Если вы решили попробовать замечательный язык Go, но не знаете с чего начать, вам прямая дорога в этот пост, где я постарался перечислить все необходимые для новичков ресурсы.

movb @movb
Пользователь
Изучение React — для чего, откуда, как?
7 мин
Туториал
С чего начать изучение новой библиотеки или фрейморка? Сразу же найти статью на Хабре и с головой погрузиться в пучину практических примеров? Или сначала тщательно изучить официальную и неофициальную документацию, прежде чем перейти к практике? Именно между этими вопросами будет метаться ваше сознание, когда вы решите узнать, что же такое ReactJS. Чтобы желание учиться не умерло, как знаменитый ослик, обязательно загляните под капот.
Изучаем net/context в Go
11 мин
Туториал
Не секрет, что основная ниша использования Go это сетевые сервисы: всевозможные серверы, бекенды, микросервисы, распределенные базы данных и файловые хранилища. Такой класс программ очень активно использует сетевые запросы, весь необходимый функционал для которых есть в стандартной библиотеке, но один аспект разработки сетевых архитектур остается для многих темным пятном — контексты запросов. В этой статье я хочу рассмотреть этот аспект повнимательней и показать, какой это мощный и важный инструмент.

Алгоритм извлечения информации в ABBYY Compreno. Часть 2
5 мин
И снова здравствуйте!
Надеюсь, вас заинтересовал наш вчерашний пост про систему извлечения информации ABBYY Compreno, в котором мы рассказали про архитектуру системы, семантико-синтаксический парсер и его роль и, самое главное, про информационные объекты.
Теперь настало время поговорить о самом интересном – как устроен сам движок извлечения информации.

Надеюсь, вас заинтересовал наш вчерашний пост про систему извлечения информации ABBYY Compreno, в котором мы рассказали про архитектуру системы, семантико-синтаксический парсер и его роль и, самое главное, про информационные объекты.
Теперь настало время поговорить о самом интересном – как устроен сам движок извлечения информации.
Алгоритм извлечения информации в ABBYY Compreno. Часть 1
7 мин
Привет, Хабр!
Меня зовут Илья Булгаков, я программист отдела извлечения информации в ABBYY. В серии из двух постов я расскажу вам наш главный секрет – как работает технология Извлечения Информации в ABBYY Compreno.
Ранее мой коллега Даня Скоринкин DSkorinkin успел рассказать про взгляд на систему со стороны онтоинженера, затронув следующие темы:
В этот раз мы опустимся глубже в недра технологии ABBYY Compreno, поговорим про архитектуру системы в целом, основные принципы ее работы и алгоритм извлечения информации!

Меня зовут Илья Булгаков, я программист отдела извлечения информации в ABBYY. В серии из двух постов я расскажу вам наш главный секрет – как работает технология Извлечения Информации в ABBYY Compreno.
Ранее мой коллега Даня Скоринкин DSkorinkin успел рассказать про взгляд на систему со стороны онтоинженера, затронув следующие темы:
- Деревья семантико-синтаксического разбора и создание онтологий
- Написание правил извлечения информации
В этот раз мы опустимся глубже в недра технологии ABBYY Compreno, поговорим про архитектуру системы в целом, основные принципы ее работы и алгоритм извлечения информации!
Книга «Java EE. Паттерны проектирования для профессионалов»
4 мин
 У нас вышла книга Мурата Йенера и Алекса Фидома.
У нас вышла книга Мурата Йенера и Алекса Фидома.Книга «Java EE. Паттерны проектирования для профессионалов» — незаменимый ресурс для всех, кто желает более эффективно работать с Java EE, а также единственная книга, в которой рассмотрены как теория, так и практика использования паттернов проектирования на примерах реальных прикладных задач.
Авторы знакомят читателя и с фундаментальными, и с наиболее передовыми возможностями Java EE 7, досконально рассматривают каждый из паттернов и демонстрируют, как эти паттерны применяются при решении повседневных прикладных задач.
Go, практика асинхронного взаимодействия
8 мин
Немножко про каналы, про выполнение в основном процессе, про то как вынести блокирующие операции в отдельную горутину.
- Каналы и пустое значение
- Односторонние каналы
- Выполнение в основном треде ОС
- Вынос блокирующих операций
Rust в деталях: пишем масштабируемый чат с нуля, часть 1
31 мин
Перевод
Часть 1: Реализуем WebSocket. Введение.
В этом цикле статей мы рассмотрим процесс создания масштабируемого чата, который будет работать в реальном времени.
Целью данного обзора является пошаговое изучение основ быстро набирающего популярность языка программирования Rust на практике, с попутным охватом системных интерфейсов.
В первой части мы рассмотрим начальную настройку окружения и реализацию простейшего WebSocket-сервера. Чтобы понять технические детали статьи вам не потребуется опыта работы с языком Rust, хотя знание основ системных API (POSIX) и C/C++ лишним не будет. Прежде чем начинать чтение, заготовьте немного времени (и кофе) — статья описывает все максимально подробно и поэтому довольно длинная.
Две задачи HeadHunter на Data Science Week: попробуйте решить сами
5 мин
В конце августа после серии бесплатных лекций на Data Science Week 2015, организаторы решили провести двухдневный дататон (datathon) – соревнование, где команды программистов и аналитиков решали бизнес-задачи из области Data Science.
На дататоне было три задачи, две из которых подготовила команда HeadHunter и одну компания OZON. Это было, сразу скажу, не самым простым заданием, потому как большая часть наших данных конфиденциальна. Никто не захочет, чтобы программисты и аналитики упражнялись на реальных резюме или закрытых данных по вакансиям. Но кое-что мы все же собрали. Для проверки результатов организаторы придумали метрики и написали чекеры. А победили на дататоне эти ребята:

Прямо здесь и сейчас я предлагаю вам испытать свои силы и решить три задачи, с которыми ребята бились на дататоне. Чекеры для проверки и все файлы прилагаю.
На дататоне было три задачи, две из которых подготовила команда HeadHunter и одну компания OZON. Это было, сразу скажу, не самым простым заданием, потому как большая часть наших данных конфиденциальна. Никто не захочет, чтобы программисты и аналитики упражнялись на реальных резюме или закрытых данных по вакансиям. Но кое-что мы все же собрали. Для проверки результатов организаторы придумали метрики и написали чекеры. А победили на дататоне эти ребята:
Прямо здесь и сейчас я предлагаю вам испытать свои силы и решить три задачи, с которыми ребята бились на дататоне. Чекеры для проверки и все файлы прилагаю.
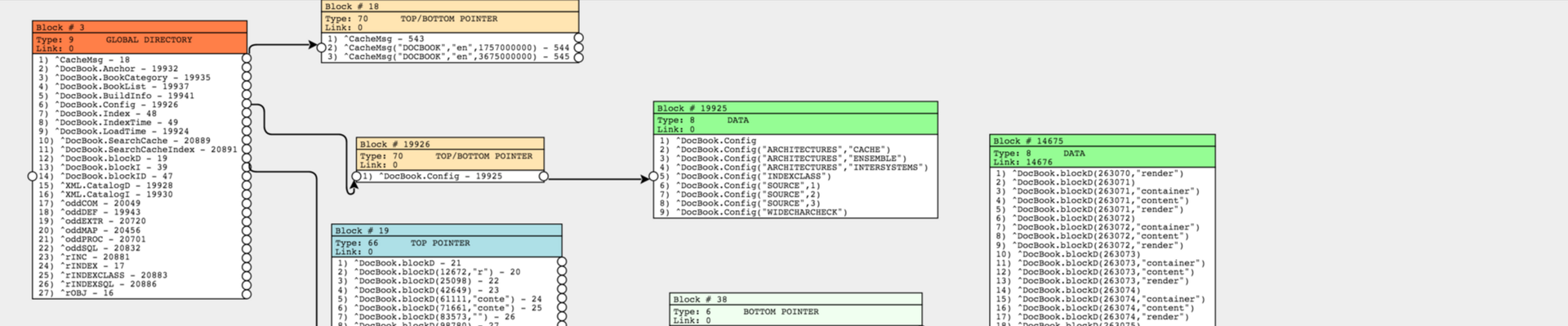
Блоки. Внутреннее устройство файла базы данных Caché
5 мин
Не так давно на хабре в блоге InterSystems были выложены статьи о том, что собой представляет глобал в Caché, с чем его готовят и как подают (часть 1 и часть 2). Это всё, конечно, интересно, удобство работы с любыми моделями данных, какие только пожелает разработчик. Но что обеспечивает хорошую скорость обращения с этими глобалами?
Flux в картинках
5 мин
Туториал
Перевод
Нам в Хекслете нравится ReactJS и Flux. Нам кажется, что это правильное направления развития. Мы любим функциональное программирование и чистые функции, и когда сложные архитектуры упрощаются за счет подходов, связанных с ними — это круто. По Реакту уже есть немало ресурсов в интернете, в том числе наш практический курс по React JS. Последний урок в этом курсе называется «Однонаправленное распространение данных», и там мы подходим к интересной теме, которая лежит в основе архитектуры Flux.
Flux это паттерн распространения даных в приложении. Flux и React выросли в стенах Фейсбука вместе. Многие используют их одновременно, но ничто не мешает использовать их по отдельности. Они были созданы для решения конкретной проблемы в Фейсбуке.
Мы используем React и Flux в своей браузерной среде разработки Hexlet IDE (она в опен-сорсе), в которой учащиеся выполняют практические задания. Flux одновременно очень популярен и очень непонятен для многих в мире веба. Сегодняшний перевод — попытка объяснить Flux на пальцах (ну, то есть картинках).
Вначале нужно понять, какую проблему решает Flux.
Flux это паттерн распространения даных в приложении. Flux и React выросли в стенах Фейсбука вместе. Многие используют их одновременно, но ничто не мешает использовать их по отдельности. Они были созданы для решения конкретной проблемы в Фейсбуке.
Мы используем React и Flux в своей браузерной среде разработки Hexlet IDE (она в опен-сорсе), в которой учащиеся выполняют практические задания. Flux одновременно очень популярен и очень непонятен для многих в мире веба. Сегодняшний перевод — попытка объяснить Flux на пальцах (ну, то есть картинках).
Проблема
Вначале нужно понять, какую проблему решает Flux.
Big Data от А до Я. Часть 2: Hadoop
9 мин
Туториал
Привет, Хабр! В предыдущей статье мы рассмотрели парадигму параллельных вычислений MapReduce. В этой статье мы перейдём от теории к практике и рассмотрим Hadoop – мощный инструментарий для работы с большими данными от Apache foundation.
В статье описано, какие инструменты и средства включает в себя Hadoop, каким образом установить Hadoop у себя, приведены инструкции и примеры разработки MapReduce-программ под Hadoop.

В статье описано, какие инструменты и средства включает в себя Hadoop, каким образом установить Hadoop у себя, приведены инструкции и примеры разработки MapReduce-программ под Hadoop.
Создаём REST-сервис на PostgreSQL и Rust. Часть 1: прототип
6 мин
Туториал
Всем привет.
Какое-то время назад я видел в небезызвестном блоге пост о том, как реализовать на Go простую программу, работающую с БД, а затем сделать на её базе целый REST-сервис. Я решил проверить, насколько сложно сделать аналогичную программу на Rust и поделиться результатами.
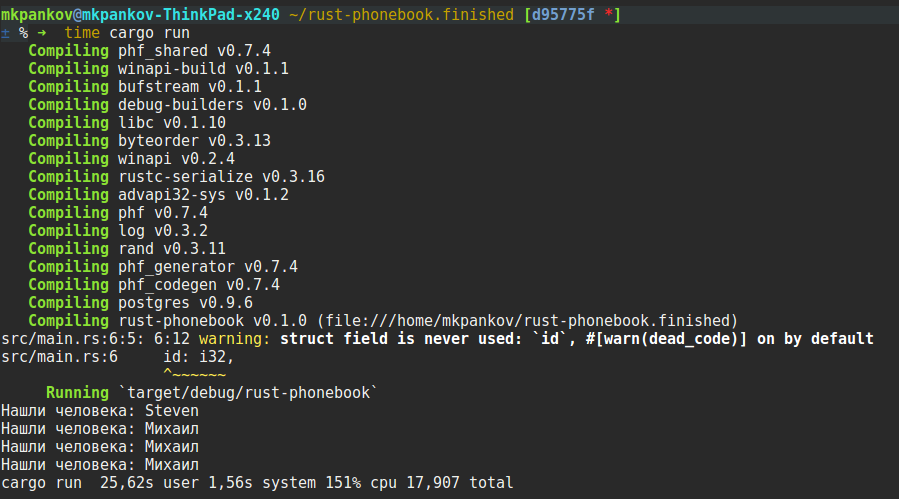
Мы начнём с работы с БД и создадим обычное консольное приложение, а затем добавим, так сказать, REST-фронтенд.
Какое-то время назад я видел в небезызвестном блоге пост о том, как реализовать на Go простую программу, работающую с БД, а затем сделать на её базе целый REST-сервис. Я решил проверить, насколько сложно сделать аналогичную программу на Rust и поделиться результатами.
Мы начнём с работы с БД и создадим обычное консольное приложение, а затем добавим, так сказать, REST-фронтенд.
Препарируем t-SNE
10 мин
Туториал
Работая над статьей «Глубокое обучение на R...», я несколько раз встречал упоминание t-SNE — загадочной техники нелинейного снижения размерности и визуализации многомерных переменных (например, здесь), был заинтригован и решил разобраться во всем в деталях. t-SNE это t-distributed stochastic neighbor embedding. Русский вариант с «внедрением соседей» в некоторой мере звучит нелепо, поэтому дальше буду использовать английский акроним.
Модификаторы private и private[this] в Scala
5 мин
В Scala, помимо обычного модификатора доступа private существует также модификатор private[this]. Эти два модификатора довольно похожи друг на друга. К тому же в Java есть только простой private. Поэтому они легко могут вызвать путаницу или убежденность, что простой private — не такой уж и приватный, и везде надо использовать private[this] для пущей защищенности. Но давайте разберемся, как дела обстоят на самом деле.
Шпаргалка Java программиста 2: Триста пятьдесят самых популярных не мобильных Java opensource проектов на github
39 мин
Что это и зачем оно надо: Как известно, главное преимущество Java мира в том в нем существует огромное количество open-source проектов на на все случаи жизни, однако найти нужный на github'e не так просто, так как описание проекта часто мало информативно, зачастую сложно даже понять этот проект для Android'a или нет. В этой статье я автоматически и полуавтоматически собрал Java проекты, убрал старые и проекты только для Android'a, выбрал 350 набравших больше всего звезд, разделил по категориям и перевел описания.
Если вы хотите убедиться что базы данных пишут не только на C, найти проекты для работы с большими данными или нейронными сетями, пишите свой язык программирования для JVM и хотите посмотреть как это уже сделано или же просто хотите узнать какие новые возможности можно найти в Java мире open-source то это статья вам, думаю, может пригодится.
Другие статьи серии: часть 1. JPA и Hibernate в вопросах и ответах
Update: Внимание, актуальная версия со много большим количеством ссылок, находиться теперь в моем github'e проекте useful-java-links, по этой ссылке.
Если вы хотите убедиться что базы данных пишут не только на C, найти проекты для работы с большими данными или нейронными сетями, пишите свой язык программирования для JVM и хотите посмотреть как это уже сделано или же просто хотите узнать какие новые возможности можно найти в Java мире open-source то это статья вам, думаю, может пригодится.
В чем смысл серии статей 'Шпаргалки Java программиста'
За время работы Java программистом я заметил, что как правило программисты постоянно и планомерно используют от силы 10-20% от возможностей той или иной технологии, при этом остальные возможности быстро забываются и при появлении новых требований, переходе на новую работу или подготовке к техническому интервью приходится перечитывать все документации и спецификации с нуля. Зато наличие краткого конспекта особенностей тех или иных технологий (шпаргалок) позволяет быстро освежить в памяти особенности той или иной технологии.
Другие статьи серии: часть 1. JPA и Hibernate в вопросах и ответах
Update: Внимание, актуальная версия со много большим количеством ссылок, находиться теперь в моем github'e проекте useful-java-links, по этой ссылке.
Общее оглавление 'Шпаргалок'
1. JPA и Hibernate в вопросах и ответах
2. Триста пятьдесят самых популярных не мобильных Java opensource проектов на github
3. Коллекции в Java (стандартные, guava, apache, trove, gs-collections и другие
4. Java Stream API
5. Двести пятьдесят русскоязычных обучающих видео докладов и лекций о Java
6. Список полезных ссылок для Java программиста
7 Типовые задачи
7.1 Оптимальный путь преобразования InputStream в строку
7.2 Самый производительный способ обхода Map'ы, подсчет количества вхождений подстроки
8. Библиотеки для работы с Json (Gson, Fastjson, LoganSquare, Jackson, JsonPath и другие)
2. Триста пятьдесят самых популярных не мобильных Java opensource проектов на github
3. Коллекции в Java (стандартные, guava, apache, trove, gs-collections и другие
4. Java Stream API
5. Двести пятьдесят русскоязычных обучающих видео докладов и лекций о Java
6. Список полезных ссылок для Java программиста
7 Типовые задачи
7.1 Оптимальный путь преобразования InputStream в строку
7.2 Самый производительный способ обхода Map'ы, подсчет количества вхождений подстроки
8. Библиотеки для работы с Json (Gson, Fastjson, LoganSquare, Jackson, JsonPath и другие)
Неразрешимые задачи и нижние оценки. Лекция Александра Шеня в Яндексе
9 мин
Понятно, зачем теоретики находят эффективные алгоритмы решения задач какого-то класса, а потом практики их реализуют. Но теоретики стараются также доказать, что для некоторых задач эффективных алгоритмов (и даже вообще никаких алгоритмов) не существует. Что при этом им удаётся и не удаётся, и зачем это может быть нужно? В лекции речь идет о «проблеме остановки» и задачах, к которым она сводится, о знаменитом классе NP, а также о простых нижних оценках.
Лекция был прочитана в Малой Школе анализа данных, которую Яндекс организует для старшеклассников. Автор — Александр Шень. Окончил мехмат МГУ, под руководством Владимира Успенского, ученика Колмогорова, защитил диссертацию «Алгоритмические варианты понятия энтропии». Сейчас является сотрудником Института проблем передачи информации им. А.А. Харкевича РАН и Лаборатории Национального центра научных исследований Франции. Научные интересы: алгоритмы, колмогоровская сложность, логика, теория информации. Почти все книги, которые Александр Ханиевич написал о математике и программированию, находятся в свободном доступе.
Под катом — расшифровка лекции.
Лекция был прочитана в Малой Школе анализа данных, которую Яндекс организует для старшеклассников. Автор — Александр Шень. Окончил мехмат МГУ, под руководством Владимира Успенского, ученика Колмогорова, защитил диссертацию «Алгоритмические варианты понятия энтропии». Сейчас является сотрудником Института проблем передачи информации им. А.А. Харкевича РАН и Лаборатории Национального центра научных исследований Франции. Научные интересы: алгоритмы, колмогоровская сложность, логика, теория информации. Почти все книги, которые Александр Ханиевич написал о математике и программированию, находятся в свободном доступе.
Под катом — расшифровка лекции.
Как научиться делать игры: полезные ресурсы
9 мин
Когда я начинал строить свою карьеру в игровой индустрии шесть лет назад, то часто задавался вопросами по геймдеву. Начиная от поиска общего понимания того, как разрабатываются и оперируются онлайн-игры, до частных вопросов типа того, как лучше рекламировать конкретную игру. Тогда было мало структурированной информации по созданию и продвижению игр, новичку разобраться и найти ответы было исключительно сложно. Практически единственным источником информации был собственный опыт и консультации более опытных коллег. Сейчас ситуация кардинально изменилась. Информации по игровой индустрии настолько много, что рискуешь в ней просто утонуть. Для того, чтобы упростить процесс получения нужных мне знаний, я структурировал и делал себе пометки по всем источникам информации о геймдеве. Далее в статье предлагаю всю эту информацию в удобной форме для общего пользования.

Как за месяц сильно прокачаться в Data Science
12 мин
Привет, хабр!

Меня зовут Глеб, я долгое время работаю в ритейловой аналитике и сейчас занимаюсь применением машинного обучения в данной области. Не так давно я познакомился с ребятами из MLClass.ru, которые за очень короткий срок довольно сильно прокачали меня в области Data Science. Благодаря им, буквально за месяц я стал активно сабмитить на kaggle. Поэтому данная серия публикаций будет описывать мой опыт изучения Data Science: все ошибки, которые были допущены, а также ценные советы, которые мне передали ребята. Сегодня я расскажу об опыте участия в соревновании The Analytics Edge (Spring 2015). Это моя первая статья — не судите строго.
Меня зовут Глеб, я долгое время работаю в ритейловой аналитике и сейчас занимаюсь применением машинного обучения в данной области. Не так давно я познакомился с ребятами из MLClass.ru, которые за очень короткий срок довольно сильно прокачали меня в области Data Science. Благодаря им, буквально за месяц я стал активно сабмитить на kaggle. Поэтому данная серия публикаций будет описывать мой опыт изучения Data Science: все ошибки, которые были допущены, а также ценные советы, которые мне передали ребята. Сегодня я расскажу об опыте участия в соревновании The Analytics Edge (Spring 2015). Это моя первая статья — не судите строго.
Видео докладов Badoo с конференции Highload 2014
2 мин
Осенью мы выступали с докладами на одной из лучших технических конференций Highload 2014 и сейчас с удовольствием делимся с вами видео докладов. Вы можете задавать вопросы в комменариях и наши спикеры и остальные эксперты обязательно на них ответят.
1. «Sharding — patterns & antipatterns».
Доклад Алексея Рыбака (Badoo) и Константина kostja Осипова (Mail.ru).
1. «Sharding — patterns & antipatterns».
Доклад Алексея Рыбака (Badoo) и Константина kostja Осипова (Mail.ru).