами.
Двумя основными алгоритмами обхода графа являются поиск в глубину (Depth-First Search, DFS) и поиск в ширину (Breadth-First Search, BFS).
Несмотря на то, что оба алгоритма используются для обхода графа, они имеют некоторые отличия. Начнем с DFS.
Представляю вашему вниманию перевод статьи «Algorithms on Graphs: Let’s talk Depth-First Search (DFS) and Breadth-First Search (BFS)» автора Try Khov.
Что такое обход графа?
Простыми словами, обход графа — это переход от одной его вершины к другой в поисках свойств связей этих вершин. Связи (линии, соединяющие вершины) называются направлениями, путями, гранями или ребрами графа. Вершины графа также именуются узлами.
Двумя основными алгоритмами обхода графа являются поиск в глубину (Depth-First Search, DFS) и поиск в ширину (Breadth-First Search, BFS).
Несмотря на то, что оба алгоритма используются для обхода графа, они имеют некоторые отличия. Начнем с DFS.



 Здравствуйте, коллеги. В конце 1960-ых годов прошлого века
Здравствуйте, коллеги. В конце 1960-ых годов прошлого века 



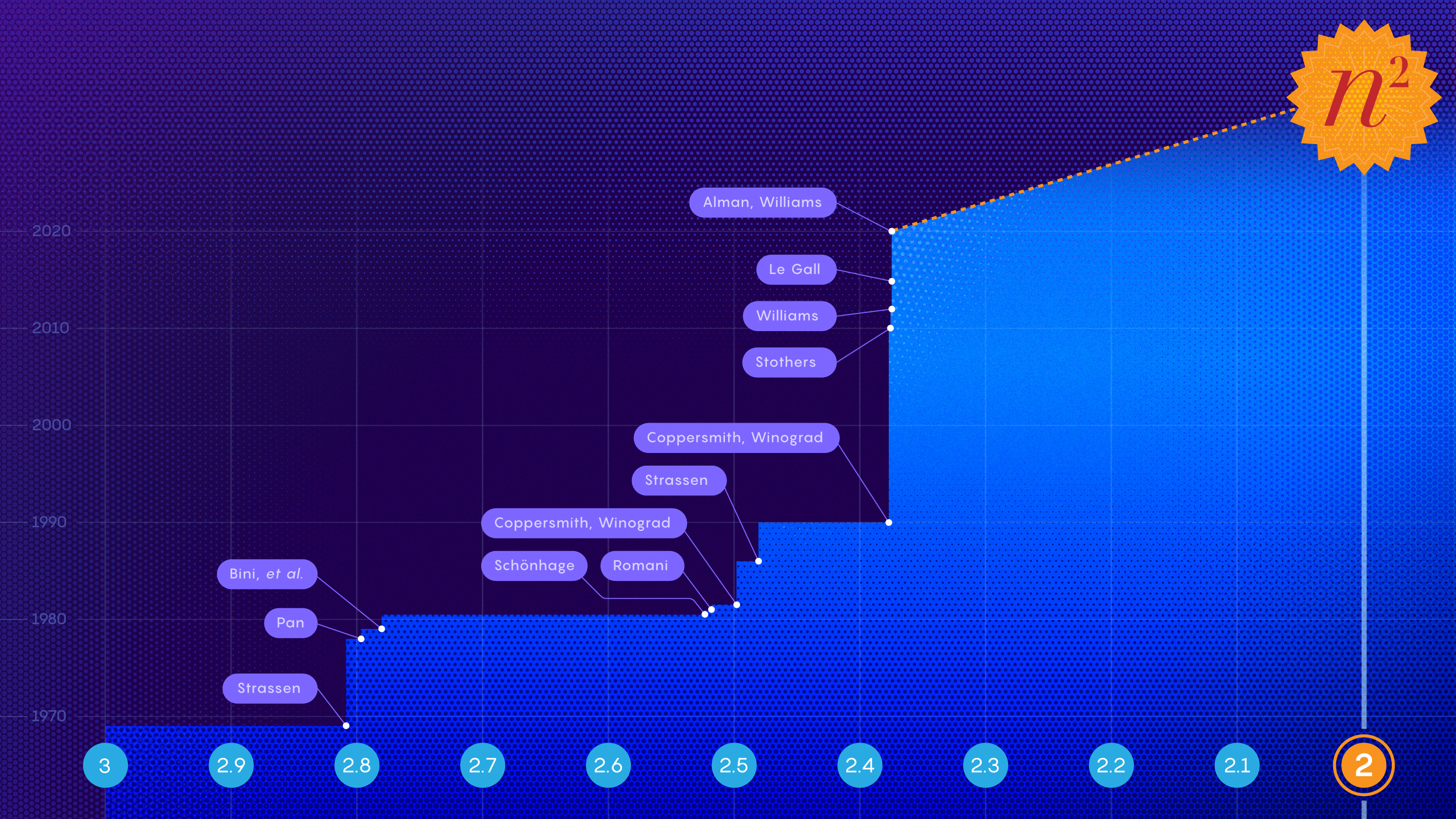
 Изображение предоставлено автором. Основано
Изображение предоставлено автором. Основано