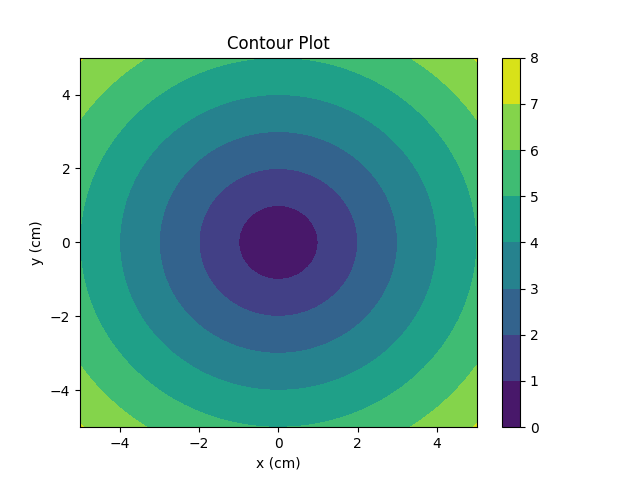
The Python language has two kind of functions — normal functions that you would use in most cases, and async functions. The latter functions are used when performing network IO in an asynchronous manner. The problem with this division is that async functions can only be called from other async functions. Normal functions, on the other hand, can be called from any functions — however, if you call a normal function that does a blocking operation from an async function, it will block the whole event loop and all your coroutines. These limitations usually mean that when writing an using Python`s asyncio, you can`t use any of the IO libraries that you use when writing a synchronous application, and vice versa, unless a library supports usage both in sync and async applications.
Now, the question is, in case you are developing a large and complex library, that, say, allows users to interact with relational databases, abstracting away (some of) the differences between the SQL syntax and other aspects of these databases, and abstracting away the differences between the drivers for that database, how do you support both sync and async usage of your library without duplicating the code of your library? The way sqlalchemy is organized is that regardless of what database and driver for it you are using, you will be calling functions and methods related to Engine, Connection, etc classes, which will do some general work independent of database, then apply the logic specific to your database and finally, call the functions of your database driver to actually communicate with the database. If you are using Python`s asyncio, the database driver will expose async functions and methods, but the rest of the library that is driver‑independent would ideally remain the same. However, the issue is that that you can`t call the async functions of the driver from the normal functions of the core of the library.