
Как сейчас проходят собеседования на golang разработчика? Что спрашивают?

Пользователь

Авторский обзор 90+ нейросетевых моделей на основе Transformer для тех, кто не успевает читать статьи, но хочет быть в курсе ситуации и понимать технические детали идущей революции ИИ.



Изображение с сайта oxygen-icons.org
Передавать лог-файлы на центральный сервер:
Условия: в инфраструктуре используются только Linux-сервера.



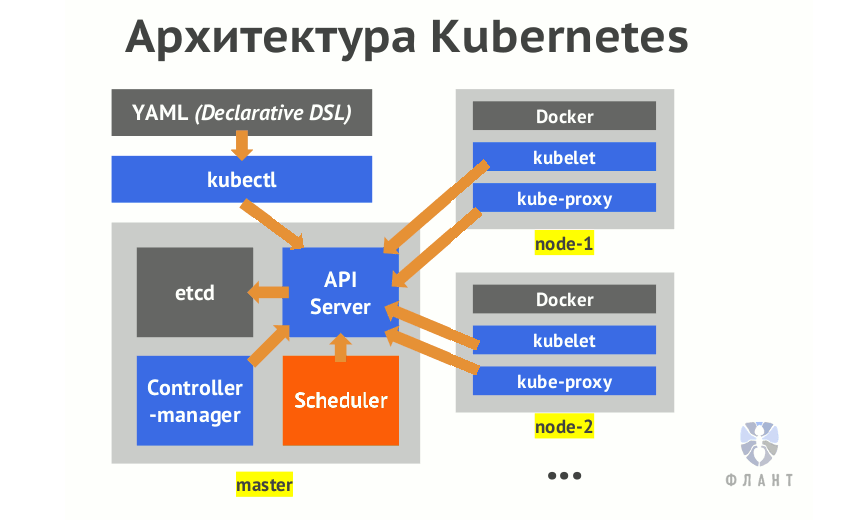
Доминирующей платформой для развертывания контейнеров, несомненно, стал Kubernetes. Он предоставляет возможность управлять практически всем, используя свои API и пользовательские контроллеры, расширяющие его API посредством пользовательских ресурсов.
Тем не менее пользователь все еще должен принимать подробные решения о том, как именно разворачивать, настраивать, управлять и масштабировать приложения. На усмотрение пользователя остаются вопросы масштабирования приложения, защиты, прохождения трафика. Этим Kubernetes отличается от обычных "платформ как услуга" (PaaS), к примеру Cloud Foundry и Heroku.
Платформы обладают упрощенным интерфейсом пользователя, ориентированы на разработчиков приложений, которые чаще всего занимаются настройкой отдельных приложений. Маршрутизация, развертывание и метрики прозрачно для пользователя управляются базовой системой PaaS.

— How big a cluster do I need?
— Well, it depends… (злобное хихиканье)
site:, который ограничивает поисковую выдачу одним сайтом.Программная инженерия — то, что происходит с программированием, если добавить фактор времени и других программистов.
Istio Service Mesh
Мы в Namely уже год как юзаем Istio. Он тогда только-только вышел. У нас здорово упала производительность в кластере Kubernetes, мы хотели распределенную трассировку и взяли Istio, чтобы запустить Jaeger и разобраться. Service mesh так здорово вписалась в нашу инфраструктуру, что мы решили вложиться в этот инструмент.
Пришлось помучиться, но мы изучили его вдоль и поперек. Это первый пост из серии, где я расскажу, как Istio интегрируется с Kubernetes и что мы узнали о его работе. Иногда будем забредать в технические дебри, но не сильно далеко. Дальше будут еще посты.


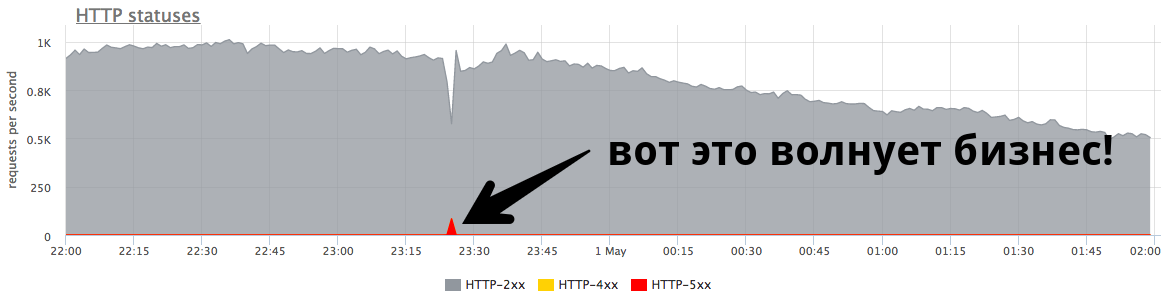
Вам наверняка приходилось восстанавливать кластер Kubernetes после сбоя. Была ли у вас толковая стратегия резервного копирования, не требующая пахать несколько дней? Да, можно делать резервные копии в etcd-кластер, но что если отвалилась только часть кластера или вы используете постоянные тома, вроде AWS EBS?
В таких случаях проще всего использовать утилиту Heptio Ark.

Итак, у вас есть кластер Kubernetes, а для проброса внешнего трафика сервисам внутри кластера вы уже настроили Ingress-контроллер NGINX, ну, или пока только собираетесь это сделать. Класс!
Я тоже через это прошел, и поначалу все выглядело очень просто: установленный NGINX Ingress-контроллер был на расстоянии одного helm install. А затем оставалось лишь подвязать DNS к балансировщику нагрузки и создать необходимые Ingress-ресурсы.
Спустя несколько месяцев весь внешний трафик для всех окружений (dev, staging, production) направлялся через Ingress-серверы. И все было хорошо. А потом стало плохо.
Все мы отлично знаем, как это бывает: сначала вы заинтересовываетесь этой новой замечательной штукой, начинаете ей пользоваться, а затем начинаются неприятности.
kubectl run --image=nginx --replicas=3