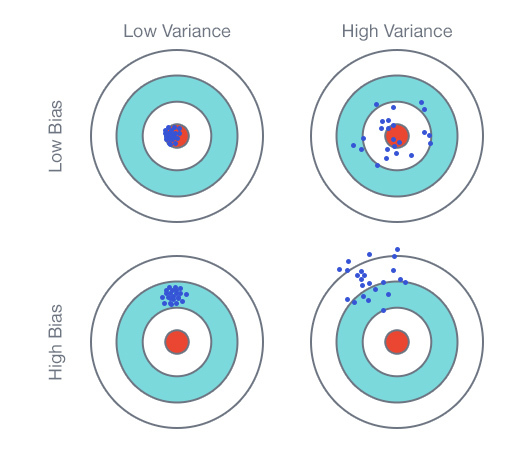
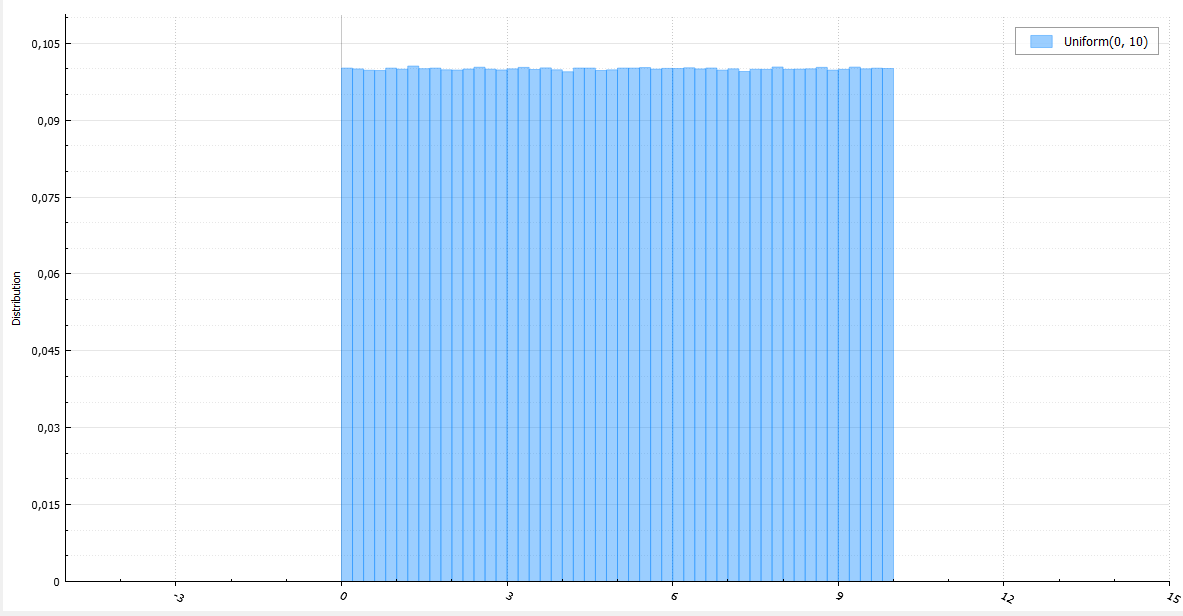
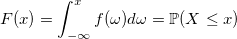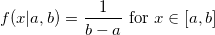Эта статья предназначена в первую очередь для программистов-одиночек, желающих попробовать свои силы на рынке платных мобильных приложений. Статья не претендует на истину первой инстанции, поэтому любые ваши замечания крайне приветствуются.
Итак, суть статьи заключается в том, чтобы понять: можно ли в РФ физическому лицу законно получать прибыль от продаж программ в App Store? Просмотр тематических форумов с подобными вопросами привел к выводу: мнения людей на этот счет расходятся. Одни считают, что можно, другие — что такая деятельность будет квалифицироваться как незаконная предпринимательская деятельность, т.к. договор от Apple — это агентский договор и в нем нет ни слова про авторские вознаграждения, и, как следствие, нужно регистрироваться в качестве индивидуального предпринимателя (ИП).
Итак, суть статьи заключается в том, чтобы понять: можно ли в РФ физическому лицу законно получать прибыль от продаж программ в App Store? Просмотр тематических форумов с подобными вопросами привел к выводу: мнения людей на этот счет расходятся. Одни считают, что можно, другие — что такая деятельность будет квалифицироваться как незаконная предпринимательская деятельность, т.к. договор от Apple — это агентский договор и в нем нет ни слова про авторские вознаграждения, и, как следствие, нужно регистрироваться в качестве индивидуального предпринимателя (ИП).
 Сначала я хотел честно и подробно написать о методах снижения размерности данных —
Сначала я хотел честно и подробно написать о методах снижения размерности данных —