Привет Хабр! Пару месяцев назад я захотел провести тестирование производительности некоторых сетевых фреймворков, c целью понять насколько большая разбежка между ними. Надо ли использовать Node.js там, где хотелось бы Python с Gevent или нужен Ruby с его EventMachine.
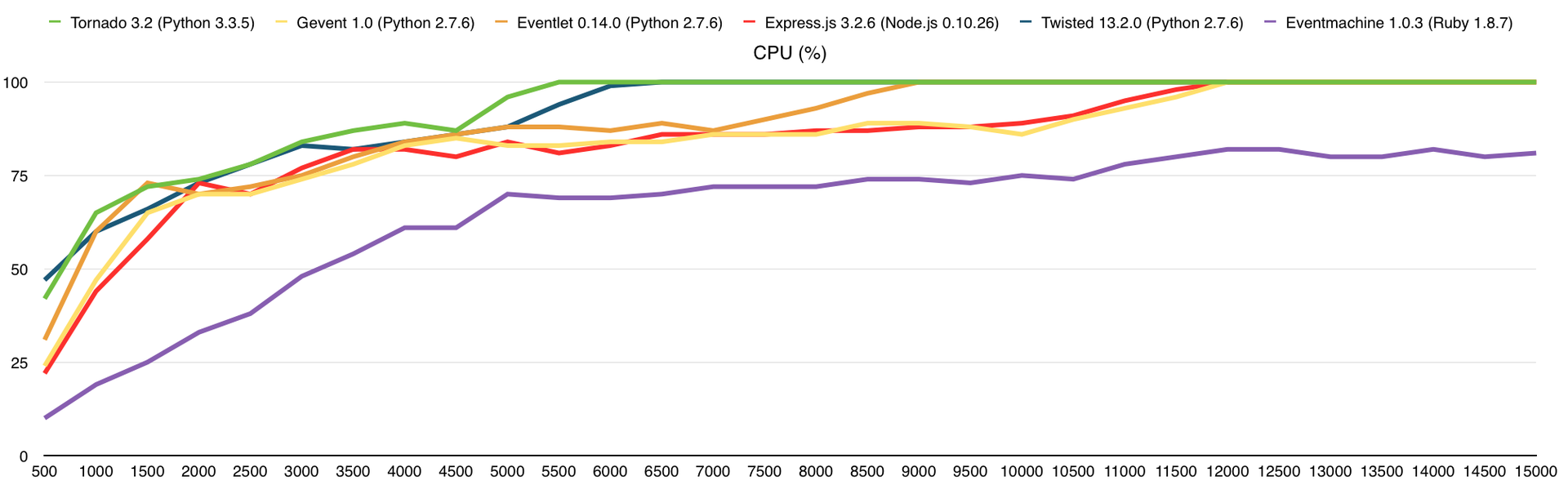
Я хочу обратить ваше внимание на то, что эти материалы не являются руководством к выбору фреймворка и могут содержать спорные моменты. Я вообще не собирался публиковать результаты этого исследования, но когда они попадались мне на глаза я ловил себя на мысли, что это может быть кому-нибудь полезно. Теперь я начну забрасывать вас графиками.
Я хочу обратить ваше внимание на то, что эти материалы не являются руководством к выбору фреймворка и могут содержать спорные моменты. Я вообще не собирался публиковать результаты этого исследования, но когда они попадались мне на глаза я ловил себя на мысли, что это может быть кому-нибудь полезно. Теперь я начну забрасывать вас графиками.