Идея совместить демократичность форума, персональность и иерархичность блога, и качественность определения и извлечения ценного контента с помощью коллаборации, наконец-то начинает приобретать реальные очертания.
Мы назвали систему АЗ Сутра. Сутра – это на санскрите «нить», а так же ценное высказывание. Сутра – любая целостная ветвь общения, мне это нравится больше чем thread (тоже «нить», кстати). АЗ – активность и значимость.
Мы назвали систему АЗ Сутра. Сутра – это на санскрите «нить», а так же ценное высказывание. Сутра – любая целостная ветвь общения, мне это нравится больше чем thread (тоже «нить», кстати). АЗ – активность и значимость.
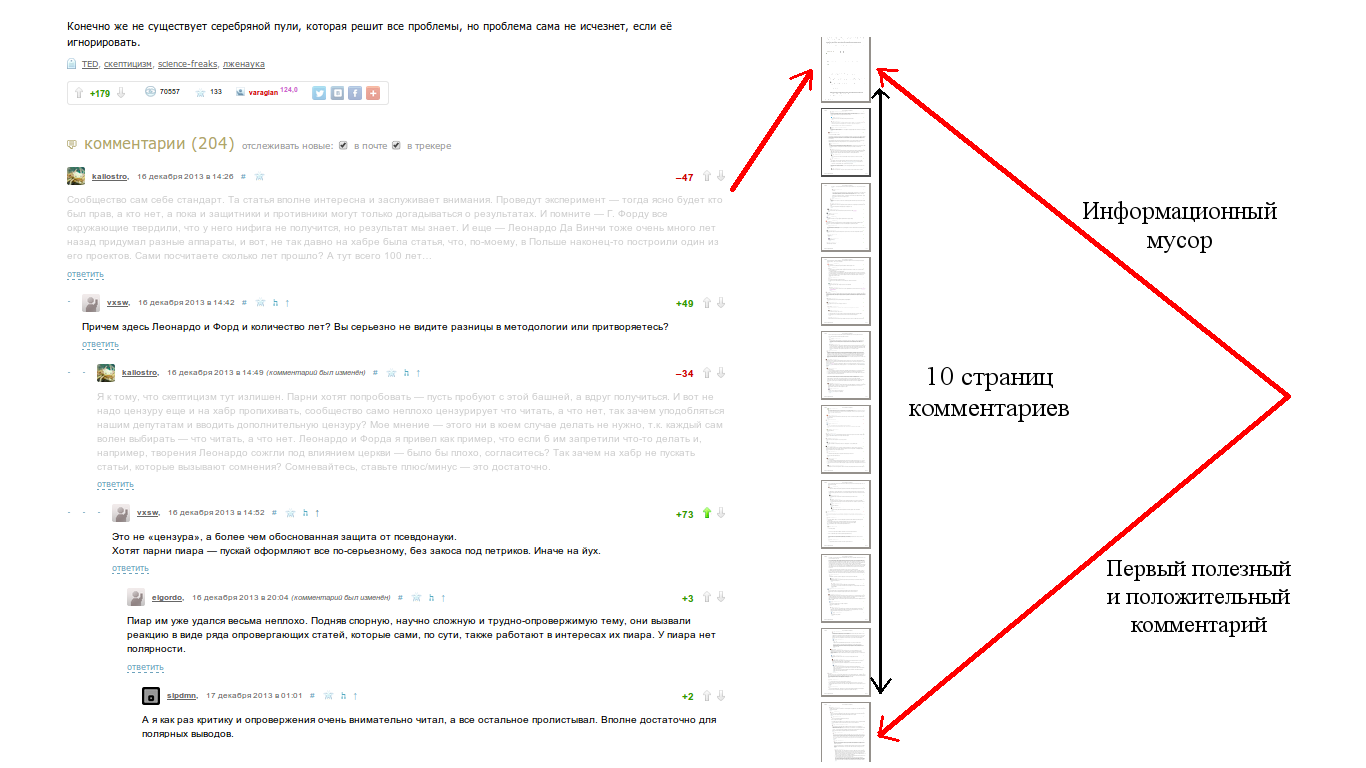
 Доброго времени суток. На днях у меня возникла задача по реализации алгоритма пост-обработки результатов оптического распознавания текста. Для решения этой проблемы не плохо подошла одна из моделей для проверки орфографии в тексте, хотя конечно слегка модифицированная под контекст задачи. Этот пост будет посвящен
Доброго времени суток. На днях у меня возникла задача по реализации алгоритма пост-обработки результатов оптического распознавания текста. Для решения этой проблемы не плохо подошла одна из моделей для проверки орфографии в тексте, хотя конечно слегка модифицированная под контекст задачи. Этот пост будет посвящен